

本文作者:
Tarik Bennett, Beinan Wang, Hope Wang
本文将围绕人工智能(AI)中的数据访问挑战展开讨论,同时揭秘“常用的NAS/NFS或许并非最佳选择”。
一、早期人工智能/机器学习架构
Gartner研究显示,尽管当下大语言模型(LLM)备受瞩目,但大多数组织对于大模型的使用仍处于早期阶段,只有部分已经进入生产阶段。
早期构建AI平台的重点在于让系统运行起来,从而能够进行项目试点和概念验证。这些早期架构或者称为预生产架构,旨在满足模型训练和部署的基本需求。目前,许多组织已经将这类早期AI架构用于生产环境。
随着数据和模型的增长,这类早期AI架构通常会变得效率低下。企业在云上训练模型,随着项目扩容,预计其数据和云使用量在12个月内也会大幅增加。许多企业在一开始的数据量都能匹配当前内存大小,但也清楚地知道要为处理更大的负载做好准备。
企业可能选择使用现有技术栈或绿场部署。本文将重点介绍如何使用现有技术栈或购买一些额外的硬件来设计更具扩展性、敏捷性和高性能的技术栈。
二、数据访问方面的挑战
随着 AI/ML 架构的演进,模型训练数据集的规模在继续大幅增长,GPU的算力和规模也在迅速提高。除了计算、存储和网络之外,我们认为数据访问是搭建前瞻型AI平台的另一个关键要素。

数据访问是指数据服务、备用存储(NFS、NAS)和高性能缓存(例如 Alluxio)等有助于计算引擎获取数据用于模型训练和部署的技术。
数据访问的重点在于吞吐量和数据加载效率,这对于GPU资源稀缺的AI/ML架构愈发重要 - 优化数据加载可以大大降低 GPU空闲等待时间并提高 GPU利用率。因此,高性能数据访问应该成为架构部署的首要目标。
随着企业在早期AI架构上扩展模型训练任务,就出现了以下一些常见的数据访问挑战:
1
模型训练效率低于预期:由于数据访问瓶颈,训练时间比根据算力资源预估的时间要长。低吞吐数据流无法为 GPU 提供充足的数据。
2
数据同步相关的瓶颈:手动将数据从存储拷贝或同步到本地 GPU 服务器时,会在构建要准备的数据队列时产生延迟。
3
并发和元数据问题:当大型作业并行启动时,共享存储会出现争用。后端存储的元数据操作缓慢时会增加延迟。
