SAE 简介
Serverless 应用引擎 SAE(Serverless App Engine)是一款零代码改造、极简易用、自适应弹性的应用全托管平台。SAE 能够让用户免运维 IaaS 和 Kubernetes ,秒级完成从源代码、代码包、Docker 镜像部署任意语言的在线应用(例如 Web、微服务、Job 任务)到 SAE,并自动伸缩实例按使用量计费,开箱即用日志、监控、负载均衡等配套能力。
SAE 基于容器标准构建,核心能力开源,无厂商锁定,拥有丰富的平台工程能力,例如 CLI、S2A(Source to Application)等,助力研发运维提效。
可观测性
观测云可以收集来自 SAE 上部署应用的可观测性数据。具体流程如下:
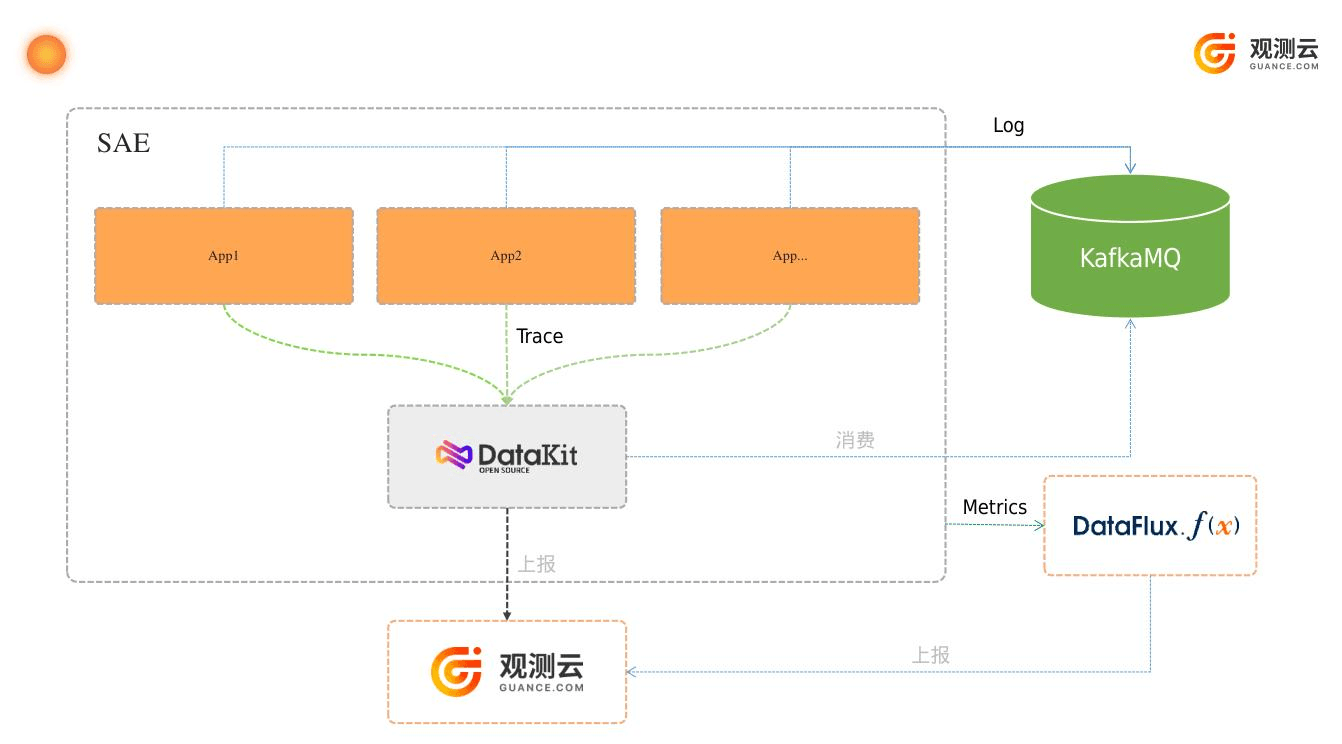
- 应用通过接入 APM 上报 trace 数据到 DataKit
- 应用的日志数据可以通过 KafkaMQ 收集后,通过 DataKit 进行消费
- 应用容器的指标数据利用阿里云的监控 API 并通过 Function 平台(DataFlux.f(x))进行采集后上报到观测云
- DataKit 收集到对应的数据后统一处理并上报到观测云上
NAT 网关配置
DataKit 获取到数据后需要上报到观测云,就需要 SAE 出外网的能力,SAE 应用出外网主要是需要配置 NAT 网关。
参考文档步骤:SAE应用如何从VPC内网环境访问公网
创建 Kafka 服务
请访问阿里云消息队列 Kafka 版控制台,根据需求创建实例,在实例部署前,请了解文档《设置日志收集至 Kafka》中“前提条件”章节中关于 VPC 和 vSwitch 的限制。部署成功后在“Topic 管理”页面创建 Topic:springboot-server_log ,建议与 SAE 应用同名,Group 无需创建。
DataKit
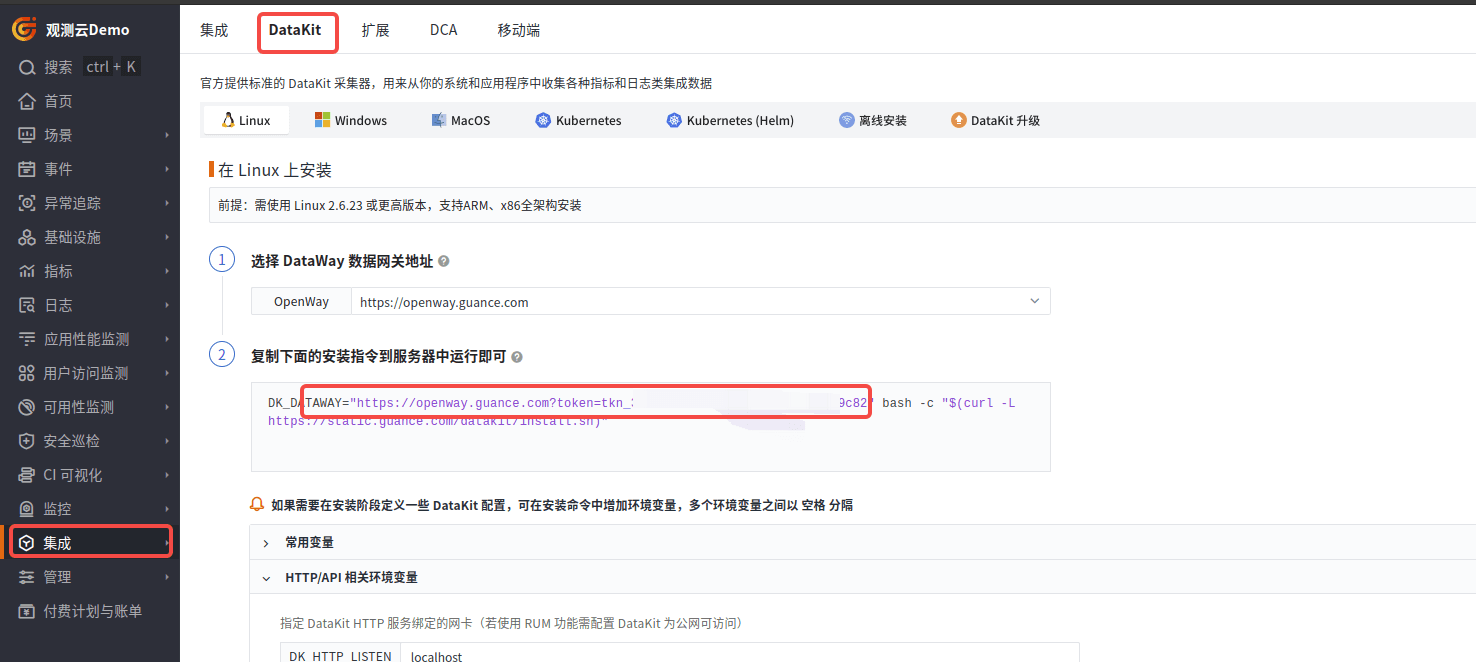
注册观测云账号:https://auth.guance.com/businessRegister
登陆后,在集成里面找到 DataKit,并复制 DK_DATAWAY,后面需要用到。
创建 DataKit
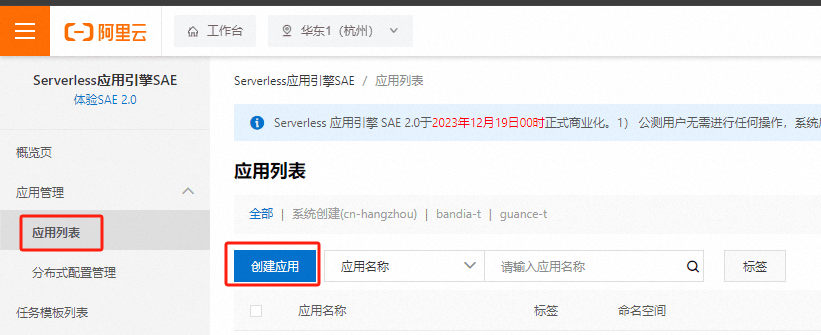
- 进入 SAE,点击应用列表 - 创建应用。
- 填写应用信息
- 应用名称
- 选择命名空间,如果没有,则创建一个
- 选择vpc,如果没有,则创建一个
- 选择安全组: vswitch 要与 NAT 的交换机匹配
- 实例数按需调整
- CPU 1 core、内存1G
- 完成后点击下一步
- 添加镜像:
pubrepo.guance.com/datakit/datakit:1.31.0 - 添加环境变量
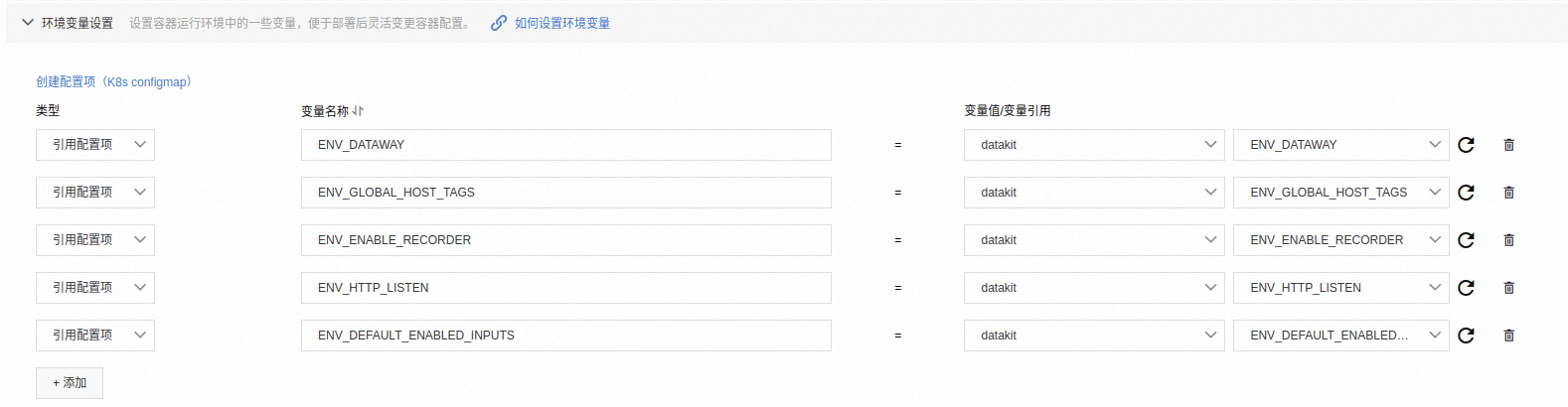
建议采用配置项方式,方便管理维护配置,具体参考下面的配置项内容。
- 添加配置
创建 kafkamq 采集器配置

- 保存
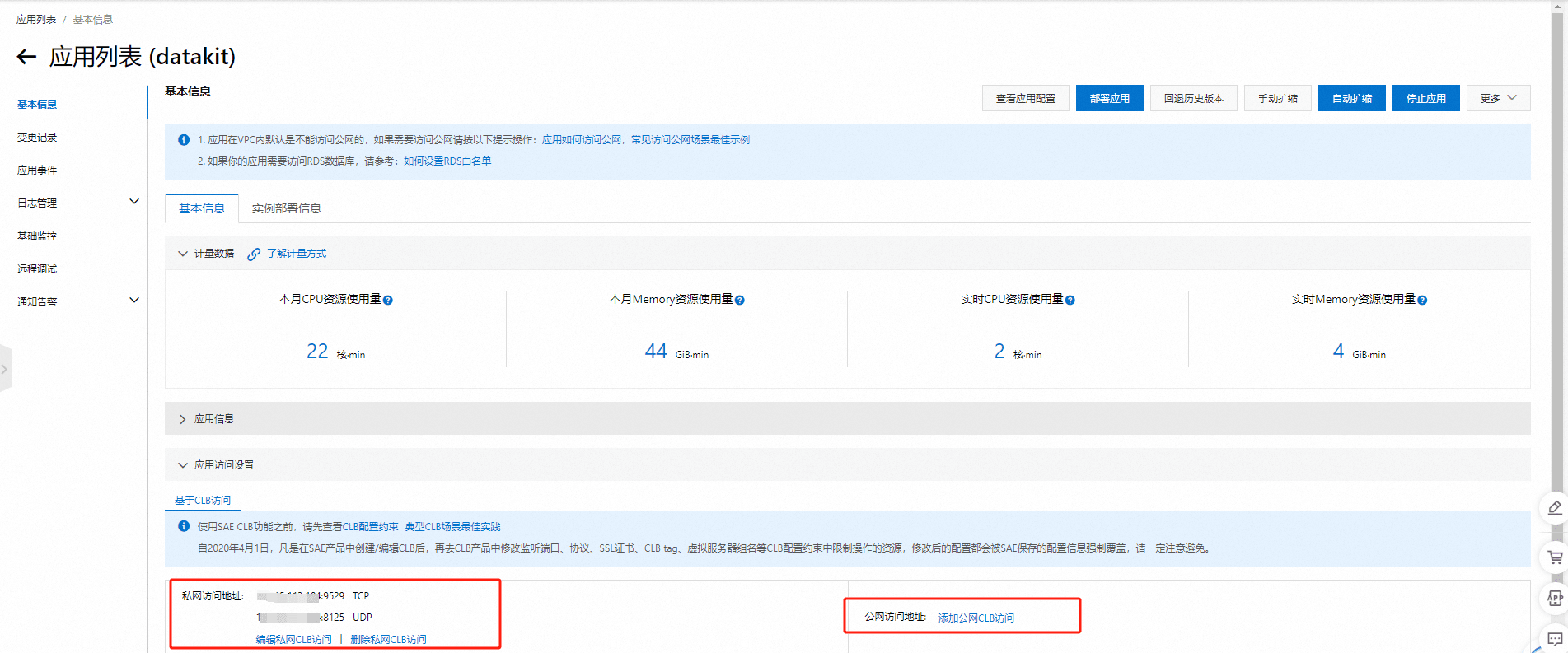
创建成功后,可以进入应用详情,查看基础信息。
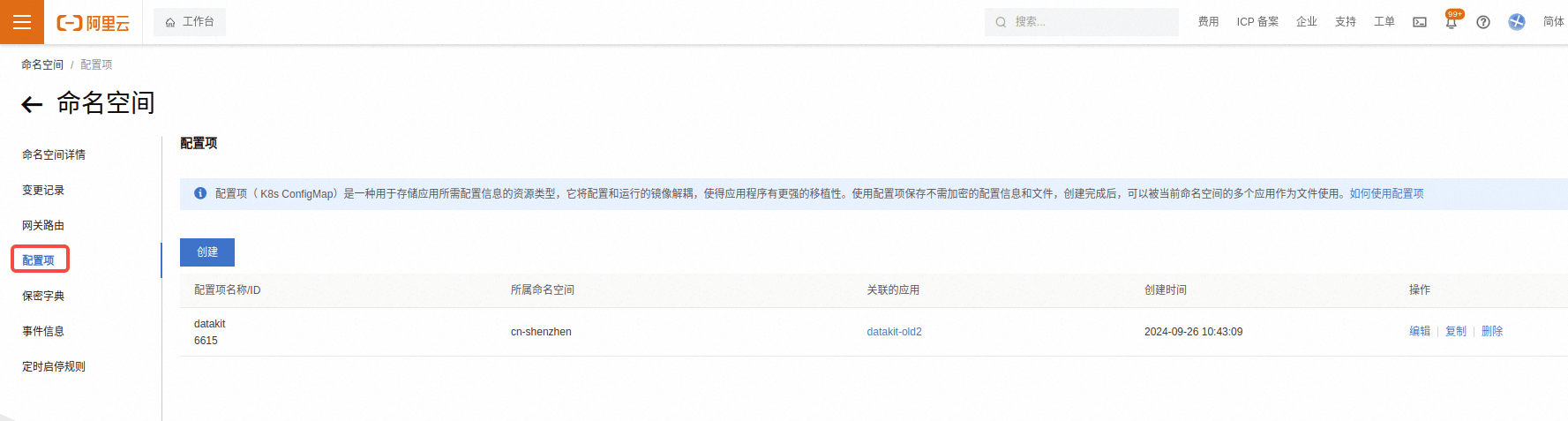
创建配置项
在 SAE 的命名空间里面配置。

配置项内容如下:
{
"ENV_DATAWAY": "https://openway.guance.com?token=tkn_xxx",
