
分享嘉宾:
付庆午-OPPO数据架构组大数据架构师
在OPPO的实际应用中,我们将自研的Shuttle与Alluxio完美结合,使得整个Shuttle Service的性能得到显著提升,基本上实现了性能翻倍的效果。通过这一优化,我们成功降低了约一半的系统压力,同时吞吐量也直接翻倍。这样的结合不仅解决了性能问题,更为OPPO的服务体系注入了新的活力。
完整文字版分享内容↓
分享主题:《Alluxio在Data&AI湖仓一体的实践》
Data&AI 一体数据湖仓架构
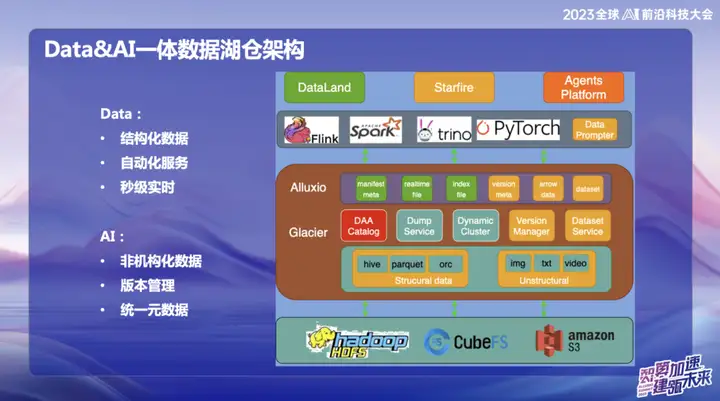
上图是OPPO目前的整体架构,主要分为两部分:
1、Data
2、AI
OPPO在数据领域主要专注于结构化数据,即通常使用SQL处理的数据。在AI领域,主要关注非结构化数据。为实现结构化和非结构化数据的统一管理,OPPO建立了一个名为Data and Catalog的系统,通过这种Catalog元数据的形式进行管理。同时,这也是一个数据湖服务,其中上层数据接入层采用Alluxio分布式缓存。
为什么我们选择使用Alluxio呢?
因为OPPO国内机房规模庞大,计算节点上的内存闲置量相当可观。我们估算平均每天约有1PB的内存处于闲置状态,并且希望通过这种分布式内存管理系统使其充分利用。橙色部分代表非结构化数据的管理,我们的目标是通过数据湖服务,使非结构化数据能够像结构化数据一样方便管理,并为AI训练提供加速。
DAA-Catalog
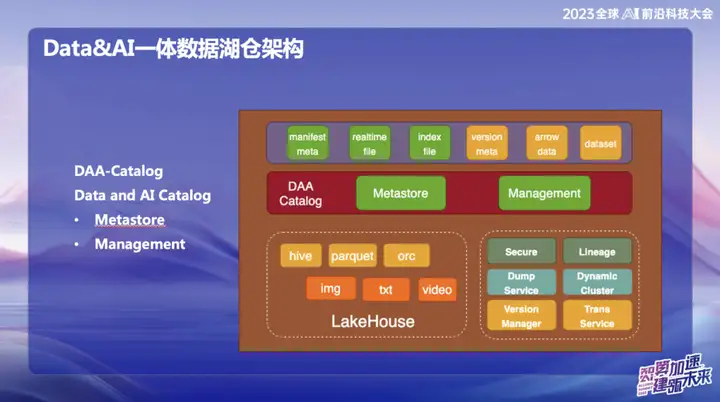
DAA-Catalog,即Data and AI Catalog,是我们团队在数据架构底层追求的目标,我们选择这个名字是因为OPPO致力于与业界最优秀的公司竞争。目前,我们认为在Data&AI领域,Databricks是最杰出的公司之一。无论是技术性、理念的先进性还是商业模式,Databricks都表现出色。
受到Databricks的Unicatalog启发,我们看到Databricks的Service数据和AI训练流程主要围绕Unity Catalog展开。因此,我们决定构建DAA-Catalog,以追求在数据湖仓库领域与业界最佳公司竞争的目标。
具体而言,这一功能分为两个主要模块:
- Metastore(元数据存储):这一部分负责元数据的管理,底层基于Iceberg元数据管理。包括并发提交和生命周期管理。同时,我们使用Down Service进行管理,因为我们的数据首先会进入Alluxio的庞大内存缓存池,并实现每一条记录的实时插入和查询。
- Management(管理):这一部分是DOM服务,为什么选择Down Service呢?因为数据进入后首先存储在Alluxio的内存中,实现了秒级的实时性。整个流程中,数据进来后会自动通过Catalog下沉到Iceberg,元数据基本上都在Alluxio中。
为什么我们要实现这样的秒级实时功能呢?
