提出背景
论文:https://arxiv.org/pdf/2312.17449.pdf
代码:https://github.com/eosphoros-ai/DB-GPT
本文介绍了DB-GPT,一个智能且生产就绪的项目,旨在通过增强型大型语言模型(LLMs)来改善数据摄取、结构化和访问,同时采用隐私化技术。
DB-GPT不仅利用了LLMs固有的自然语言理解和生成能力,还通过代理和插件机制不断优化数据驱动引擎。
DB-GPT 结构

DB-GPT系统处理查询的架构,展示了以下组件和流程:
- 提交一个查询。
- 检索器组件选择相关信息。
- 重排器细化选择以确保最佳匹配。
- 为文本转SQL任务细化调整的**语言模型(LLM)**处理精炼信息。
- 系统确保身份安全。
- 生成并返回一个响应。
架构下方还展示了一个多源知识库,表明系统使用多个来源,如数据库、网页和PDF文件。
还有如AIOps代理、SQL代理和商业分析代理,可以与不同类型的数据和服务接口。
具体问题与解法
-
隐私和安全保护
- 子问题:如何在不牺牲用户隐私和数据安全的前提下,允许用户与数据库进行自然语言交互?
- 子解法:DB-GPT允许用户在个人设备或本地服务器上部署,并且可以在没有互联网连接的情况下运行,确保数据不会离开执行环境,通过代理去标识化技术中介隐藏个人标识符,从而降低未授权访问和私人信息利用的风险。
-
多源知识库问答优化
- 子问题:如何处理和回答基于多源非结构化数据(如PDF、网页、图像等)的查询?
- 子解法:DB-GPT构建了一个管道,将多源非结构化数据转换为中间表示,存储在结构化知识库中,检索最相关的信息,并针对给定查询生成全面的自然语言响应。该管道针对效率进行了优化,并且支持双语查询。
-
文本转SQL细化调整
- 子问题:如何降低没有SQL专业知识的用户与数据交互的障碍?
- 子解法:DB-GPT对几种常用的LLMs(如Llama-2、GLM)进行了细化调整,专门针对文本转SQL任务。这显著降低了用户的门槛,并且针对双语查询进行了优化。
-
知识代理和插件集成
- 子问题:如何通过自动化决策和数据分析增强与数据的交互?
- 子解法:DB-GPT使得开发和应用具有高级数据分析能力的对话代理成为可能,这些自动化决策支持数据上的交互式用例。它还提供了多种查询和检索服务的插件作为与数据交互的工具。
背景分析
-
隐私和安全保护:之所以采用隐私和安全保护,是因为在处理敏感数据时用户隐私和数据安全是首要考虑的。
在这个场景中,医疗工作者可能需要查询包含患者敏感信息的数据库来辅助治疗决策。
采用隐私和安全保护措施,比如代理去标识化技术,可以确保在执行此类查询时,患者的个人信息不会被泄露。
系统可以设计成在处理查询结果之前自动去除或替换掉敏感数据,如姓名、社会保障号码或地址,以保护个人隐私。
-
