面对客户环境中长期运行的各种类型的传统数据库,如何优雅地设计数据迁移的方案,既能灵活地应对各种数据导入场景和多源异构数据库,又能满足客户对数据导入结果的准确性、一致性、实时性的要求,让客户平滑地迁移到 PieCloudDB 数据库生态,是一个巨大的挑战。PieCloudDB Database 打造了丰富的数据同步工具来实现数据的高效流动,本文将聚焦 PieCloudDB Flink Connector 工具进行详细的介绍。
拓数派旗下 PieCloudDB 是一款云原生分布式虚拟数仓,为企业提供全新基于云数仓数字化解决方案,助力企业建立以数据资产为核心的竞争壁垒,以云资源最优化配置实现无限数据计算可能。PieCloudDB 通过多种创新性技术将物理数仓整合到云原生数据计算平台,实现了分析型数据仓库上云虚拟化,打造了存储计算分离的全新 eMPP 架构,突破了传统 MPP 数据库多种瓶颈限制,打破客户生产环境数据孤岛的同时,也实现了按需瞬间扩缩容,大大减少了存储空间的浪费。
Apache Flink 是一个分布式流计算处理引擎,用于在无界或有界数据流上进行有状态的计算。它在所有的通用集群环境中都可以运行,在任意规模下都可以达到内存级的计算速度。Flink 最初由德国柏林工业大学的 Stratosphere 项目发展而来,是为了支持复杂的大规模数据分析任务而设计的,并于2014年成为 Apache 软件基金会的顶级项目。用户可以运用 Flink 提供的 DataStream API 或 Table SQL API,实现功能强大且高效的实时数据计算能力。此外,Flink 原生支持的 checkpoint 机制可以为用户提供数据的一致性的保证。
Apache Flink 作为一个流处理框架,与其他开源项目和工具的整合非常紧密。经过多年的发展,整个 Flink 社区已经围绕 Flink 构成出了一个丰富的生态系统。PieCloudDB 组件 PieCloudDB Flink Connector 是拓数派团队自研的一款 Flink 连接器, 可用于将来自 Flink 系统中的数据高效地写入 PieCloudDB,配合 Flink 的 checkpoint 机制来保证数据导入结果的精准一次语义。本文将详细介绍 PieCloudDB Flink Connector 的功能和原理,并结合实例进行演示。
1 PieCloudDB Flink Connector 功能介绍
PieCloudDB Flink Connector 可提供多种将 Flink 数据导入 PieCloudDB 的方式,包括 Append-Only 模式和 Merge 模式,以满足不同级别的导入语义。