主要是因为我们之前使用Iceberg时发现一个严重问题,它基本上需要每5分钟做一次Commit,每次Commit都会生成大量小文件,对Flink计算系统和HDFS的元数据都造成了很大的压力。同时,还需要手动清理和合并这些文件。通过Alluxio服务,数据可以直接进入内存,Down Service也通过Catalog进行管理。整个流程中,数据进入后会自动下沉到Iceberg,元数据基本上都在Alluxio中。
由于OPPO与Alluxio有许多合作,我们在2.9版本的基础上做了一些调整,性能得到了大幅提升。在数据湖上实现了流式文件的读写,每一条数据都可以像一个commit一样,而不需要整个文件进行commit。
结构化数据的加速
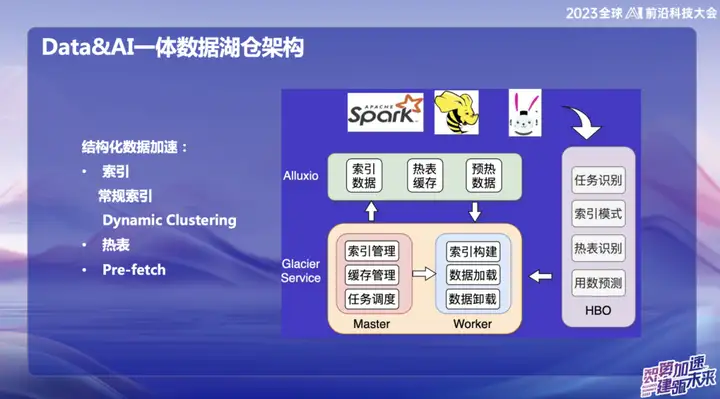
随着大数据的发展,许多基础设施已经相当完善,解决了许多不同场景的问题。然而,我们的关注点是如何更有效地利用闲置资源和内存。因此,我们致力于从两个方面入手:一个是缓存加速,另一个是对热表和索引的优化。
我们提出了一个名为“Dynamic Cluster”的概念,它是一个动态聚合数据的功能,灵感来自于Databricks的一项技术。尽管内部也使用了Hallway曲线,但我们在其基础上实现了“the order”和“增量 the order”排序算法,将它们融合在一起形成了Dynamic Cluster。这一创新可以在数据录入后动态地聚合数据以提升查询效率。与Hallway曲线相比,“the order”算法的效率更高,但Hallway曲线在实时变动方面的表现更为优越。这种融合为我们提供了更灵活、高效的查询和聚合数据的方式。
非结构化数据管理
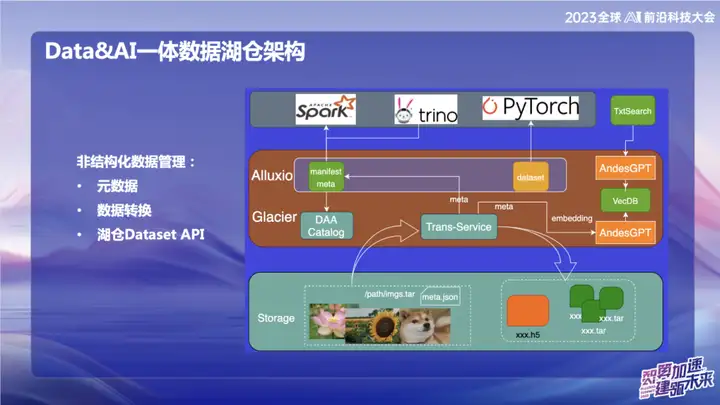
上图展示了我们在非结构化数据领域的一些工作,主要涉及到AI领域。在OPPO内部,AI训练一开始使用的工具相对较老旧,通常是通过脚本直接读取数据,或者将数据以裸的txt文件、裸的image文件形式存放在对象存储上。借助Transfer服务,我们能够将数据自动导入数据湖,并将打包好的图片数据切割成update set的格式。在AI领域,尤其是在处理图片领域,update set是一个高效的数据集接口,它不仅兼容web数据集接口,还可以转换成H5格式。