文本转SQL细化调整:采用这个解决方案是因为非技术用户通常不熟悉SQL查询语言,这一特征要求系统能够理解自然语言查询并转换为SQL命令,从而简化用户与数据库的交互。
当医疗工作者使用自然语言提出查询,如“显示所有糖尿病患者的最新血糖记录”,系统需要将这个自然语言查询转换成SQL语句,以便从数据库中检索信息。
文本转SQL细化调整功能可以帮助实现这一点,让非技术背景的用户也能轻松地与数据库进行交互。
-
多源知识库问答优化:之所以优化基于多源知识库的问答系统,是因为现代数据通常分布在多种格式和源中。
这要求系统能够处理和理解来自不同来源的非结构化数据,从而提供准确且全面的回答。
同时,由于相关数据可能散布在电子健康记录、实验室结果和第三方健康应用程序中,多源知识库问答优化可以确保从所有相关来源中提取和综合信息,从而为医疗工作者提供一个全面的患者健康概况。
-
知识代理和插件集成:之所以集成知识代理和插件,是因为自动化决策和高效的数据分析能力可以显著提高用户与数据交互的效率和质量。
最后,集成的知识代理和插件,比如一个药物相互作用检查器,可以自动提醒医生关于患者当前用药可能存在的风险。
这样的工具通过整合多种数据源和应用专业知识,增加了从大量数据中提取有价值信息的效率。
DB-GPT通过这些创新解决方案,不仅提高了用户与数据库交互的自然性和直观性,而且在保护用户隐私和数据安全的同时,还优化了数据处理和查询的效率。
对比其他工具
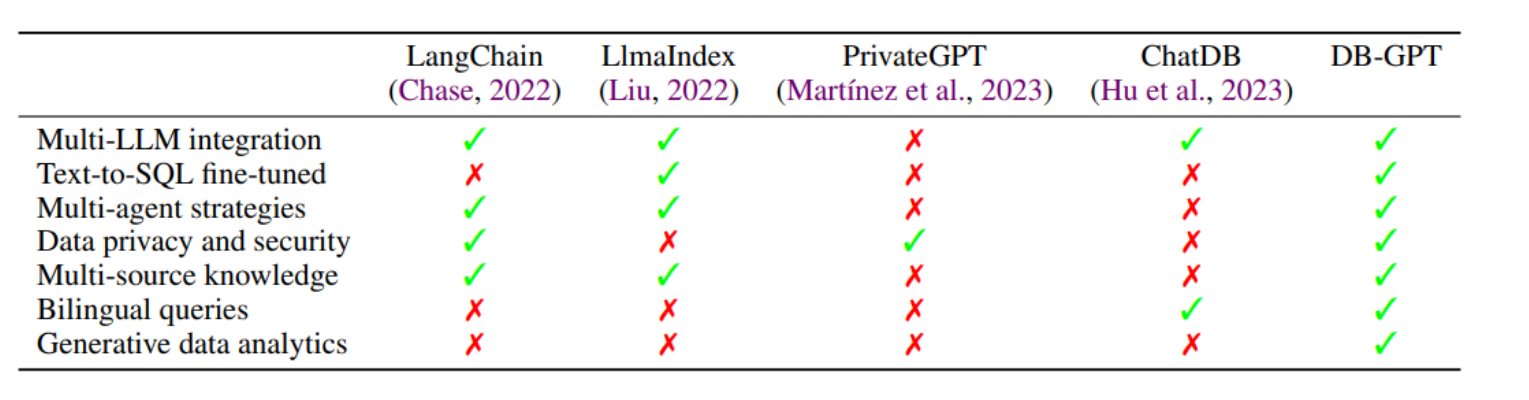
比较了五种不同的方法或系统:LangChain、LlmalIndex、PrivateGPT 、ChatDB和 DB-GPT。
比较了这些模型的七个特性:
- 多LLM整合
- 文本转SQL细化调整
- 多代理策略
- 数据隐私和安全
- 多源知识
- 双语查询
- 生成数据分析
每个系统都用对号(✓)或叉号(✗)标记,表示它是否具有所讨论的特性。
例如,LangChain 具有多LLM整合、多代理策略、数据隐私和安全、多源知识,但它不支持文本转SQL细化调整、双语查询或生成数据分析。
DB-GPT系统设计
是一个基于检索增强生成(RAG)框架的系统,用于提升语言模型(LLMs)的性能和效率。
-
系统设计概述:DB-GPT是在RAG框架的基础上建立的,通过结合新的训练和推理技术来提高性能和效率。
-
多源RAG用于问答(QA):
- 知识构建:构建一个包含大量文档的知识库,并将文档分段并嵌入到多维空间中。
- 知识检索:当有查询时,系统将查询转换为向量,并从知识库中检索相关段落。
- 学习嵌入和搜索:训练编码器以提高检索的相关性。
- 自适应上下文学习(ICL)和LLM生成:根据相关性对检索结果进行排名,并结合模板生成响应。
-
部署和推理:面向服务的多模型框架(SMMF):
- 设计了一个用于部署和推理多LLMs的平台,包含模型推理层和模型部署层。
-