"KAFKAMQ": "# {\"version\": \"1.22.7-1510\", \"desc\": \"do NOT edit this line\"}\n\n[[inputs.kafkamq]]\n # addrs = [\"alikafka-serverless-cn-8ex3y7ciq02-1000.alikafka.aliyuncs.com:9093\",\"alikafka-serverless-cn-8ex3y7ciq02-2000.alikafka.aliyuncs.com:9093\",\"alikafka-serverless-cn-8ex3y7ciq02-3000.alikafka.aliyuncs.com:9093\"]\n addrs = [\"alikafka-serverless-cn-8ex3y7ciq02-1000-vpc.alikafka.aliyuncs.com:9092\",\"alikafka-serverless-cn-8ex3y7ciq02-2000-vpc.alikafka.aliyuncs.com:9092\",\"alikafka-serverless-cn-8ex3y7ciq02-3000-vpc.alikafka.aliyuncs.com:9092\"]\n # your kafka version:0.8.2 ~ 3.2.0\n kafka_version = \"3.3.1\"\n group_id = \"datakit-group\"\n # consumer group partition assignment strategy (range, roundrobin, sticky)\n assignor = \"roundrobin\"\n\n ## kafka tls config\n tls_enable = false\n\n ## -1:Offset Newest, -2:Offset Oldest\n offsets=-1\n\n\n ## user custom message with PL script.\n [inputs.kafkamq.custom]\n #spilt_json_body = true\n ## spilt_topic_map determines whether to enable log splitting for specific topic based on the values in the spilt_topic_map[topic].\n #[inputs.kafkamq.custom.spilt_topic_map]\n # \"log_topic\"=true\n # \"log01\"=false\n [inputs.kafkamq.custom.log_topic_map]\n \"springboot-server_log\"=\"springboot_log.p\"\n #[inputs.kafkamq.custom.metric_topic_map]\n # \"metric_topic\"=\"metric.p\"\n # \"metric01\"=\"rum_apm.p\"\n #[inputs.kafkamq.custom.rum_topic_map]\n # \"rum_topic\"=\"rum_01.p\"\n # \"rum_02\"=\"rum_02.p\"\n",
"SPRINGBOOT_LOG_P": "abc = load_json(_)\n\nadd_key(file, abc[\"file\"])\n\nadd_key(message, abc[\"message\"])\nadd_key(host, abc[\"host\"])\nmsg = abc[\"message\"]\ngrok(msg, \"%{TIMESTAMP_ISO8601:time} %{NOTSPACE:thread_name} %{LOGLEVEL:status}%{SPACE}%{NOTSPACE:class_name} - \\\\[%{NOTSPACE:method_name},%{NUMBER:line}\\\\] %{DATA:service_name} %{DATA:trace_id} %{DATA:span_id} - %{GREEDYDATA:msg}\")\n\nadd_key(topic, abc[\"topic\"])\n\ndefault_time(time,\"Asia/Shanghai\")",
