文章目录
背景
在使用Langchain-Chatchat做RAG的时候,发现导入的pdf文件中的表格关系无法保存,导致LLM的回答不符合预期。例如我想问的内容在表格中,但LLM的回答并不是对表格的总结。
那么想要解决这个问题,就需要找到一种合适的文本格式来保留表格间的关系,然后修改Langchain-Chatchat的文本加载源码,使pdf文本转换成目标的文本格式,也就是本篇的markdown格式。
开发环境
- RAG框架: Langchain-Chatchat
- 大模型: Qwen1.5-14B-Chat
- 资源要求: GPU显存
- 14B双精度约等于14*2,加上embeding模型,大约30G的显存
- CPU>8核即可
- Prompt: 使用Langchain-Chatchat为知识库配置的默认Prompt。
loader文本解析步骤
Langchain-Chatchat默认对pdf文件使用的loader是mypdfloader.py,解析文档的流程如下:
- 调用server/api.py中的/knowledge_base/upload_docs 上传文档
- 通过KnowledgeFile这个类来实现文档解析,文档分词等功能
- 调用mypdfloader.py加载pdf文件,使用pyMuPDF包的fitz解析pdf文档
- 获取pdf中的text内容
- 针对图片使用ocr模块进行解析,获取图片中的文本
- text和图片文本连接到一起,作为文档的内容
- 调用unstructured.partition.text import partition_text 进行文本段落划分
- 使用默认的ChineseRecursiveTextSplitter进行分词,存储到向量库
出问题的地方就在于加载pdf文件的部分,把表格作为普通的文本加载,自然就保存不了表格的关系了。
markdown格式的文本
为什么选择markdown格式
- markdown可以支持"基于文档的分块"
- 提取出markdown格式,支持保留表格的行,列关系
- 结构化的内容更有利于LLM大模型理解和上下文保存
在 LLM 和 RAG 环境中使用 Markdown 文本格式可确保更准确和相关的结果,因为它为 LLM 提供了更丰富的数据结构和更相关的数据块加载。
测试markdown格式提取表格
相比于text格式的分词来说,markdown格式的分词可以保留表格的数据和关系
,例如下面的表格。
原pdf表格
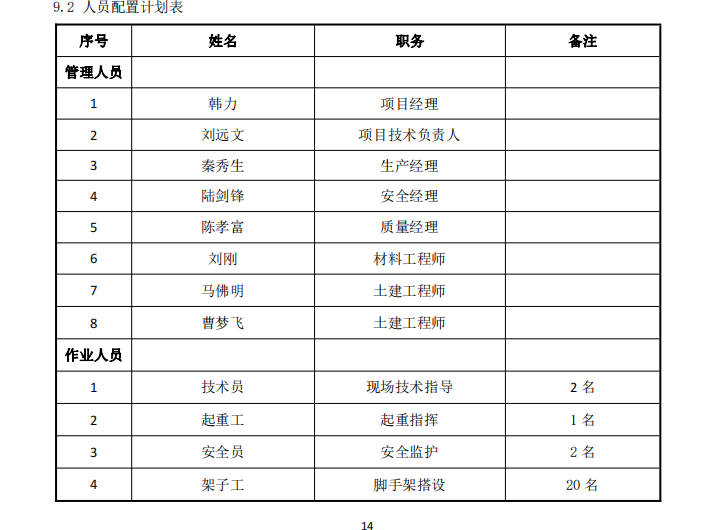
markdown格式的表格
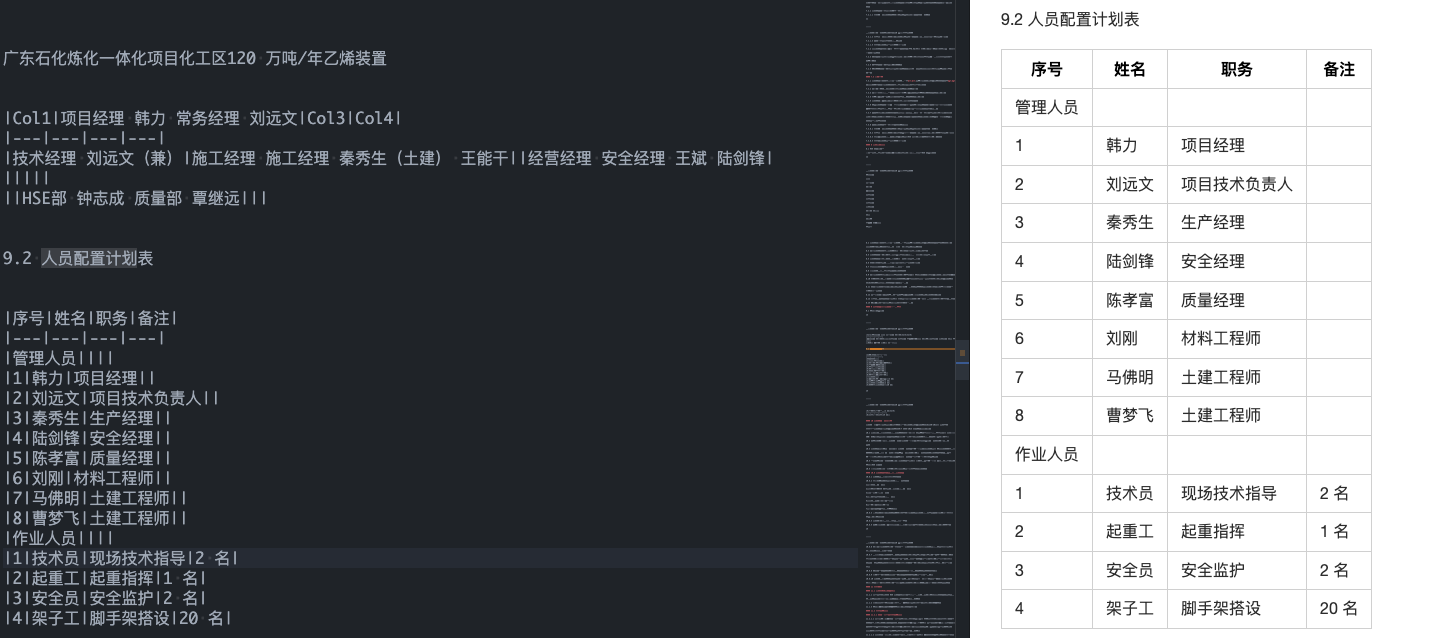
可以看到表格关系都保留下来了。
测试markdown格式的知识库
运行项目
参考官方的开发环境搭建 即可。因为使用的是大模型是Qwen1.5-14B-Chat,因此需要更改模型配置文件的路径,读取Qwen1.5-14B-Chat。
# model_config.py
MODEL_ROOT_PATH = "你的本地模型地址path"
LLM_MODELS = ["Qwen1.5-14B-Chat"]
MODEL_PATH = {
"llm_model":{
"Qwen1.5-14B-Chat": "modelPath/Qwen1.5-14B-Chat",