多智能体策略:DB-GPT支持不同角色的互动,并且提供了协调机制以促进多个LLM智能体之间的合作。
-
DB插件:LLMs通过集成插件来提升数据库交互能力,包括结构分析器和查询执行器。
解法拆解:
- 子解法1:知识构建使用多维嵌入表示文档。
- 子解法2:知识检索通过将查询转换为向量来检索相关段落。
- 子解法3:自适应ICL结合模板和LLM生成响应来提高上下文理解。
- 子解法4:SMMF提供了一个快速且易于使用的部署和推理平台。
- 子解法5:多智能体策略使不同角色的LLM智能体能够协同工作。
- 子解法6:DB插件提高了LLMs的数据库交互能力。
历史问题及其背景:
- 之所以使用知识构建,是因为需要处理的文档数量庞大,需要将其有效地嵌入到模型中以增强检索能力。
- 之所以使用知识检索,是因为模型需要能够理解并找到与用户查询最相关的信息。
- 之所以使用自适应ICL,是因为LLMs需要更好地理解上下文信息,提供准确的响应。
- 之所以使用SMMF,是因为需要一个能够快速部署和推理多种LLMs的可扩展平台。
- 之所以使用多智能体策略,是因为不同的任务需要不同角色的专业知识和技能。
- 之所以使用DB插件,是因为LLMs自身不擅长数据库查询,需要特定的工具来增强这一能力。
DB-GPT 三步:

知识构建(Knowledge Construction)
知识检索(Knowledge Retrieval),进一步分为:
- 查询理解(Query Understanding)
- 检索路由(Retrieval Router)
- 文档重新排名(Document Rerank)
- 相关块(Relevant Chunks)
自适应交互式编程(Adaptive ICL),包括:
- 提示策略管理(Prompt Strategy Management)
- 数据隐私保护(Data Privacy Protection)
- 查询重写(Query Rewrite)
最终是大型语言模型(LLM),它提供答案(Answer)。
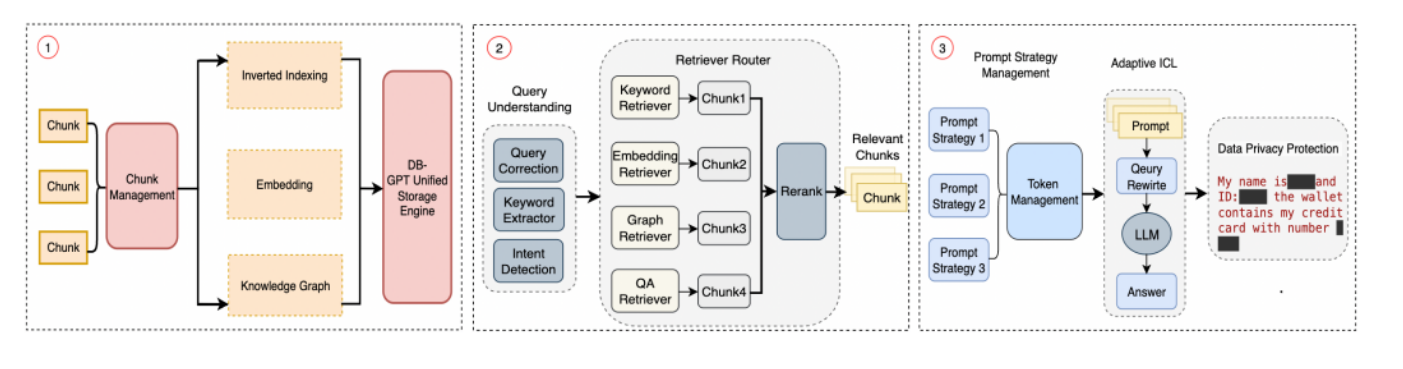
知识构建、知识检索、以及自适应交互式编程和响应生成的流程细节:
- 图3显示了知识构建过程,包括逆索引(Inverted Indexing)、块管理(Chunk Management)、嵌入(Embedding)和知识图谱(Knowledge Graph)。
- 图4展示了知识检索流程,从查询理解开始,包括关键词提取器(Keyword Extractor)、意图检测(Intent Detection)等,通过不同检索器(例如关键词检索器、嵌入检索器和图检索器)到达重新排名(Rerank)和选定的相关块(Relevant Chunks)。
- 图5则是自适应交互式编程和响应生成的流程,涉及到提示策略管理、查询重写,最后由大型语言模型生成答案。