"ENV_GLOBAL_HOST_TAGS": "host=__datakit_hostname,host_ip=__datakit_ip",
"ENV_HTTP_LISTEN": "0.0.0.0:9529",
"ENV_DEFAULT_ENABLED_INPUTS": "dk,cpu,disk,diskio,mem,swap,system,hostobject,net,host_processes,container,ddtrace,statsd,profile"
}
配置项说明:
- ENV_DATAWAY:上报观测云的网关地址
- KAFKAMQ: kafkamq 采集器配置,具体内容参考:Kafka 采集器配置文件介绍
- SPRINGBOOT_LOG_P:日志 pipeline 脚本,用于切割来自 kafka 的日志数据
- ENV_GLOBAL_HOST_TAGS: 采集器全局 tag
- ENV_HTTP_LISTEN:Datakit 端口,ip必须是 0.0.0.0 否则其他 pod 会访问不到
- ENV_DEFAULT_ENABLED_INPUTS: 默认开启的采集器
Kafka 采集器配置文件介绍
# {"version": "1.22.7-1510", "desc": "do NOT edit this line"}
[[inputs.kafkamq]]
# addrs = ["alikafka-serverless-cn-8ex3y7ciq02-1000.alikafka.aliyuncs.com:9093","alikafka-serverless-cn-8ex3y7ciq02-2000.alikafka.aliyuncs.com:9093","alikafka-serverless-cn-8ex3y7ciq02-3000.alikafka.aliyuncs.com:9093"]
addrs = ["alikafka-serverless-cn-8ex3y7ciq02-1000-vpc.alikafka.aliyuncs.com:9092","alikafka-serverless-cn-8ex3y7ciq02-2000-vpc.alikafka.aliyuncs.com:9092","alikafka-serverless-cn-8ex3y7ciq02-3000-vpc.alikafka.aliyuncs.com:9092"]
# your kafka version:0.8.2 ~ 3.2.0
kafka_version = "3.3.1"
group_id = "datakit-group"
# consumer group partition assignment strategy (range, roundrobin, sticky)
assignor = "roundrobin"
## kafka tls config
tls_enable = false
## -1:Offset Newest, -2:Offset Oldest
offsets=-1
## user custom message with PL script.
[inputs.kafkamq.custom]
#spilt_json_body = true