}
}
# server_config.py
FSCHAT_MODEL_WORKERS = {
# 给Qwen-14b不同的启动端口,不然会默认使用default
"Qwen1.5-14B-Chat": {
"host": DEFAULT_BIND_HOST,
"port": 21012,
"device": LLM_DEVICE,
"infer_turbo": False,
# model_worker多卡加载需要配置的参数
"gpus": "0,1,2,3", # 使用的GPU,以str的格式指定,如"0,1",如失效请使用CUDA_VISIBLE_DEVICES="0,1"等形式指定
"num_gpus": 4, # 使用GPU的数量
},
}
修改文件加载器loader
- 使用pdf4llm读取文件: https://pymupdf.readthedocs.io/en/latest/rag.html
- 修改document_loaders/mypdfloader.py
import pdf4llm
def pdf2markdown_text(filepath):
doc = pdf4llm.to_markdown(filepath, pages=None)
return doc
# pdf转markdown
from unstructured.partition.md import partition_md
text = pdf2markdown_text(self.file_path)
# 这里使用partition_md的分段
return partition_md(text=text, **self.unstructured_kwargs)
- 使用默认的ChineseRecursiveTextSplitter分词器
- web端页面新建知识库,导入pdf文件即可
- 测试表格问答效果
- 脚手架的搭设高度以及对应的安全等级
- pdf文档
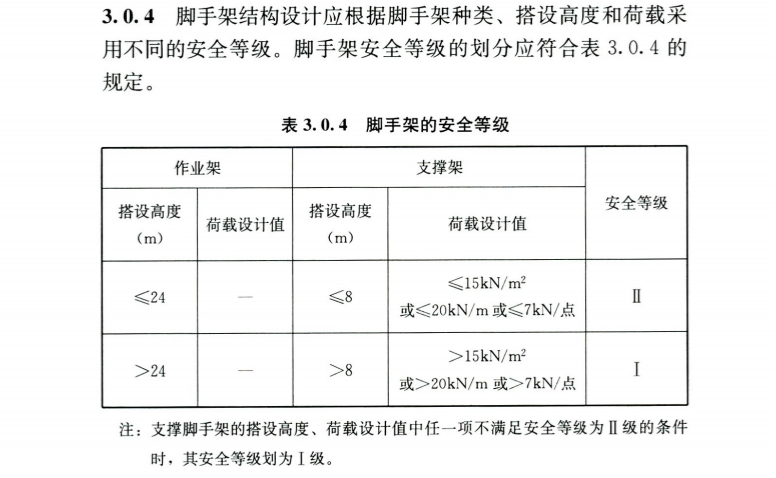
- 大模型回答

- 可以看到保留了表格的关系,大模型做的总结是正确的。
其他问题
运行项目报错
raise OSError(errno.ENOSPC, "inotify watch limit reached")
OSError: [Errno 28] inotify watch limit reached
streamlit可能需要开启大量的inotify实例来监视文件系统的改动,因此可以手动增加max_user_watches的值来解决。
一般程序监视某个或某些目录的文件是否被创建、修改、删除等等就需要启动inotify实例,但是每一个inotify实例都需要消耗一定量的内存。
查看系统当前的max_user_watches
# 查看当前系统中的max_user_instances数量
cat /proc/sys/fs/inotify/max_user_instances
max_user_instances 控制着一个单一用户(或者用户ID,UID)可以创建的 inotify 实例的最大数量。
# 查看当前系统中的max_user_watches数量
cat /proc/sys/fs/inotify/max_user_watches
