
近年来,向量搜索领域经历了爆炸性增长,尤其是在大型语言模型(LLMs)问世后。学术界开始重点关注如何通过扩展训练数据、采用先进的训练方法和新的架构等方法来增强 embedding 向量模型。
在之前的文章中,我们已经深入探讨了各种类型的 embedding 向量和专为高效信息检索而设计的模型,包括针对具体用例设计的稠密、稀疏和二进制 embedding 向量,它们各自的优势和劣势。此外,我们还介绍了各种 Embedding 向量模型,如用于稠密向量生成和检索的 BERT,以及用于稀疏向量生成和检索的 SPLADE 和BGE-M3。
本文将深度剖析 ColBERT——专为高效相似性搜索而设计的创新型 embedding 和排序(ranking)模型。
01.简要回顾 BERT
ColBERT,是对 BERT 的延伸。让我们先简要回顾一下 BERT。这将帮助我们理解 ColBERT 所做出的改进。
BERT 全称为 Bidirectional Encoder Representations from Transformers,是一种基于 Transformer 架构的语言模型,在稠密向量和检索模型方面表现出色。与传统的顺序自然语言处理方法不同,BERT 从句子的左侧到右侧或相反方向进行移动,通过同时分析整个单词序列结合单词上下文信息,从而生成稠密向量。那么,BERT 是如何生成 embedding 向量的呢?
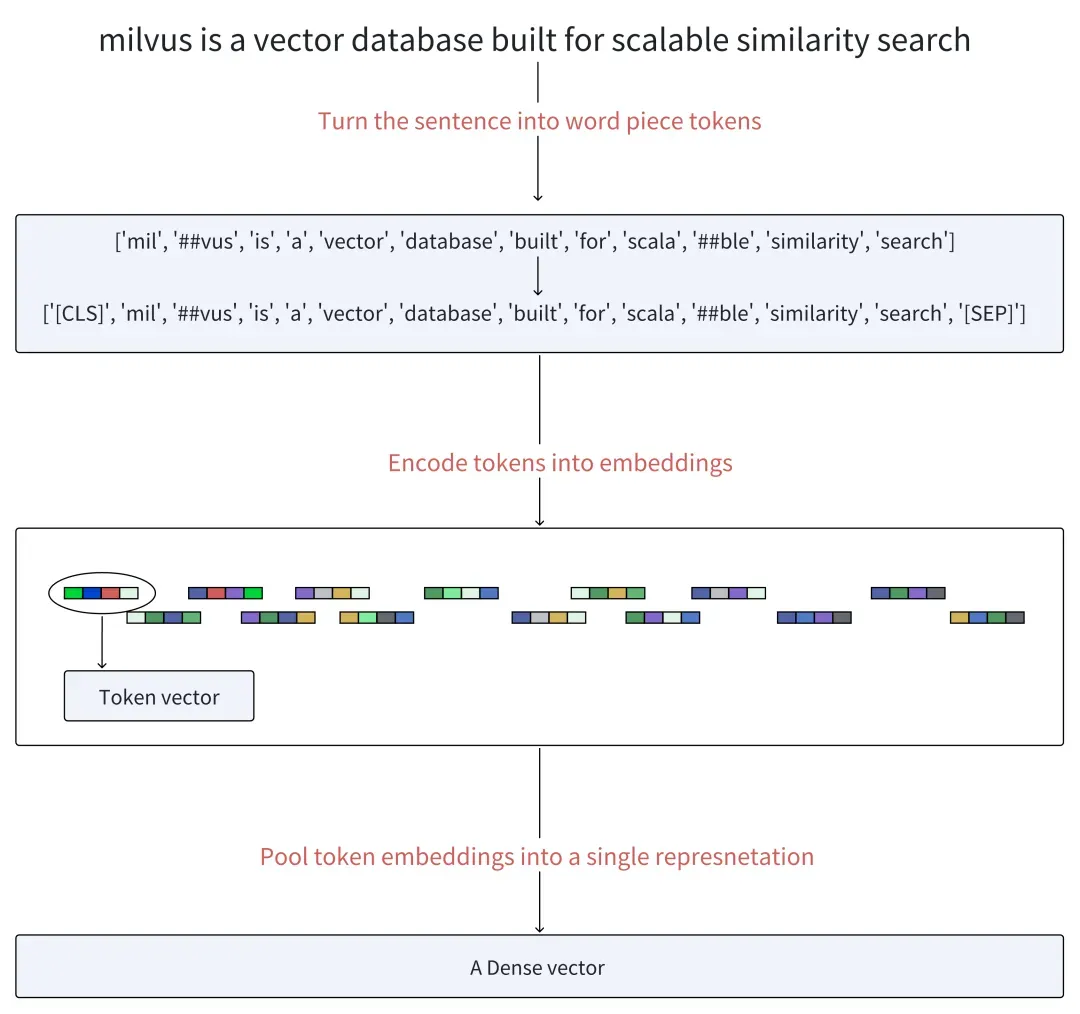
首先,BERT 将句子转换为单词片段(也称为 token)。然后,在生成的 token 序列的开头添加一个特殊的token[CLS],在末尾添加一个 token[SEP],以分隔句子并指示结束。
接下来是 embedding 和 基于transformer的encoding。BERT 通过 embedding 矩阵将token变为向量,并且通过多层编码器将其进行深层次的编码。这些层根据序列中所有其他token提供的上下文信息,对每个token的表示进行基于注意力机制的细化。
最后,使用池化操作将所有 token 向量转化成单一的稠密向量。
02.什么是 ColBERT
ColBERT全称为Contextualized Late Interaction over BERT,基于传统的BERT模型进行了深度创新。BERT将token向量合并为单一表示(即向量),而ColBERT保留了每个token的表示,提供了更细粒度的相似性计算。ColBERT的独特之处在于引入了一种新颖的后期交互机制,可以通过在检索过程的最终阶段之前分别处理查询和文档,实现高效和精确的排名和检索。我们在下文中将详细介绍这种机制。
本质上,虽然BERT或其他传统的embedding模型为每个文档生成一个单一向量,并产生一个单一的数值分数,反映其与查询句的相关性。而ColBERT提供了一个向量列表,进行查询中的每个token与文档中的每个token的相关性计算。这种方法帮助我们更详细和更细致的理解查询和文档之间的语义关系。