## spilt_topic_map determines whether to enable log splitting for specific topic based on the values in the spilt_topic_map[topic].
#[inputs.kafkamq.custom.spilt_topic_map]
# "log_topic"=true
# "log01"=false
[inputs.kafkamq.custom.log_topic_map]
"springboot-server_log"="springboot_log.p"
#[inputs.kafkamq.custom.metric_topic_map]
# "metric_topic"="metric.p"
# "metric01"="rum_apm.p"
#[inputs.kafkamq.custom.rum_topic_map]
# "rum_topic"="rum_01.p"
# "rum_02"="rum_02.p"
addrs:kafka 队列消费地址group_id:消费组,DataKit 会调用 kafka 自动创建[inputs.kafkamq.custom.log_topic_map]:是 kafkamq 日志类型数据消费 Topic 配置集合,可以配置多组,key-value 形式。key 为 Topic ,value 可以为空,为空用""表示,如果需要做日志切割,则需要填写对应的 pipeline 名称。
网络配置
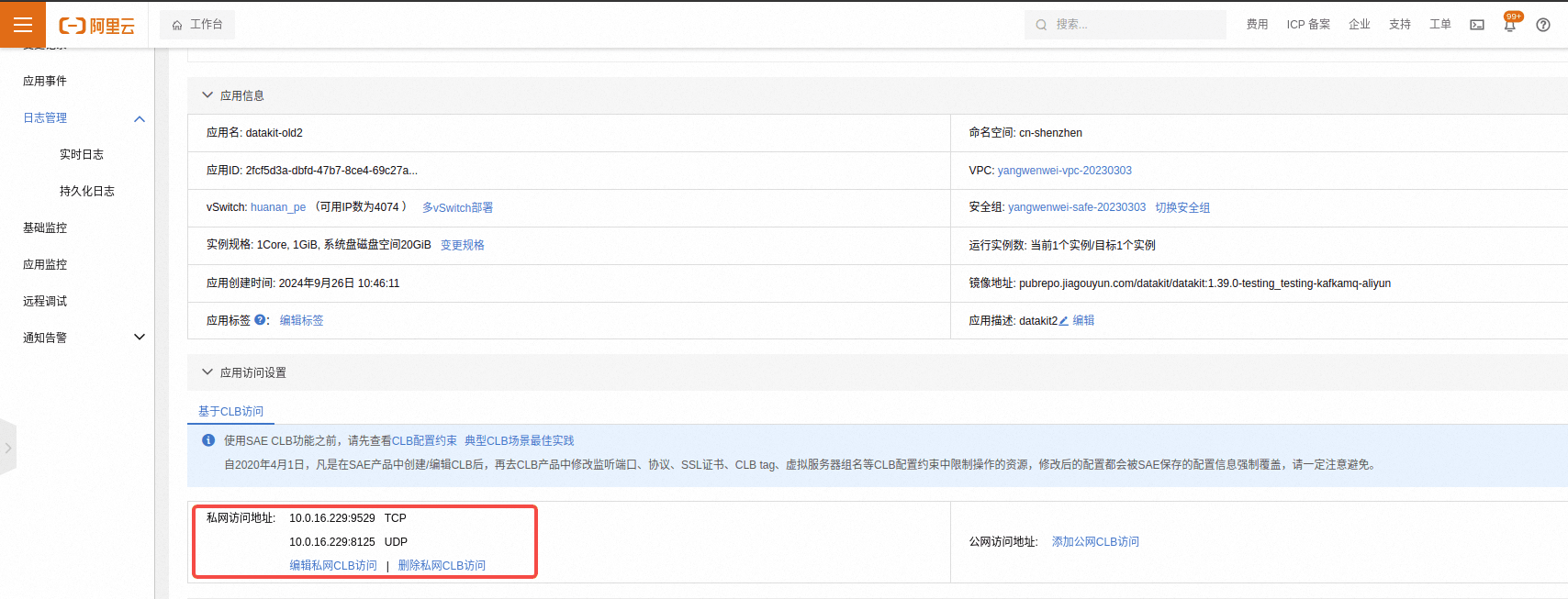
按需开启网络,公网或者私网,一般建议私网即可。
主要开放两个端口 9529 和 8125 ,有其他端口需求的可以按需添加。开启后会生成 ip 和端口,后面会用到。
应用
示例为 Java 应用,采用 ddtrace 作为 APM 进行接入。Demo 源码地址:https://github.com/lrwh/observable-demo/tree/main/springboot-server。
可以自己构建镜像,也可以使用阿里镜像 registry.cn-shenzhen.aliyuncs.com/lr_715377484/springboot-server:ddtrace_1_34
下载 ddtrace
wget https://static.guance.com/dd-image/dd-java-agent.jar
docker 镜像
FROM openjdk:8-jdk-alpine
# 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp
VOLUME /tmp
WORKDIR /data
RUN mkdir logs
# 这个目录自行修改
ADD springboot-server.jar app.jar
ADD dd-java-agent-v1.34.0-guance.jar /dd-java-agent.jar
# 修改时区
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 解决中文乱码
ENV LANG en_US.UTF-8
ENV jar app.jar
ENTRYPOINT ["sh", "-ec", "exec java ${JAVA_OPTS} -jar ${jar} ${PARAMS} 2>&1"]
构建:
docker build -f Dockerfile_ddtrace -t registry.cn-shenzhen.aliyuncs.com/lr_715377484/springboot-server:ddtrace_1_34 .