在接入方式上,PieCloudDB Flink Connector 提供多种选择,包括使用 Flink DataStream API 编写相关的作业代码集成该组件,或者直接利用 Flink SQL 语句使用该组件。
PieCloudDB Flink Connector 提供 Merge 导入模式,采用幂等写方案,配合 Flink 原生支持的 checkpoint 机制,能够保证导入结果的可靠性和一致性。
此外,PieCloudDB Flink Connector 不仅支持支持单表实时数据导入,也可以支持整库实时数据同时导入。不过后者仅支持 Flink DataStream API 的接入方式,不支持使用 Flink SQL 语法。
2 PieCloudDB Flink Connector 原理
2.1 精准一次导入原理
PieCloudDB Flink Connector 中的 PieCloudDBSink、PieCloudDBWriter类分别实现了 Flink 的 StatefulSink、StatefulSinkWriter 接口。
当开启 Flink 的 checkpoint 功能后,在一个特定的 checkpoint 执行期间,PieCloudDBWriter 负责将接收到的数据源源不断地写入内存管道,同时异步线程会将这些数据拷贝到 PieCloudDB 中的内存临时表中。当 PieCloudDB Flink Connector 算子接收到 checkpoint 信号之后,会先等待数据全部拷贝进 PieCloudDB 后,再执行第二个阶段的动作,包括数据的合并以及写入物理表。整个过程中一旦出现异常,Flink 引擎就会自动从上一个 checkpoint 开始恢复作业,保证不会发生数据丢失。
在第二个阶段中,PieCloudDB Flink Connector 采用了幂等写方案,来保证不会出现数据重复。具体做法是,当数据全部导入 PieCloudDB 的临时表后,根据表的主键字段以及数据的时序关系进行合并操作,聚合这一段时间内每个主键对应记录的所有增删改操作得到最终结果,只将该结果写入 PieCloudDB 中。
这里的聚合操作是先根据写入数据的主键和时序进行组合,然后删除目标表中该主键对应的记录,最后将最新的修改或新增写入目标表。比如一条主键为1的记录,按照时间顺序发生了修改和删除操作,那么最终结果是将该主键对应的记录从 PieCloudDB 中删除。数据的写入时序与数据在 Flink 中的顺序一致,这些时序信息是通过在临时表扩充一个单独的 bigint 列来对每条数据做跟踪而记录下来的。应用这种幂等写方案,可以确保即使发生了数据重复,也能保证精确一次的导入语义。
上述 checkpoint 机制和幂等写过程如下图所示:
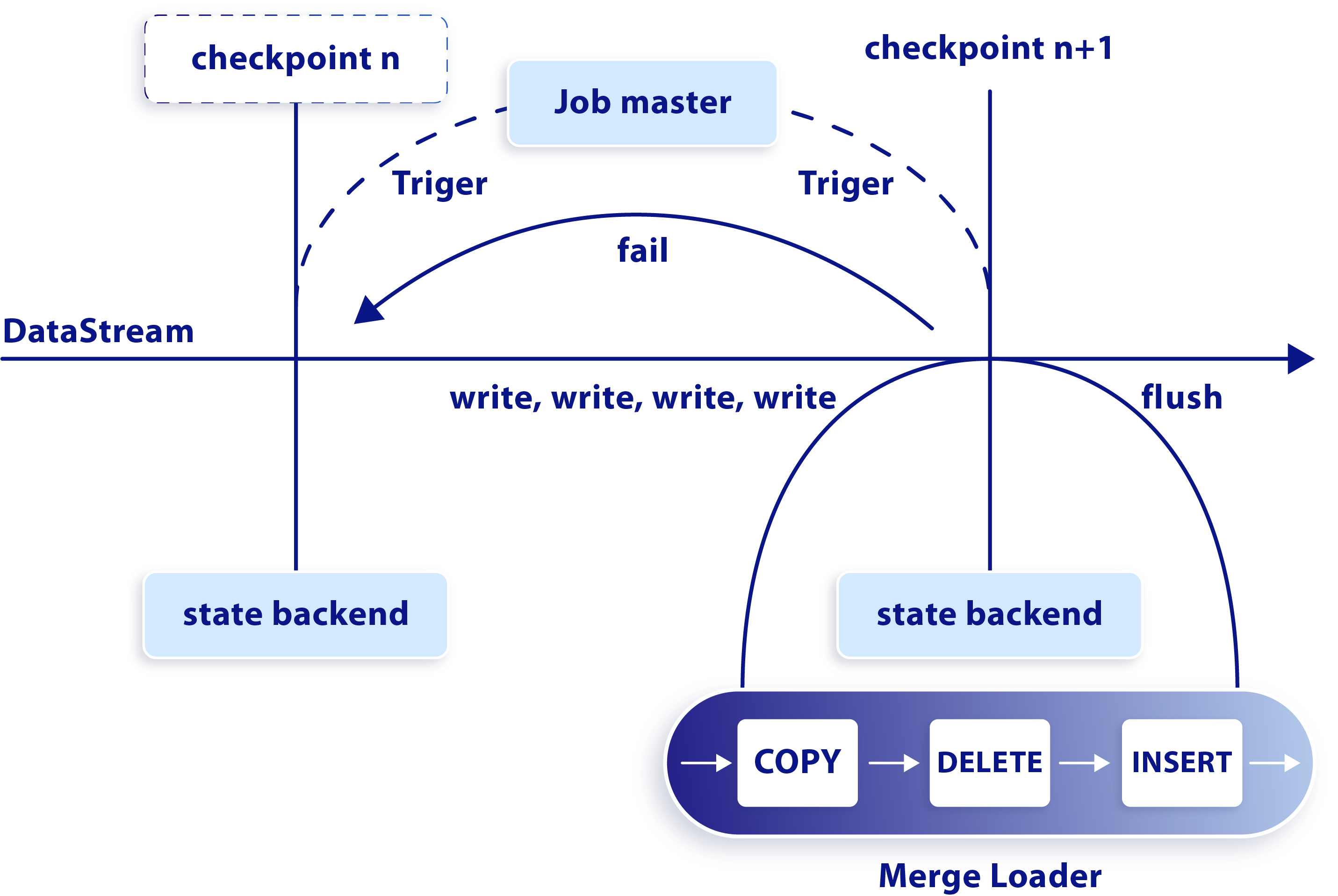
checkpoint 机制及幂等写过程
2.2 整库同步原理
对于整库同步场景来说,需要解决的是多表同时写入的问题和连接池通用性问题。 首先,对于整库同步场景来说,可能会存在多张表同时写入 PieCloudDB Flink Connector,前面处理单表的逻辑可能会导致新表数据处理的不及时,导致数据丢失。PieCloudDB Flink Connector 在内部维护了一套 Loader 池,在同一个 Flink checkpoint 周期内会为每张表都分配一个对应的 Loader,缓存在 Loader 池中。每张表写入的数据都分配给对应的 Loader 来处理,这里的处理逻辑与单表导入的处理逻辑一致。唯一的不同点在于,在 Flink checkpoint 周期结束时,PieCloudDB Flink Connector 会将该 checkpoint 内所有存在数据写入的表都刷入 PieCloudDB 中。
另一个在整库同步场景需要解决的问题是连接池的通用性问题。根据上面的设计,PieCloudDB Flink Connector 的每个实例都会维护一个 Loader 池,每个 Loader 都会占用一个 PieCloudDB 数据库连接。如果用户需要提升导入性能,一般最直接的做法是增加 Flink 作业的并行度,即创建多个 PieCloudDB Flink Connector 的实例来加速整库同步的速度,这对于具有海量历史数据的场景非常有必要。但这样会导致整个 Flink 作业需要的 PieCloudDB 数据库连接非常多,且不可控,因为无论是数据库表的数量,还是作业的并行度,都是无法预估的。仅仅通过设置内部连接池的最大连接数,只会导致作业运行时由于获取不到新的连接而无法处理,进而导致任务失败。
为了解决这一问题,PieCloudDB Flink Connector 在内部设计了一套简易的排队算法:如果数据库连接池的连接数已被占满,那么单个 checkpoint 内新来的表需要进行排队,直到 checkpoint 结束时等待其他表写入数据库并释放连接后,才会将这些排队中的表导入数据库。在此期间,这些排队的表的所有相关数据都会暂存到内存中。为了避免出现内存溢出,这里的原始数据已经提前解析好,只留下可以用于导入过程的关键信息,以大大降低内存使用率,避免出现内存溢出。使用此模型后,整库同步的过程就能保证数据库连接数全程都是可控的,最多不超过并发数和单个 PieCloudDB 数据库连接池最大连接数的乘积。
PieCloudDB Flink Connector 的整库同步功能需配合 PieCloudDB 动态作业执行器来使用,后续的文章中会进一步描述,欢迎关注!