4
性能缓慢或GPU 利用率低:高性能 GPU 基础设施投资巨大,一旦数据访问低效,就会导致GPU资源闲置和利用不足。
除此以外,数据团队需管理的一系列其他问题也会加剧上述挑战。这些问题包括存储的I/O速度慢,无法满足高性能 GPU 集群的需求。当数据团队等待数据被输送到 GPU 服务器时,依靠手动进行数据拷贝和同步会增加延迟。混合基础设施或多云环境中的多个数据孤岛带来的架构复杂性也加剧了数据访问这一难题。
这些问题最终导致架构的端到端效率达不到预期。
与数据访问相关的挑战通常有两种常见的解决方案。
购买更高速的存储:许多企业尝试通过部署更快的存储选项来解决数据访问速度慢的问题。云厂商提供高性能存储,而专业硬件厂商则售卖 HPC 存储,借此达到提高性能的目的。
在对象存储上添加NAS/NFS:添加集中式 NAS 或 NFS 作为 S3、MinIO 或 Ceph 等对象存储的备用存储是一种常见做法,可帮助团队将数据整合到共享文件系统中,简化用户和工作负载之间的协作和共享。此外,还可利用成熟的NAS厂商提供的数据一致性、可用性、备份和可扩展性等相关数据管理功能。
但是,以上这两种常见的解决方案可能无法真正解决您的问题。
虽然更快的存储和集中式NFS/NAS能够逐步实现一些性能提升,但也存在弊端。
1
更快的存储意味着数据迁移,易产生数据可靠性问题
要利用专用存储提供的高性能,数据必须从现有存储迁移到新的高性能存储层。这会导致数据在后台迁移。迁移大量数据集可能会导致传输时间延长以及迁移期间数据损坏或丢失等数据可靠性问题。当团队等待数据同步完成这段时间内,暂停操作既会中断服务又会减慢项目进度。
2
NFS/NAS: 维护及瓶颈
作为附加的存储层,NFS/NAS的维护、稳定性和可扩展性方面的挑战仍然存在。将数据从NFS/NAS手动拷贝到本地GPU服务器会增加延迟,以及重复备份而引起的资源浪费。并行作业引发的读取需求激增可能会使NFS/NAS服务器和相互连接的服务集群。此外,远端NFS/NAS GPU集群的数据同步问题依然存在。
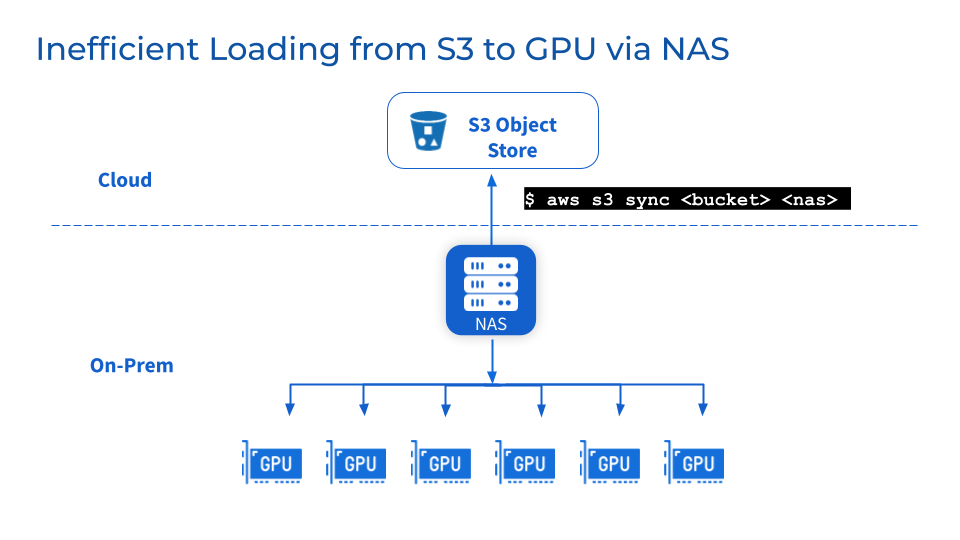
3
如果因业务原因需要更换供应商怎么办?