推送到仓库:
docker push registry.cn-shenzhen.aliyuncs.com/lr_715377484/springboot-server:ddtrace_1_34
创建应用
基本步骤与创建 DataKit 一样。
- 调整镜像名称
- 镜像地址:
registry.cn-shenzhen.aliyuncs.com/lr_715377484/springboot-server:ddtrace_1_34 - Java 环境选择
openjdk8 - 启动命令设置:选择 Shell 脚本方式
java \
-javaagent:/dd-java-agent.jar \
-Ddd.service.name=ddtrace-server \
-Ddd.agent.host=10.0.16.221 \
-Ddd.agent.port=9529 \
-Ddd.trace.debug=true \
-Ddatadog.slf4j.simpleLogger.logFile=ddtrace.log \
-jar /data/app.jar
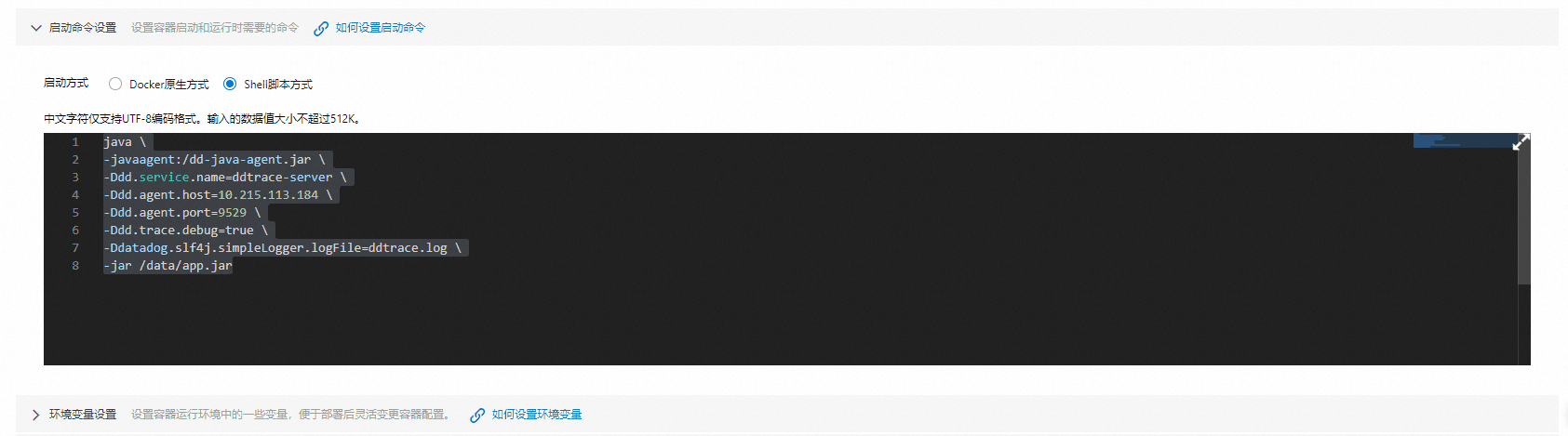
其中 -Ddd.agent.host 为 DataKit 的访问地址。
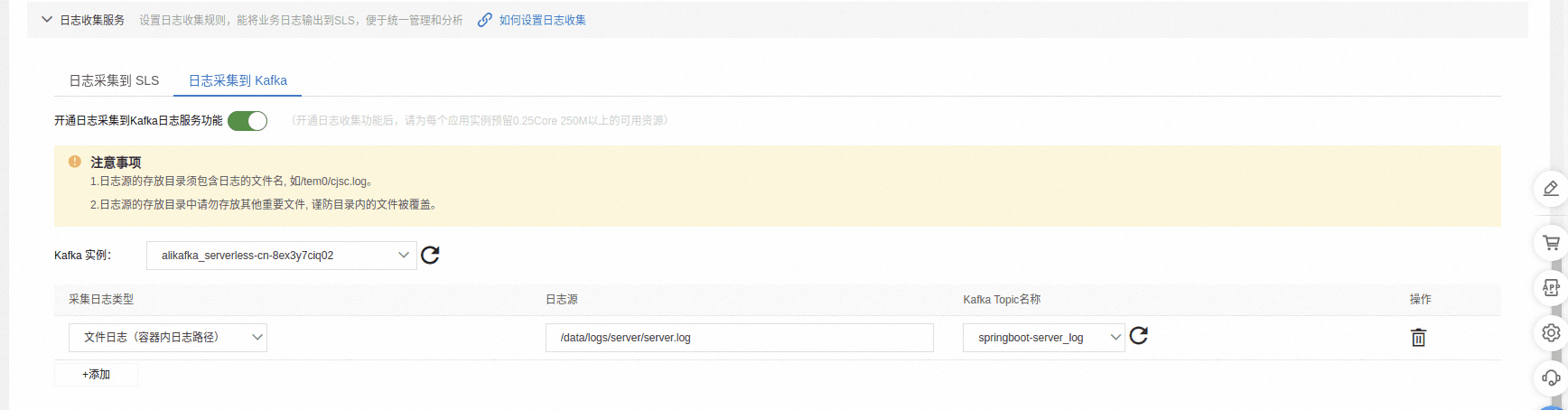
- 日志采集服务
