


分享嘉宾:邱璐、唐春旭、王北南
当前, 人工智能(AI)和机器学习(ML)领域正在迅速发展,是否能有效处理训练过程中的大型数据集变得越来越关键。Ray已经成为这一领域的重要参与者,通过有效的数据流处理实现了大规模数据集训练。Ray将大型数据集分解成可管理的数据块,并将训练作业划分为较小的任务,无需将整个数据集存储在训练机器的本地。但是,这一创新方法也面临着一定的挑战。
虽然Ray有助于使用大型数据集进行训练,但数据加载仍然是严重的瓶颈。每个epoch都需要从远端存储重新加载整个数据集,这会严重降低GPU的利用率,并且增加存储数据的传输成本,因此,我们需要更优化的方法来管理训练过程中的数据,提升效率。
Ray主要使用内存来存储数据,其内存对象存储针对大型任务数据而设计。但是,这种方法在数据密集型任务上面临瓶颈,因为大型任务所需的数据必须在执行之前预加载到Ray的内存存储中。由于对象存储的大小通常无法容纳训练数据集,因此不适用于跨多个训练epoch缓存数据,这也突显了Ray框架对于更具扩展性的数据管理方案的需求。
Ray的重要优势之一是利用GPU进行训练,同时利用CPU进行数据加载和预处理。该方法可确保Ray集群内GPU、CPU和内存资源的有效利用, 但是这也会导致磁盘资源利用不足,并且缺乏有效管理。一个变革性的想法应运而生:搭建高性能数据访问层,通过智能地跨机器管理低效磁盘资源来缓存和访问训练数据集,这样可以显著提高整体训练性能,并降低访问远端存储的频次。
Alluxio通过巧妙高效地利用GPU和相邻CPU机器上未使用的磁盘容量进行分布式缓存,加速大规模数据集的训练。这一创新方法能显著提高数据加载性能,对于使用大规模数据集的训练至关重要,同时还降低了对远端存储的依赖并减少相关的数据传输成本。
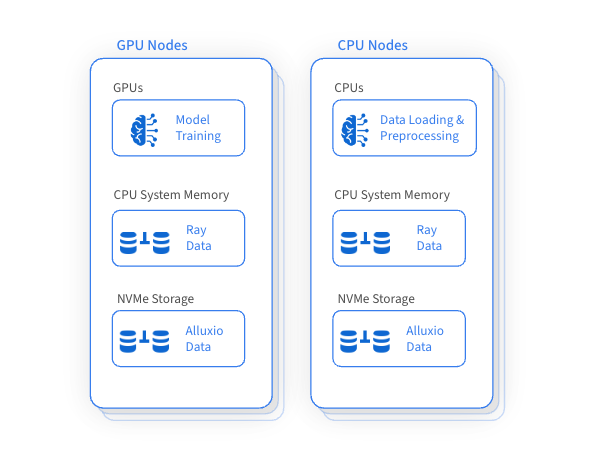
集成Alluxio后提升了Ray的数据管理能力,带来诸多益处:
√
可扩展性
数据访问和缓存可扩展性强
√
加快数据访问速度
可利用高性能磁盘缓存数据
针对Parquet等面向列存储文件格式的高并发随机读进行了优化
零拷贝
√
可靠性和可用性
无单点故障
在故障期间具有强大的远端存储访问能力
√
弹性资源管理
根据工作负载的需求动态分配和释放缓存资源
Ray能有效地编排机器学习工作流,与数据加载、预处理和训练框架无缝集成。Alluxio作为高性能数据访问层,尤其是在需要重复访问远端存储数据的情况下,可大幅优化AI/ML训练和推理任务。
Ray利用PyArrow加载数据并将数据格式转换为Arrow格式,然后由Ray工作流在下一阶段使用。PyArrow将存储连接问题委托(delegate)给fsspec框架,Alluxio作为Ray和底层存储系统(如S3、Azure Blob存储和Hugging Face)的中间缓存层。
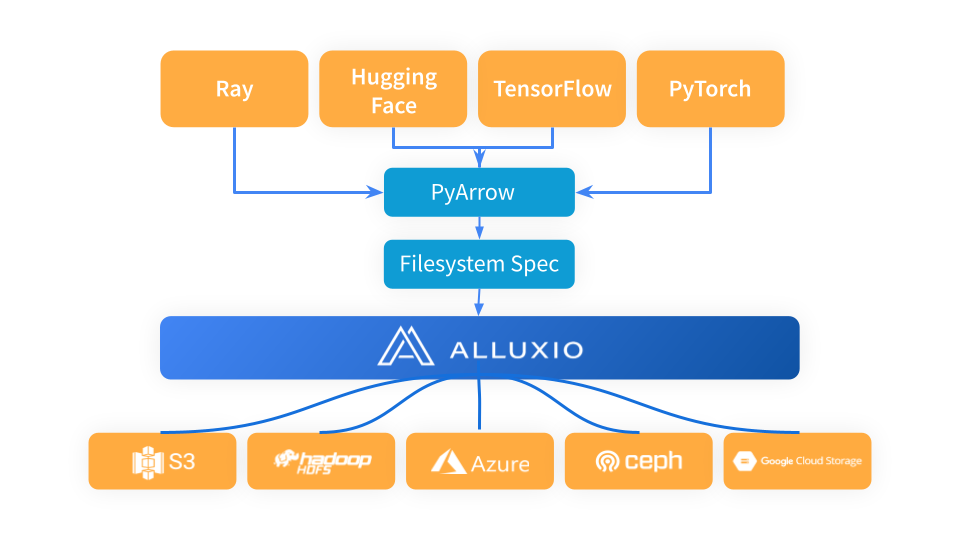
在将Alluxio用作Ray和S3之间的缓存层时,只需导入Alluxiofs,初始化Alluxio文件系统,然后将Ray文件系统更改为Alluxio。
# Import fsspec & alluxio fsspec implementationimport fsspecfrom alluxiofs import AlluxioFileSystemfsspec.register_implementation("alluxio", AlluxioFileSystem)# Create Alluxio filesystem with S3 as the underlying storage systemalluxio = fsspec.filesystem("alluxio", target_protocol=”s3”, etcd_host=args.etcd_host)# Ray read data from Alluxio using S3 URLds = ray.data.read_images("s3://datasets/imagenet-full/train", filesystem=alluxio)
我们使用Ray Data的Ray Data nightly test来对比Alluxio 和同一区域S3在不同训练epoch的数据加载性能。基准测试结果表明,通过将Alluxio与Ray集成可显著降低存储成本并大幅提高吞吐量。

√
提升数据访问性能:我们观察到当Ray的对象存储不受内存压力影响时,Alluxio的吞吐量是同一区域S3的2倍。
√
在内存压力下优势更明显:值得注意的是,当Ray 的对象存储面临内存压力时,Alluxio的性能优势显著增加,其吞吐量比S3高出5倍。
对于Ray任务而言,将未利用的磁盘资源作为分布式缓存的存储有着巨大的战略意义。该方法显著提高了数据加载性能,在跨多个epoch使用相同数据集进行训练或调优的情况下尤其有用。此外,当Ray 面临内存压力时,它能为优化和简化这些场景下的数据管理流程提供实用的解决方案。
✦
【添加小助手,获取更多资料】
✦

✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。