由于成本优化或合同原因,企业可能会更换供应商。多云环境的灵活性要求能够轻松移植大量数据集,且不被供应商锁定。然而,移动PB级数据存储可能会导致模型开发出现严重停机和中断。
简而言之,现有解决方案虽然在短期内有所帮助,但无法提供可扩展且优化的数据访问架构,实现满足AI/ML指数级增长的数据需求。
三、Alluxio 提供的解决方案
Alluxio 可以部署在计算和数据源之间。提供数据抽象和分布式缓存,提高AI/ML架构的性能和可扩展性。
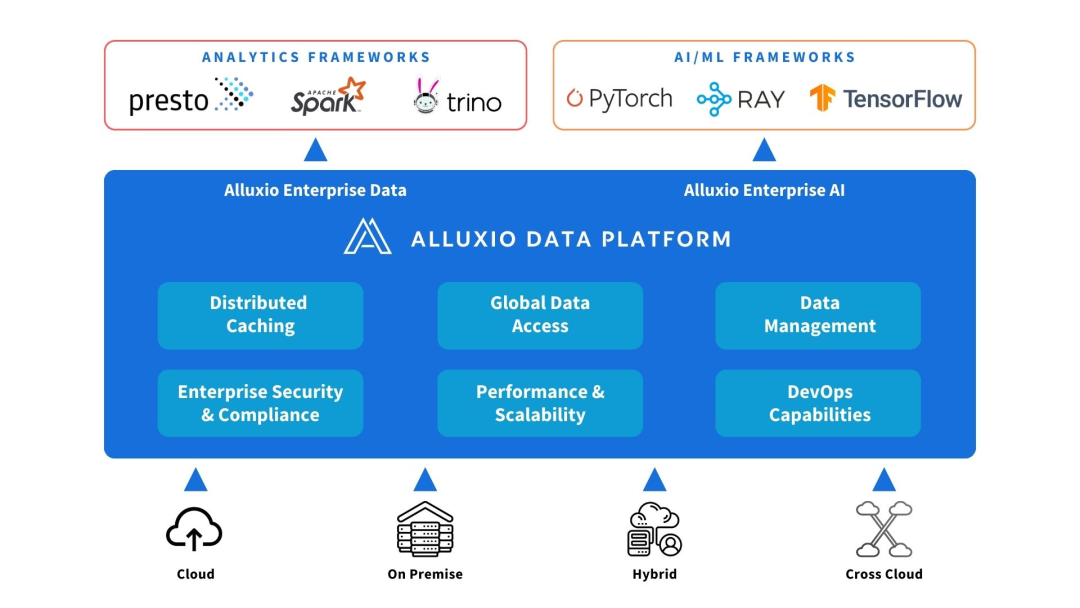
Alluxio有助于解决早期 AI 架构随着数据量、模型复杂性增加以及GPU集群扩容,在可扩展性、性能和数据管理方面面临的挑战。
1
增加容量
Alluxio扩展可超越单个节点限制,能存放集群内存或本地 SSD无法容纳的较大训练数据集。它将不同的存储系统连接起来,提供统一的数据访问层,来挂载PB级数据湖。Alluxio 智能地将常用文件和元数据缓存在靠近计算的内存和SSD层中,无需拷贝整个数据集。