我们的目标是通过对元数据的处理将非结构化数据管理变得像结构化数据一样便捷。在数据转换的过程中,将非结构化数据的元数据写入Catalog中。同时,我们与大模型结合,将元数据的一些信息写入向量数据库,以便更轻松地使用大模型或自然语言查询湖仓中的数据。这一整合工作的目标是提高对非结构化数据的管理效率,使得其更加符合结构化数据的管理方式。
非结构化数据 - 元数据管理示例
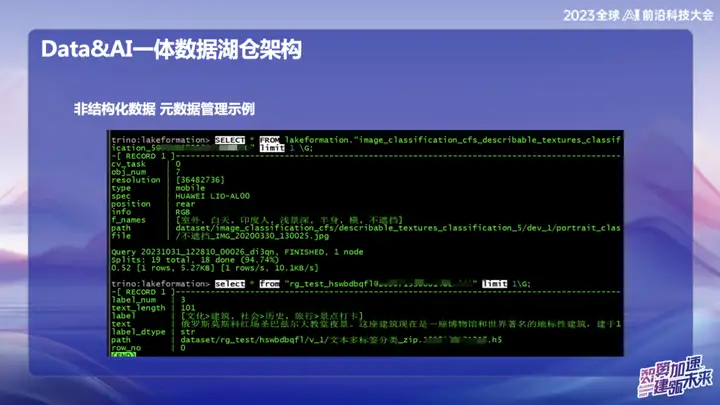
上图是OPPO非结构化数据管理的一个实例,实现可以像SQL一样去搜索文本、图片的位置。
DataPrompter
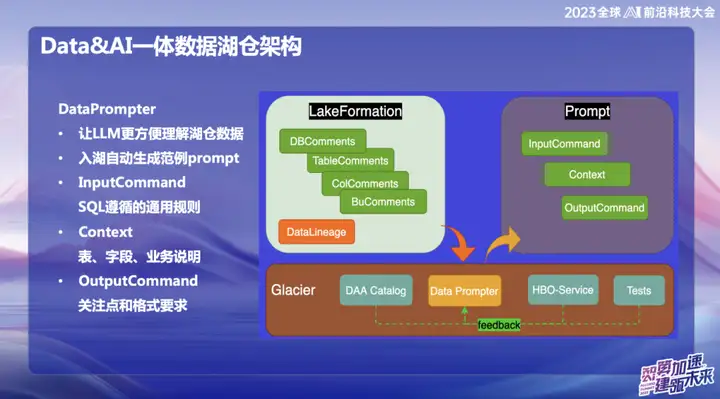
选择构建DataPrompter的初衷源自对更好地运用大模型的追求。OPPO致力于将数据与大模型结合的领域,推出了一个名为Data Chart的产品,通过内部聊天软件,用户可以轻松查询所有数据。例如,用户可以方便地查询昨天手机的销量,或者比较与小米手机销量的差异,通过自然语言进行数据分析。
在产品构建过程中,每个领域的数据表需要专业的业务人员输入Prompter。这对整个数据湖仓或产品的推广带来了挑战,因为每一张表的Prompter都需要花费相当长的时间。例如,想要输入财务表数据,需要详细填写表的字段、业务域含义、展开维表等专业且技巧性的信息。
我们的最终目标是使得数据进入湖仓后,大模型能够轻松理解上层数据。在数据入湖的过程中,业务需展示一些规定的信息,并结合我们在Data Prompter方面积累的经验,利用HBO Service提供的一些常用查询,最终生成一个使大模型容易理解的Prompter范本。这样的结合旨在让模型更好地理解业务数据,使湖仓与大模型的结合更为顺畅。
Alluxio助力秒级实时入湖
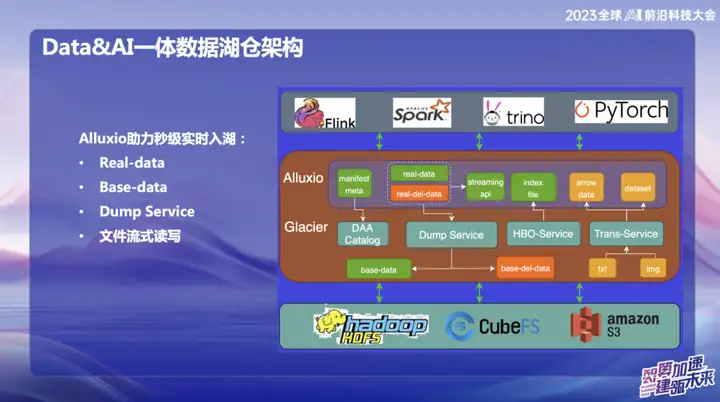
Alluxio助力秒级实时入湖,主要分为:
1、Real-data
2、Base-data
3、Dump Service
4、文件流式读写
Alluxio在湖仓架构中的实践
Alluxio与Spark RSS结合
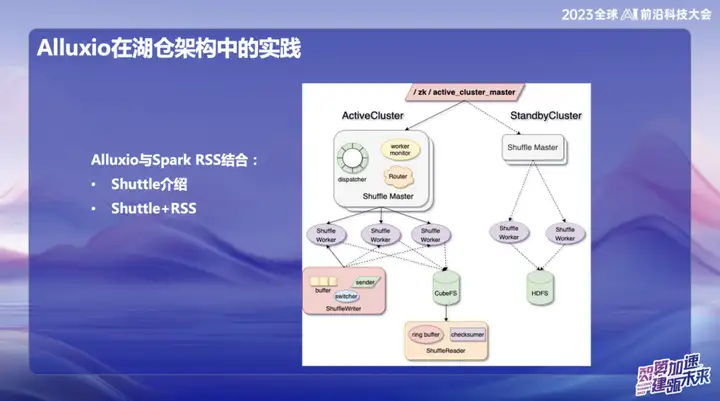