3 PieCloudDB Flink Connector 使用演示
接下来,我们将用 MySQL 作为数据源来演示一下使用 PieCloudDB Flink Connector 将 MySQL 中的数据同步到 PieCloudDB 的过程。
创建 MySQL 源表:
create table student (id int primary key, name varchar(32), score int, sex char(1));
mysql> desc student;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| name | varchar(32) | YES | | NULL | |
| score | int | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
4 rows in set (0.03 sec)
插入一些数据:
insert into student (id, name, score, sex) values (1, 'student1', 65, '1');
insert into student (id, name, score, sex) values (2, 'student2', 75, '0');
insert into student (id, name, score, sex) values (3, 'student3', 85, '1');
insert into student (id, name, score, sex) values (4, 'student4', 95, '0');
mysql> select * from student;
+----+----------+-------+------+
| id | name | score | sex |
+----+----------+-------+------+
| 1 | student1 | 65 | 1 |
| 2 | student2 | 75 | 1 |
| 3 | student3 | NULL | NULL |
| 4 | student4 | NULL | NULL |
+----+----------+-------+------+
4 rows in set (0.01 sec)
创建 PieCloudDB 目标表(可以在 PieCloudDB 云原生管理平台的「数据洞察」功能页面进行):
create table student (id int primary key, name varchar(32), score int, sex char(1));
demo=> \d student
Table "public.student"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
id | integer | | not null |
name | character varying(32) | | |
score | integer | | |
sex | character(1) | | |
目前是一张空表:
demo=> select * from student;
id | name | score | sex
----+------+-------+-----
(0 rows)
启动 Flink 集群:
ubuntu :: work/flink/flink-1.18.0 >> bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host ubuntu.
Starting taskexecutor daemon on host ubuntu.
[INFo] 1 instance(s) of taskexecutor are already running on ubuntu.
Starting taskexecutor daemon on host ubuntu.
使用 Flink SQL 客户端工具连接集群,导入相关依赖,并开启 checkpoint:
Flink SQL> add jar '/home/frankie/work/download/flink-sql-connector-mysql-cdc-2.4.0.jar';
[INFO] Execute statement succeed.
Flink SQL> add jar '/home/frankie/work/download/flink-sql-connector-pieclouddb-1.2.0.jar';
[INFO] Execute statement succeed.
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
[INFO] Execute statement succeed.
创建 Flink CDC 源表:
Flink SQL> CREATE TABLE source_student_mysql (
id INT,
name STRING,
score INT,
sex CHAR(1),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql-host',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'testdb',
'table-name' = 'student');
[INFO] Execute statement succeed.
创建 Flink PieCloudDB 目标表:
Flink SQL> CREATE TABLE sink_student_pdb (
id INT,
name STRING,
score INT,
sex CHAR(1),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'pieclouddb',
'hostname' = 'pieclouddb-host',
'port' = 'your-pieclouddb-port',
'username' = 'your-username',
'password' = 'your-password',
'pdb_warehouse' = 'your-pdbwarehouse',
'database-name' = 'demo',
'table-name' = 'student',
'load_mode' = 'merge');
[INFO] Execute statement succeed.