2
减少数据管理
Alluxio 通过自动的分布式缓存简化了GPU集群之间的数据移动和存放。数据团队无需手动将数据复制或同步到本地暂存文件。Alluxio集群可以自动把热文件或者对象抓取到离计算节点近的位置,而不用通过复杂的工作流操作。即使在每个节点有5000万甚至更多对象的情况下,Alluxio也可简化工作流。
3
提升性能
Alluxio 专为加速工作负载而构建,可消除传统存储中限制GPU吞吐量的 I/O 瓶颈。分布式缓存将数据的访问速度提高了几个数量级。相较通过网络访问远端存储,Alluxio提供内存和SSD级别的本地数据访问,从而提高GPU利用率。
总之,Alluxio提供了一个高性能且可扩展的数据访问层,可在AI/ML数据扩展的场景下最大限度地利用 GPU 资源。
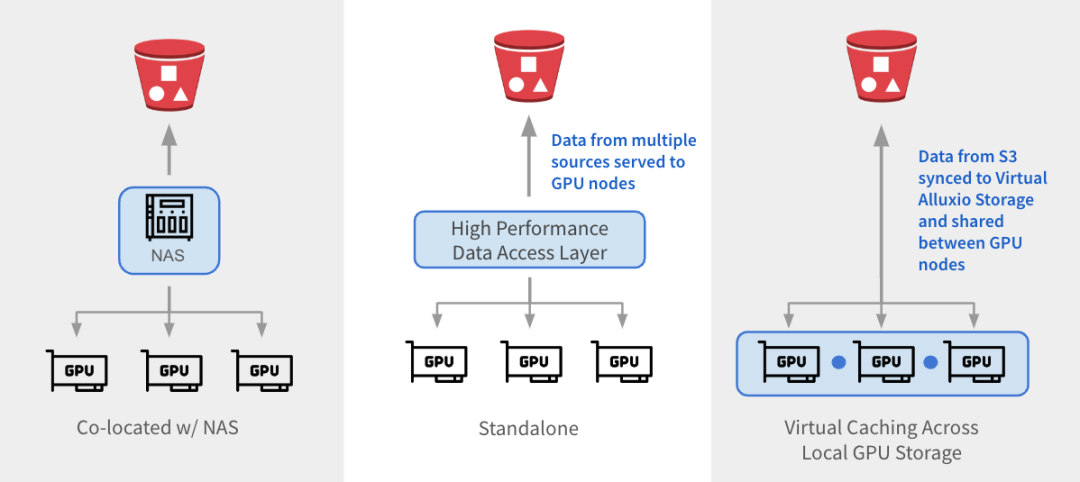