将日志上报到 kafka,选择对应的 kafka 实例,没有就创建一个,并填写对应的日志文件路径及上报 kafka 的 topic。
- 保存
应用启动完成后,可以在应用实例部署信息查看部署和启动日志。
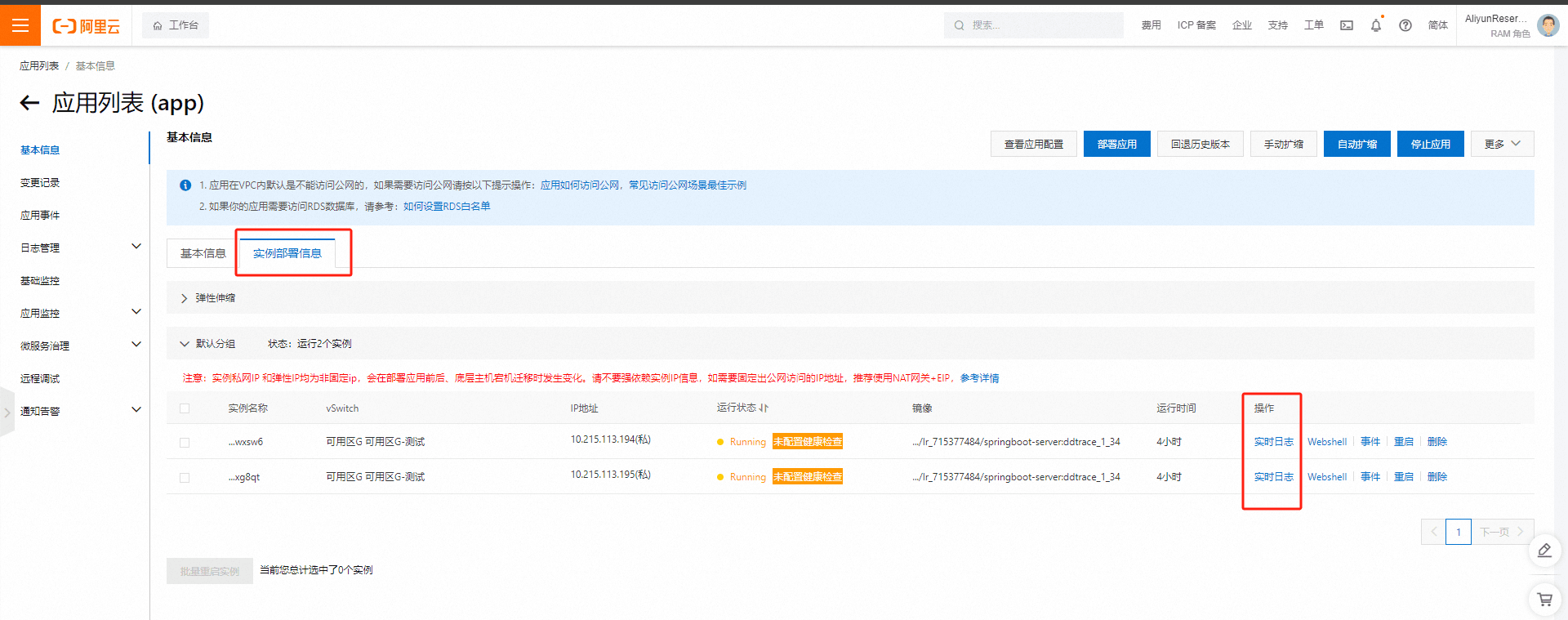
从日志里面已经可以看到 ddtrace 加载成功。
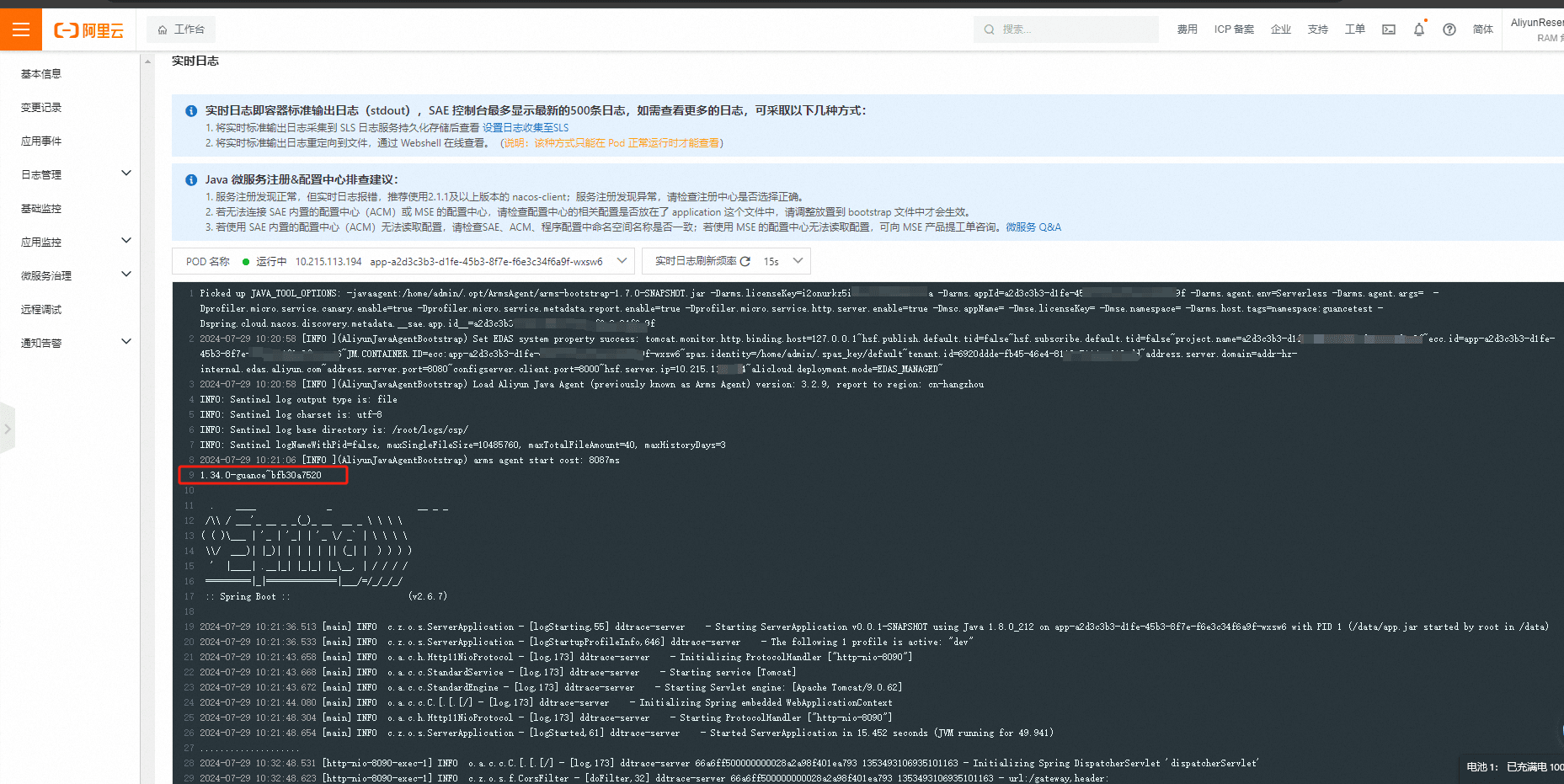
开启网络
应用启动完成后,按需开启网络,公网或者私网,由于这里需要对外访问,所以需要开放公网。当前应用端口为8090。开放成功后可以直接通过ip地址可以访问。
curl http://host:8090/gateway
效果展示
日志
在日志列表上,可以通过 source:springboot-server_log 来过滤当前业务日志,点击对应的日志详情,可以关联当前日志对应的链路信息。
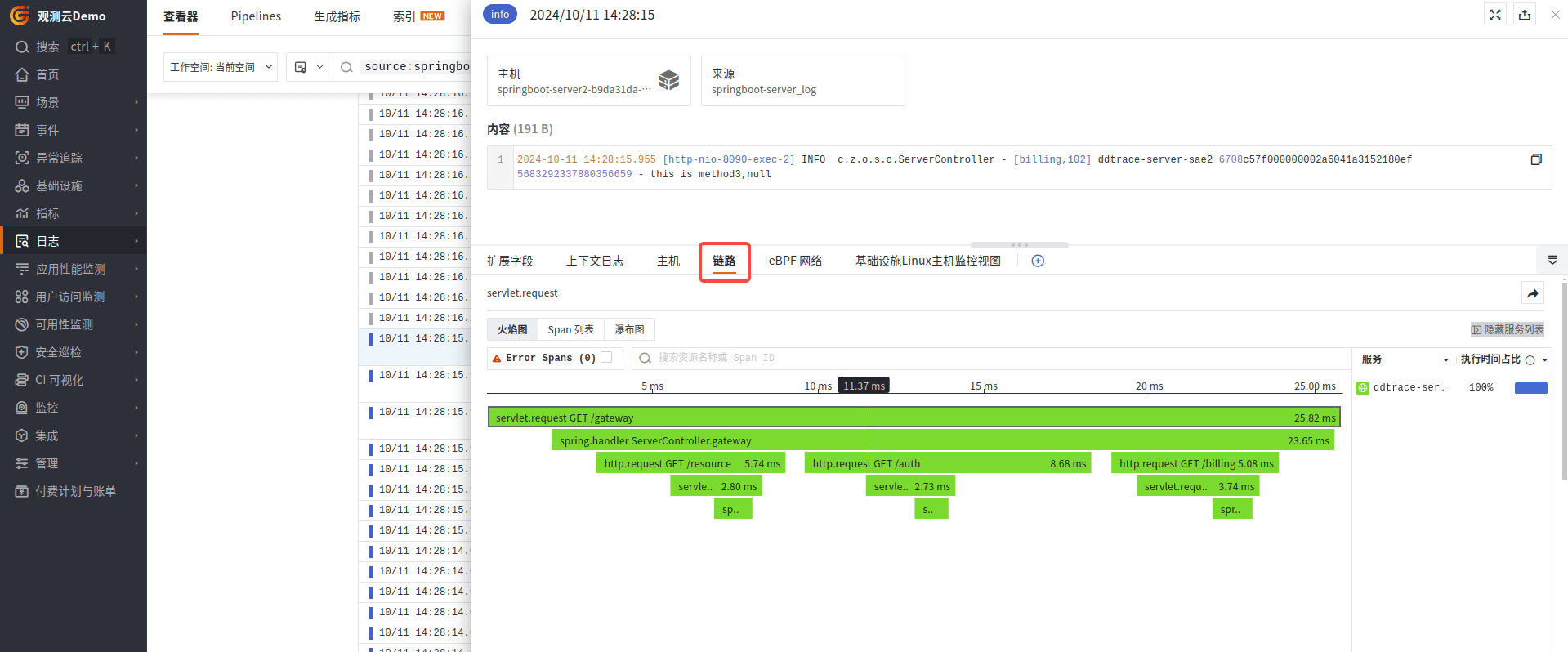
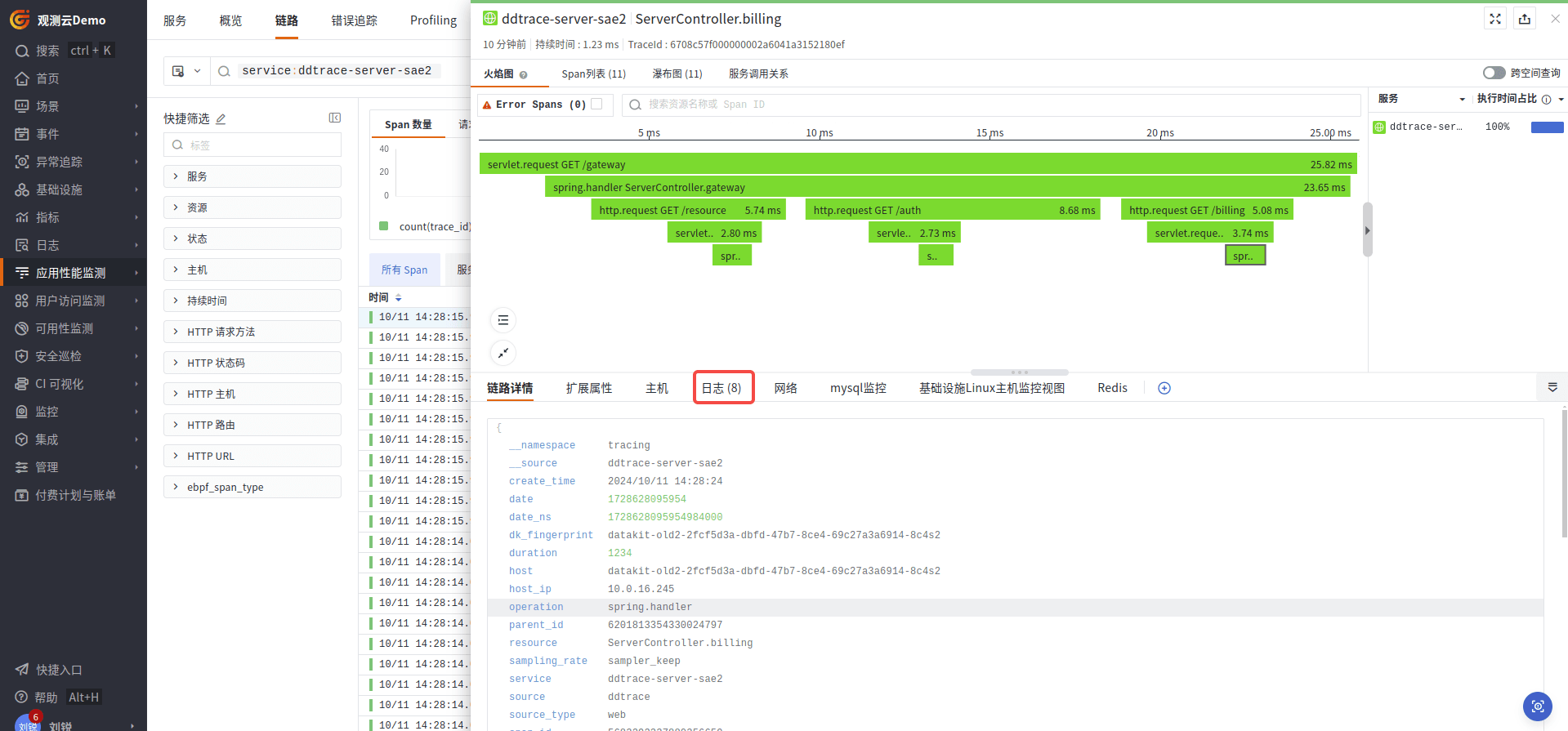
链路
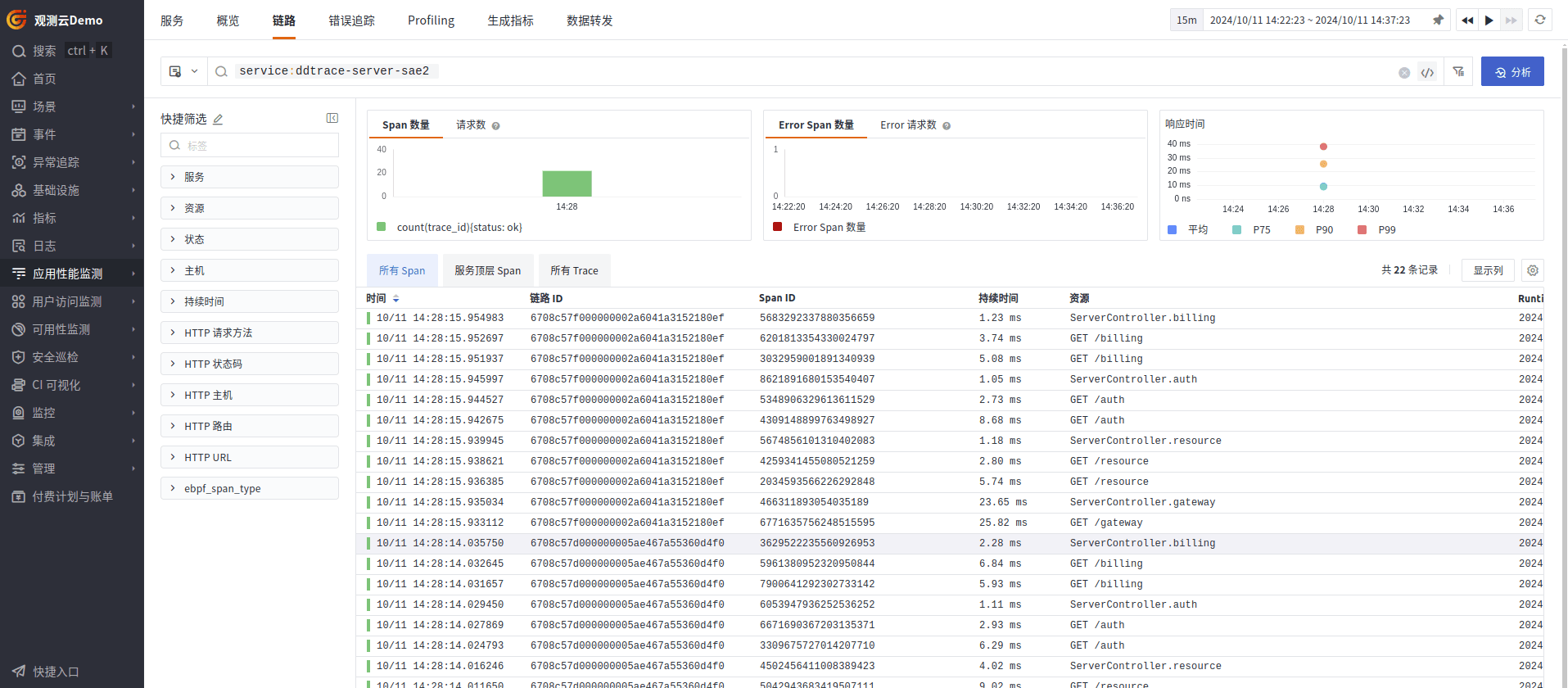
在链路详情里面,可以关联到当前链路对应业务所产生的日志信息。
指标
指标采集
由于阿里云不提供直接从 prometheus 获取指标数据,所以需要通过观测云 Function 平台(DataFlux.f(x))调用 SAE 的 API 采集指标数据。