03.ColBERT 架构
下图展示了ColBERT的架构,包括:
-
一个查询编码器
-
一个文档编码器
-
后期交互机制
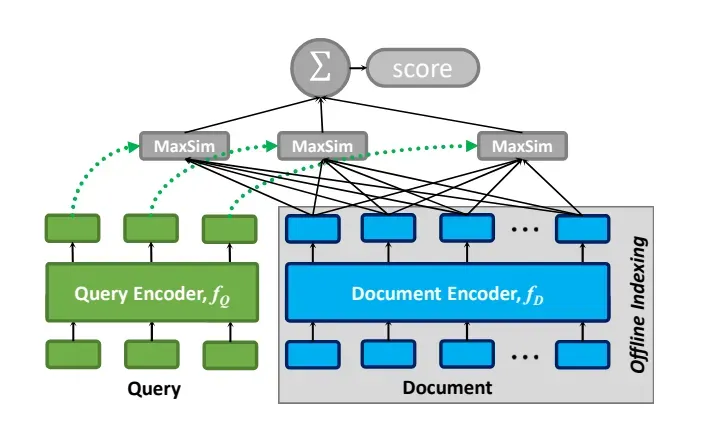
在处理查询Q和文档D时,ColBERT利用查询编码器将Q转换为一组固定大小的Embedding向量,表示为Eq。同时,文档编码器将D转换为另一组embedding向量Ed。Eq和Ed中的每个向量都拥有Q和D中周围词的上下文信息。
有了Eq和Ed,ColBERT通过后期交互方法计算Q和D之间的相关性分数,我们将其定义为最大相似性(MaxSim)的总和。具体来说,该方法识别每个Eq中的向量与Ed中的向量之间的最大内积,然后通过求和将这些结果组合起来。
从概念上讲,这种后期交互机制将每个查询中的 token embeddingtq与文档向量列表进行比较,并考虑了在查询中的上下文。这个过程通过识别tq与文档中的词td之间的最高相似度分数来量化"匹配"程度。ColBERT通过聚合所有查询项之间的最大匹配程度来评估文档的相关性。
查询编码器
在处理查询Q时,查询编码器利用基于BERT的模型将Q tokenize为单词片段token,表示为q1、q2、...、ql。此外,它在BERT的序列起始token[CLS]之后立即插入一个特殊的token[Q]。如果查询包含的token数量少于预定义的阈值Nq,则使用token[mask]进行填充,直到达到长度Nq。相反,如果超过了Nq个token,则将其截断为前Nq个token。然后,将这个调整后的输入token序列传入BERT的Transformer架构中,为每个token生成上下文表示。生成的输出包括一组Embedding向量,定义如下:
Eq := Normalize( CNN( BERT("[Q], q0, q1, ...ql, [mask], [mask], …, [mask]") ) )
Eq表示通过正则化的token序列(包括特殊的token[Q]和填充token[mask]),即通过BERT的Transformer层,并应用卷积神经网络(CNN)进行进一步精炼而得到的归一化输出。
文档编码器
文档编码器的操作与查询编码器类似,将文档 D tokenize 为token,表示为d1、d2、...、dn。在这个过程之后,文档编码器在BERT的起始token[CLS]之后立即插入一个特殊的token[D],以指示文档的开始。与查询 tokenize 过程不同,文档中不添加[mask]。
在将这个输入序列通过BERT和随后的线性层之后,文档编码器需要移除与标点符号所对应的embedding。这个过滤步骤是为减少每个文档的embedding 向量数量。输出一组向量,表示为Ed:
Ed := Filter( Normalize( CNN( BERT("[D], d0, d1, ..., dn") ) ) )
Ed表示将tokenized 的文档通过BERT的Transformer层、应用卷积神经网络操作并过滤掉与标点符号相关的Embedding所获得的归一化和过滤后的向量列表。
后期交互机制
在信息检索中,“交互”是指通过比较查询和文档的向量表示来评估它们之间的相关性。“后期交互”表示这种比较发生在查询和文档已经被独立编码之后。这种方法与BERT之类的“早期交互”模型不同——早期交互中查询和文档的Embedding在较早的阶段相互作用,通常是在编码之前或期间。
ColBERT采用了一种后期交互机制,使得查询和文档的表示可以用于预计算。然后,在末尾使用简化的交互步骤来计算已编码的向量列表之间的相似性。与早期交互方法相比,后期交互可以加快检索时间和降低计算需求,适用于需要高效处理大量文档的场景。
那么,后期交互过程是如何实现的呢?
如前所述,编码器将查询和文档转换为token级别的embedding列表Eq和Ed。然后,后期交互阶段使用针对每个Eq中的向量,找与其产生最大内积的Ed中的向量(即为向量之间的相似性),并将所有分数求和的最大相似性(MaxSim)计算。MaxSim的计算结果就反映了查询与文档之间的相关性分数,表示为Sq,d。
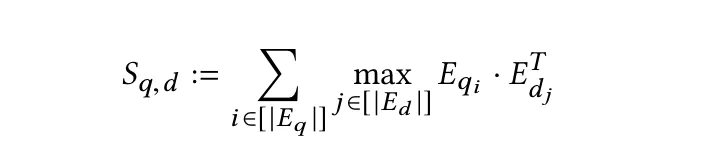
这种方法的独特价值在于能够对查询与文档token embedding之间进行详细、细粒度的比较,有效捕捉查询和文档中长度不同的短语或句子之间的相似性。这尤其适合需要精确匹配文本片段的应用场景,可以提高搜索或匹配过程的整体准确性。
04.ColBERTv2:基于ColBERT优化检索效果和存储效率
ColBERT 通过对查询和文档进行单独编码,并采用详细的后期交互进行准确的相似性计算。与Sentence-BERT不同,ColBERT为句子中的每个 token生成一个向量——这种方法在相似性检索中更有效,但是模型消耗的存储空间会呈指数性增长。
ColBERTv2能够解决这些问题。这个版本通过将乘积量化(PQ)与基于质心的编码策略相结合来增强ColBERT。PQ使ColBERTv2能够压缩token embedding 而不会造成显著的信息丢失,从而降低存储成本同时保持模型的检索效果。这一改进优化了存储效率,并保留了模型对细粒度相似性评估的能力,使ColBERTv2成为大规模检索系统的更可行的解决方案。
ColBERTv2 中的基于质心的编码
在 ColBERTv2 中,由编码器生成的token向量被聚类成不同的组,每个组由一个质心表示。这种方法允许质心索引描述每个向量以及捕捉其与质心的偏差的残差分量。这个残差的每个维度只需被高效地量化为一个或两个比特。因此,原始向量可以通过质心索引和量化的残差的组合来有效地表示,与实际向量只有轻微的差异。这些差异对整体检索准确性影响很小。