max_user_watches 控制着一个用户可以添加到所有 inotify 实例中的监视项(watches)的总数。
# 增大max_user_instances的值 (修改成10240还是启动不了,得修改成102400)
sudo sysctl -w fs.inotify.max_user_watches=102400
修改sysctl.conf配置
# 目前把这一行配置给加到/etc/sysctl.conf中去了,设置成102400
fs.inotify.max_user_watches=102400
# 执行一次sysctl.conf配置
sudo sysctl -p /etc/sysctl.conf
# 这样的好处是不需要重新启动系统即可应用更改,并且在每次系统启动时会自动将此值设置为 102400。
图片提取问题
经过测试,有的图片内容能提取出来,有的提取不出来 – 建议还是加一个图片提取函数
- 图片中的逻辑关系会丢失,例如:
- 因为ppt排版中有文字和图片,会丢失一些逻辑关系,例如:文字1 图片1 ,在解析的时候会分别加载,失去了文字1 和图片1的逻辑关系
怎么提取图片内容
- 目前pdf4llm不支持图片的读取
- 可以看到在langchain中的使用,是文字提取+图片提取
- 参考:https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/document_loaders/parsers/pdf.py#L218
- _extract_images_from_page 函数
- 也是使用的OCR模块
- 不同的地方在于,langchain的pdfloader是text+img的方式。不是我们想要的markdown的方式,可以再添加一个提取图片的函数来完善markdown文件。
使用Milvus向量库报错
AssertionError: A list of valid ids are required when auto_id is False.
或
milvus error: KeyError: 'pk'
参考:https://github.com/langchain-ai/langchain/issues/17172
原因是Langchain-Chatchat中milvus的默认配置是auto_id=False,也就是说需要自己提供主键。但是在代码中没有发现有添加主键的部分,因此导入到milvus会报错。
修复方法也比较简单,直接在初始化Milvus的时候设置auto_id=True即可,如下:
def _load_milvus(self):
self.milvus = Milvus(embedding_function=EmbeddingsFunAdapter(self.embed_model),
collection_name=self.kb_name,
connection_args=kbs_config.get("milvus"),
auto_id=True,
index_params=kbs_config.get("milvus_kwargs")["index_params"],
search_params=kbs_config.get("milvus_kwargs")["search_params"]
)
end