0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
随着人工智能技术的飞速发展,自动驾驶技术已成为汽车工业和科技领域的热点(甚至可以说是最热的点)。在这场技术革命中,AI芯片作为自动驾驶汽车的大脑,扮演着至关重要的角色。
主流(或者应该说是全部)AI芯片都是以SoC(System on Chip,片上系统)的形式存在的,我计划写一个系列文章,将以不同供应商为分类,介绍不同厂家提供的自动驾驶中的SoC解决方案。
本系列的首篇,必须先介绍下NVIDIA,Respect!本文的说明将基于NVIDIA官网及NVIDIA Developer Zone的公开资料。
全部是公开资料!!也免去我泄密的嫌疑!~~~///(^v^)\\\~~~
NVIDIA DRIVE™ AGX 是一个可扩展式开放平台,可充当自动驾驶汽车的AI大脑。该平台可实现行业领先的性能和低能耗计算,为开发及生产搭载 AI 且能安全行驶的汽车、卡车、无人驾驶出租车和班车提供助力。首先我们先看下NVIDIA的自动驾驶SoC产品序列:

发现这些名字的来源了么~

这些产品中PARKER和XAVIER已经算是比较老的、算力也跟不上了(没错,这个行业的更新速度就是这么快!),而THOR现在又未正式推出,因此本文将针对目前的主流产品——ORIN进行说明。


ORIN芯片是在2019年首次公布(2022年正式推出),并在后续几年内逐步成为市场关注的焦点。ORIN是NVIDIA在自动驾驶领域继Xavier之后的又一力作,专为实现更高级别的自动驾驶(L2至L5)以及智能座舱体验而设计。
1. 技术规格
ORIN的整体技术规格如下:
- 制程技术:ORIN采用先进的7纳米生产工艺,这一制造工艺能在较小的芯片面积内集成更多晶体管,单个ORIN芯片集成了170亿个晶体管。
- 运算性能:ORIN芯片的运算能力达到了惊人的254TOPS(在2019年发布时,公布的是200TOPS,还是保守了),相较于上一代XAVIER芯片,性能提升了8倍,这种强大的算力对于处理自动驾驶所需的复杂算法和实时数据处理至关重要。
- CPU架构:搭载了基于Arm Cortex-A78AE架构的CPU,设计上兼顾了高性能和功能安全性。
- GPU技术:集成NVIDIA Ampere架构的GPU,包含两个图形处理簇GPC,为深度学习、图像处理和并行计算提供了强大的支持。
- AI推理能力:ORIN芯片特别强化了AI推理性能,能够执行复杂的神经网络模型,提升自动驾驶汽车的感知、决策和规划能力。
- 功能安全与冗余设计:ORIN在设计上符合ISO 26262 ASIL-D级别的功能安全标准,意味着它能够满足最严格的安全要求,为自动驾驶系统提供安全保障。
- 灵活性与可配置性:支持多种运算模式,可以根据不同应用场景的需求进行灵活配置,从而实现更高的能效比和更低的功耗。

2. 丰富的汽车接口
以Orin-X为例,SoC在自动驾驶汽车中的通讯原理图如下:

Orin-X的关联接口有以下:
- 在顶部,有多个以太网接口(2×10GbeE, 4xGMSL等),这些接口都是为了确保车辆的感知系统、决策系统和执行系统之间能够快速、可靠地交换数据,支持自动驾驶汽车所需的复杂计算和数据处理任务;
- 在左边有一个PCIex8连接器,增加了系统灵活性和可扩展性,允许用户根据需求添加提高系统性能或增加新功能的硬件组件;
- Orin-X右侧的SMCU(System Management Control Unit)是维持整个SoC高效、可靠运行的核心组件,负责管理和协调SoC内部的各种资源和服务(例如电源管理、热管理、系统初始化等);
- 在底部,可以看到一些音频相关的组件,如Audio Codec和A2B ASIC;
- 在右上角,有两个ENET Switch(以太网交换机),它们用于将数据路由到不同的设备或子系统。
ORIN也可以在自动驾驶车辆中2个同时使用(即双ORIN,一般也会分为主从ORIN):

接下来说明下Orin的内部架构,在开始前需要先澄清一下:下面的说明都是以Jetson AGX Orin的资料来说明的,因为我实在没找到Drive AGX Orin的说明书或者白皮书。Jetson Orin和Drive Orin虽然在使用场景上不同(Jetson Orin应用在工业:无人机、机器人等领域),但是其SoC的内部架构是一样的,所以这里用Jetson Orin的资料来说明也没有问题。
3. SoC架构
如上“技术规格所述”,Orin的SoC整体架构如下,接下来对各个模块逐个讲解。