如何使用基于质心的向量进行相似性检索
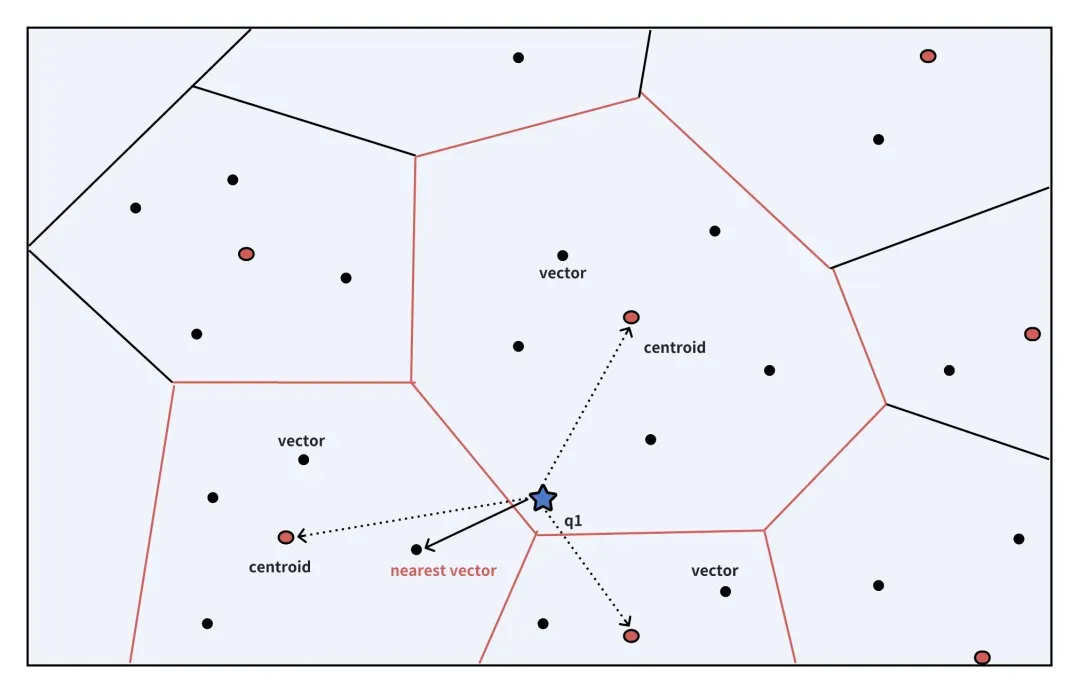
首先,ColBERTv2 利用先前描述的基于质心的方法高效地对文档进行编码,其中质心及其相关的量化残差表示每个文档。同样地,编码器将查询转换为一组token级别的向量,表示为{q1, q2, q3, ..., qn}。
在检索阶段,对于每个查询向量qi,我们首先检索预先确定数量的质心,这个是数量称为nprobe。然后,我们从这些质心的低比特量化残差中重建对应的向量,并根据它们的文档ID将它们组织成组。这种组织方式简化了后续的匹配过程,图中反映了nprobe为3的搜索查找过程,红圈为每一个组的质心。
一旦我们按文档ID对向量进行分类,目标就转移到识别与每个qi最相似的向量。例如,如果查询向量q1与文档1中的向量d1紧密对齐,并且该文档的组包括{d1, d3, d5},那么就无需为{d1, d2, d3, d4, d5}计算完整的MaxSim。这是因为向量d2和d4,不是最初的nprobe群的一部分,不太可能与任何查询向量qi紧密匹配。在识别出最相关的分组之后,系统检索Top-K个最相似的文档。我们加载这些文档的所有完整向量进行最终的重新排名,包括最初不在nprobe群中的向量。
05.总结
文本对 ColBERT 进行了深入的解析。与 BERT 之类的传统 embedding 模型不同,ColBERT 保留了 token 级别的 embedding,通过其创新的后期交互机制实现了更精确和细粒度的相似性计算。
我们还研究了 ColBERTv2——通过 PQ 和基于质心的编码来减轻存储消耗的优化版ColBERT。这些改进有效提高了存储效率,并保持了模型的检索效果。ColBERT 模型的持续改进和创新展现了自然语言表征技术的动态发展,表明未来检索系统会有更高的准确性和效率。
《庆余年2》盗版资源被上传到 npm,导致 npmmirror 不得已暂停 unpkg 服务 Windows 11 将在中国区设备上安装「微软电脑管家」 新款 iPad Pro 使用了 12GB 内存颗粒,但却声称是 8GB 内存 Kotlin 2.0.0 稳定版发布,K2 编译器已稳定 Linus “吃狗粮”最积极! macOS 终端工具 iTerm2 发布重大更新 3.5.0:集成 ChatGPT、让 AI 帮你写命令 开源日报 | Kotlin 2.0.0;简体中文压缩数据只有6TB;AI不是核弹;全球首个开源大规模"NoC IP";华为有哪些能力是当前不可代替的? 微软 Windows 过渡到 Arm 架构的核心组件 —— “Prism”模拟器 通义千问 GPT-4 级主力模型降价 97%,1 块钱 200 万 tokens curl 8.8.0 正式发布