执行导入:
Flink SQL> INSERT INTO sink_student_pdb SELECT * FROM source_student_mysql;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 660b747ef8fb64f95064a461af9924bc
查看 Flink 的 WebUI,可以看到这个数据导入的流任务在持续运行:
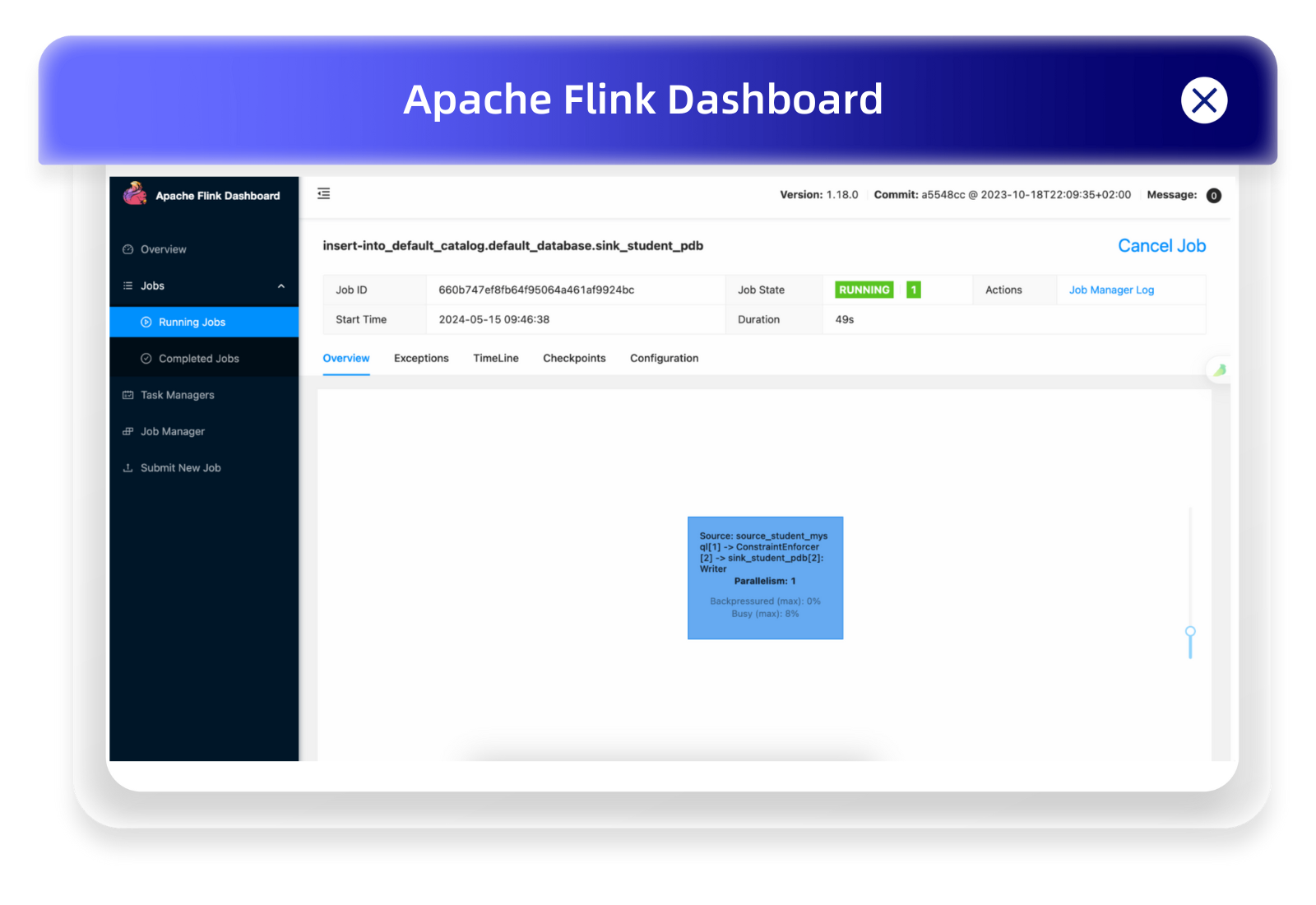
Flink Web 操作界面
查看 PieCloudDB 中的数据,可以看到数据已经正确导入
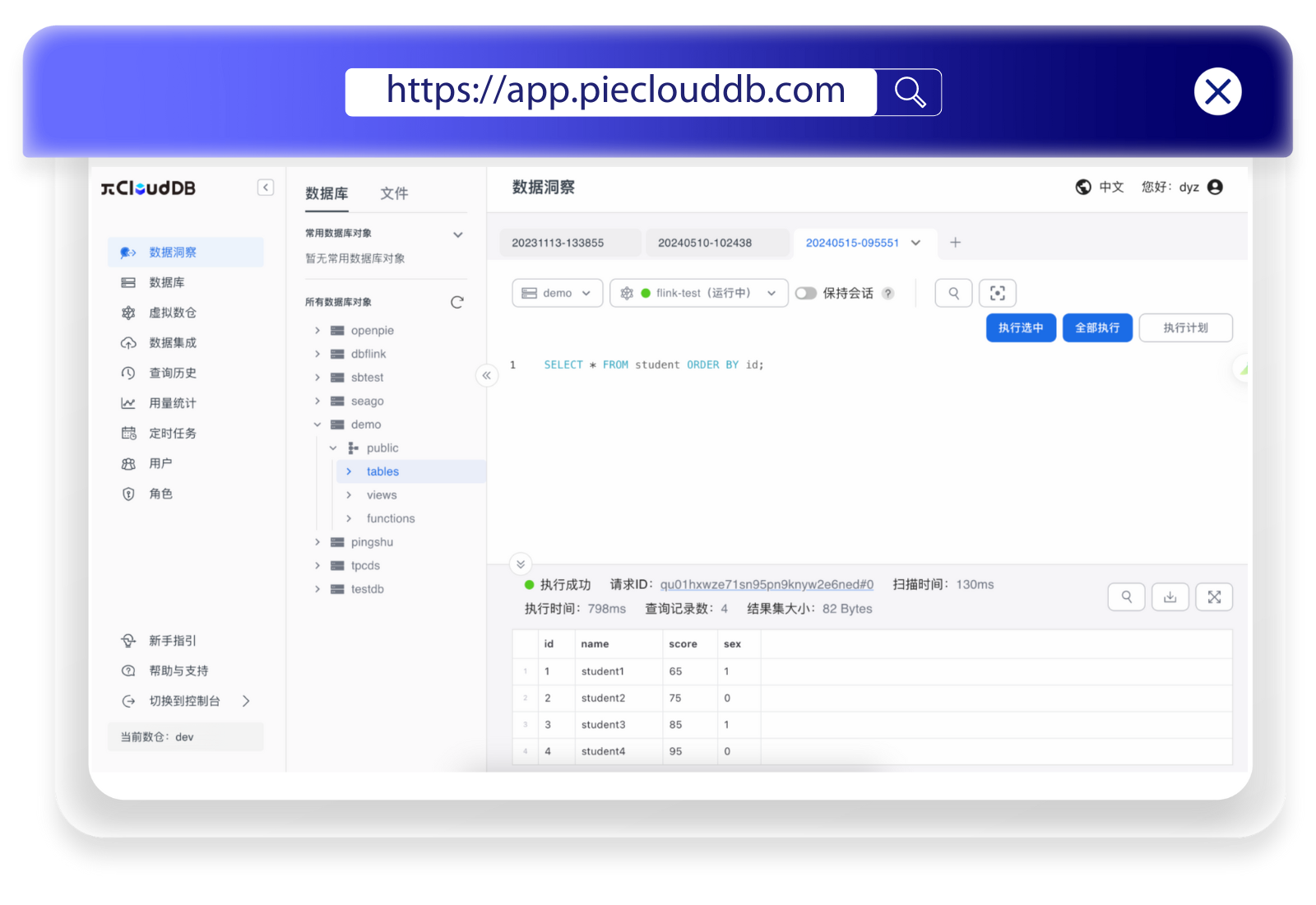
数据成功导入 PieCloudDB
除了使用 Flink SQL 的接入方式之外,PieCloudDB Flink Connector 还支持通过 Flink Datastream API 来使用。
未来,拓数派团队致力于对 PieCloudDB Flink Connector 进行持续的功能增强与迭代升级,计划引入高级特性,如 schema evolution 以及动态加表功能,以满足更复杂的数据处理需求。
同时,PieCloudDB 将持续扩展其数据同步工具组件的生态,致力于打造更为全面和强大的连接工具,包括 Flink、Spark 等大数据处理框架的集成工具,以及 CDC(Change Data Capture)和 Kafka 等实时数据同步工具,让用户将能够实现数据的高效流动和实时处理,进一步释放数据的潜力。