3.1 GPU
Orin模块集成了Ampere架构的GPU,该GPU由2个图形处理集群(GPC, Graphic Processing Cluster)、最多8个纹理处理集群(TPC, Texture Processing Cluster)、最多16个流式多处理器(SM, Streaming Multiprocessors)组成。
每个SM配备有192KB的L1缓存以及总共4MB的L2缓存,每个SM则配备了128个CUDA核心,并且每个SM还集成了四个第三代张量核心。(Jetson AGX Orin 64GB版本拥有2048个CUDA核心和64个张量核心,能够实现最高170万亿次INT8稀疏张量运算的性能,以及最高5.3万亿次FP32精度的CUDA运算性能。)
借助Ampere GPU,Orin引入了对稀疏性的支持。稀疏性是一种细粒度的计算结构,能够使吞吐量翻倍同时减少内存使用,极大地提升了效率和实用性。

Ampere架构带来了第三代张量核心的支持,这使得其能支持16x HMMA(半精度混合矩阵乘法累加)、32x IMMA(整数矩阵乘法累积),以及一项新的稀疏性特性。
利用这项稀疏性特性,用户可以充分利用深度学习网络中的细粒度结构化稀疏性,使得张量核心操作的吞吐量翻倍。此稀疏性设定要求每4个权重中至多有2个是非零值。它使得张量核心能够跳过零值计算,从而实现吞吐量的加倍,并显著减少内存存储需求。网络训练起初可以在密集权重上进行,随后通过剪枝技术进行优化,最后再对稀疏权重进行微调。

3.2 DLA
Deep Learning Accelerator(DLA)是一种针对深度学习操作优化的固定功能加速器。它旨在通过全硬件加速的方式执行卷积神经网络的推理任务。
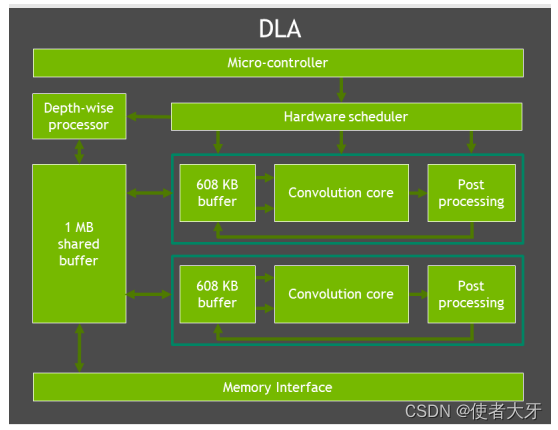
客户可以像在GPU上一样,使用TensorRT来加速他们在DLA上的模型。NVIDIA DLA旨在将深度学习推理任务从GPU卸载,从而使GPU能够运行更复杂的网络和动态任务。通过这种方式,DLA和GPU协同工作,提高了整体系统的效率和性能,特别是在涉及大量并行推理操作的应用场景中。
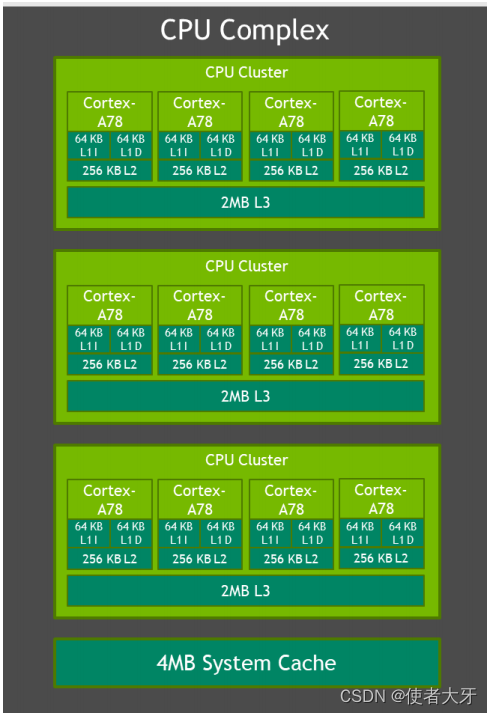
3.3 CPU
Orin处理器复合体包含多达12个CPU核心。每个核心配备有64KB指令L1缓存和64KB数据L1缓存,以及256KB的L2缓存。与Jetson AGX Xavier类似,每个CPU簇还共享有2MB的L3缓存。CPU的最大支持频率为2.2 GHz。
3.4 内存
Jetson AGX Orin模块相比Jetson AGX Xavier,在内存带宽上提高了1.4倍,存储容量上翻了一番,支持32GB或64GB的256位LPDDR5内存以及64GB的eMMC存储。DRAM支持的最大时钟速度为3200 MHz,每针脚的数据传输速率达到6400 Gbps,从而实现了204.8GB/s的内存带宽。下图详细说明了各个不同组件如何与内存控制器架构及DRAM相互作用。