我们最初选择将Alluxio与Spark RSS服务结合,通过自研的Spark Shuttle Service并以Shuttle的名义开源。起初,我们的底层基于分布式文件系统,但随后在性能方面遇到了一些问题,于是我们找到了Alluxio。
Shuttle与Alluxio的完美结合使得整个Shuttle Service的性能得到了显著提升,基本上实现了性能翻倍的效果。通过这一优化,我们成功降低了约一半的系统压力,同时吞吐量也直接翻倍。这次的结合不仅解决了性能问题,更为我们的服务体系注入了新的活力。
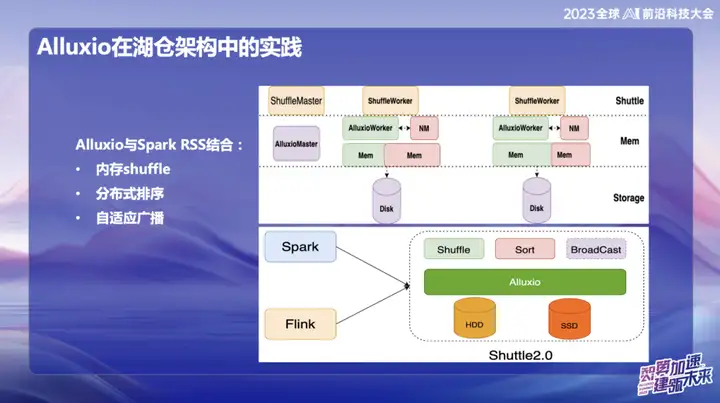
在OPPO的后续研发中,基于Alluxio+Shuttle的框架实现了更多创新。我们将Shuttle算子和广播算子都优化到内存数据层面,通过高效的内存数据交互,特别是在处理单点Reduce时,当数据倾斜的情况下,原本耗时长达50分钟的排序操作,迁移到新方案后,成功将处理时间降低到了10分钟以内。这一优化不仅大大提高了处理效率,也有效缓解了数据倾斜对系统性能的影响。
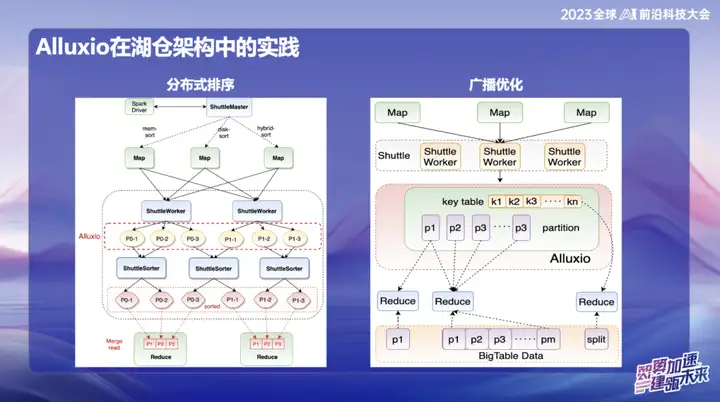
广播成果非常显著,特别是在Spark中,默认广播大小为10M,因为所有的广播数据都必须在Java端存放,在经过Java序列化后容易发生膨胀,进而引发OOM(Out of Memory)问题,这在线上环境中经常发生。
为了解决这个问题,我们目前将广播数据存放到Alluxio中。这样一来,几乎可以广播任意大小的数据,最大可达10个G。这一创新在OPPO线上已经有多个案例成功实施,对提升效率产生了显著的影响。
Alluxio在公有云/混合云上的应用实践
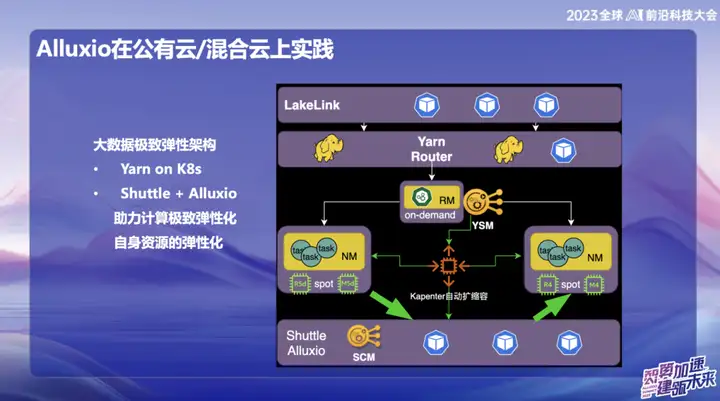
在OPPO的公有云大数据体系中,特别是在新加坡地区,我们主要采用AWS作为基础架构。在早期阶段,我们使用了AWS提供的弹性计算服务(EMR)。然而,近年来,行业整体经济形势不太乐观,许多企业都在追求降低成本和提高效率。面对这一趋势,我们在海外公有云领域提出了自研的解决方案,利用云上的弹性资源搭建一套新的架构。这一创新方案的核心是依赖于Alluxio+Shuttle的组合,为我们的大数据体系提供了关键的支持。