Alluxio 可以通过三种方式与现有架构集成。
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
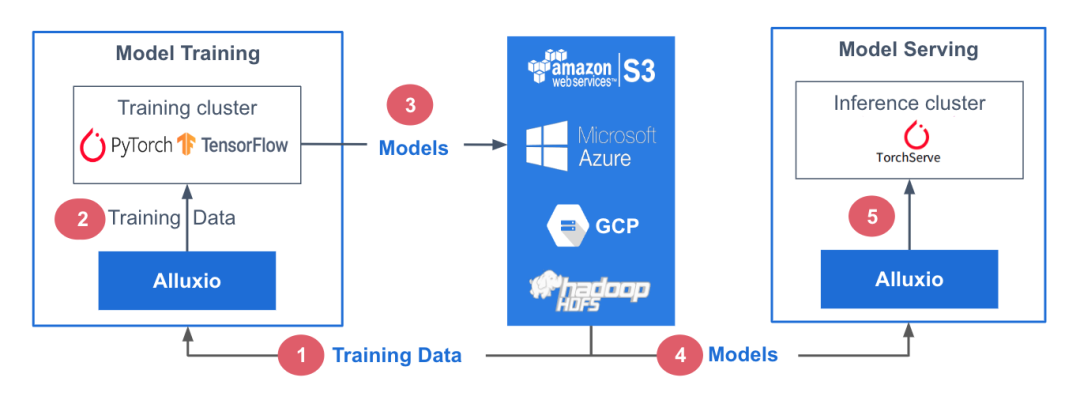
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
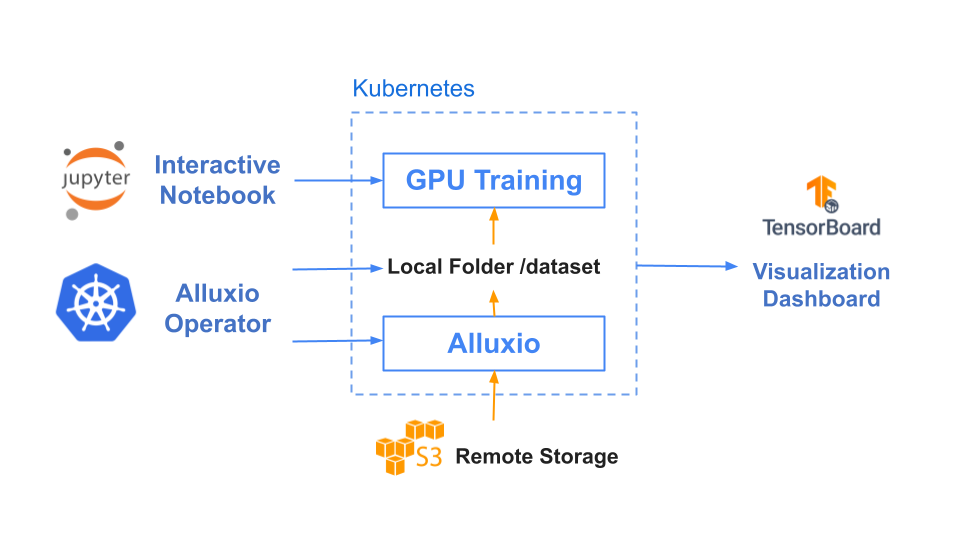
2
基准测试结果
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
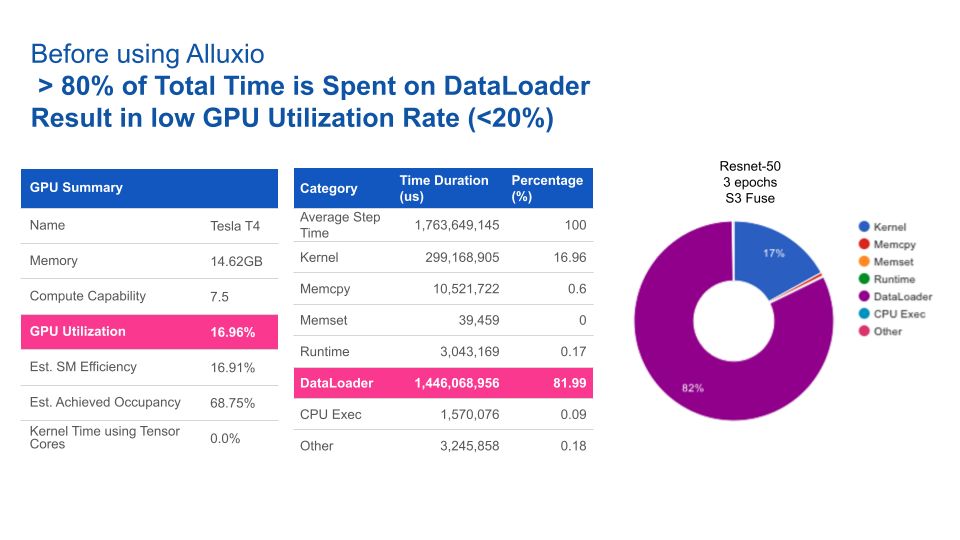
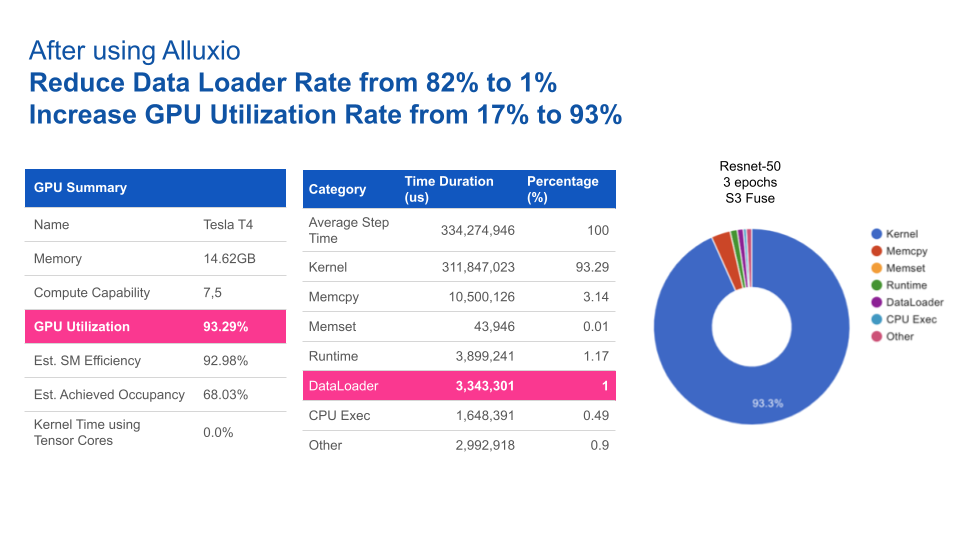
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。