Alluxio+Shuttle解决方案的显著优势在于,Alluxio集群并非被Shuttle独占,它可以为其他服务提供支持,包括数据缓存和元数据缓存。在公有云中,我们深知S3上的List操作在提交时非常耗时,通过结合Alluxio和开源的Magic commit、 Shuttle的方案,我们取得了显著的降本效果,大约降低了计算成本的80%。
在混合云环境中,我们为AI团队提供服务。由于数据湖底层有对象存储,我们在训练过程中利用了阿里云上的GPU卡,同时也结合了自建的GPU资源。由于专线带宽有限且成本较高,数据拷贝时需要一个有效的缓存层。最初,我们采用了存储团队提供的解决方案,但其扩展性和性能并不理想。引入Alluxio后,我们在多个场景中实现了数倍的IO加速,为数据处理提供了更高效的支持。
展望

OPPO的集群规模在国内已经达到上万台,形成了相当庞大的规模。我们计划在未来深入挖掘内存资源,以更充分地利用内部的存储空间。团队内部同时拥有实时计算框架Flink和离线处理框架Spark,这两者可以相互借鉴Alluxio的应用经验,实现Alluxio与数据湖的深度融合开发。
在大数据和机器学习结合的浪潮中,我们紧跟行业趋势。将数据架构从底层与人工智能(AI)深度结合,为AI提供优质的服务作为首要任务。这一融合不仅是技术上的进步,更是对未来发展的战略规划。
最后,我们将进一步挖掘Alluxio的优势,助力我们在公有云环境中降低成本。这不仅涉及技术上的优化,也包括对云计算资源的更有效管理,为公司的可持续发展提供坚实支持。
《庆余年2》盗版资源被上传到 npm,导致 npmmirror 不得已暂停 unpkg 服务 周鸿祎:留给谷歌的时间不多了,建议把所有的产品都开源 请教各位,此处的 time.sleep(6) 起到了什么作用? Linus “吃狗粮”最积极! 新款 iPad Pro 使用了 12GB 内存颗粒,但却声称是 8GB 内存 人民网评办公软件套娃式收费:积极解“套”,才有未来 Flutter 3.22 和 Dart 3.4 发布 Vue3 开发新范式,不用`ref/reactive`,不用`ref.value` MySQL 8.4 LTS 中文手册发布:助力您掌握数据库管理新境界 通义千问 GPT-4 级主力模型降价 97%,1 块钱 200 万 tokens