具体步骤参考:阿里云 SAE 集成文档
指标列表
| 指标 | 单位 | Dimensions | 描述 |
|---|---|---|---|
cpu_Average |
% | userId、appId | 应用CPU |
diskIopsRead_Average |
Count/Second | userId、appId | 应用磁盘IOPS读 |
diskIopsWrite_Average |
Count/Second | userId、appId | 应用磁盘IOPS写 |
diskRead_Average |
Byte/Second | userId、appId | 应用磁盘IO吞吐率读 |
diskTotal_Average |
Kilobyte | userId、appId | 应用磁盘总量 |
diskUsed_Average |
Kilobyte | userId、appId | 应用磁盘使用量 |
diskWrite_Average |
Byte/Second | userId、appId | 应用磁盘IO吞吐率写 |
instanceId_memoryUsed_Average |
MB | userId、appId、instanceId | 实例已使用内存 |
instance_cpu_Average |
% | userId、appId、instanceId | 实例CPU |
instance_diskIopsRead_Average |
Count/Second | userId、appId、instanceId | 实例磁盘IOPS读 |
instance_diskIopsWrite_Average |
Count/Second | userId、appId、instanceId | 实例磁盘IOPS写 |
instance_diskRead_Average |
Byte/Second | userId、appId、instanceId | 实例磁盘IO吞吐率读 |
instance_diskTotal_Average |
Kilobyte | userId、appId、instanceId | 实例磁盘总量 |
instance_diskUsed_Average |
Kilobyte | userId、appId、instanceId | 实例磁盘使用量 |
instance_diskWrite_Average |
Byte/Second | userId、appId、instanceId | 实例磁盘IO吞吐率写 |
instance_load_Average |
min | userId、appId、instanceId | 实例平均负载 |
instance_memoryTotal_Average |
MB | userId、appId、instanceId | 实例总内存 |
instance_memoryUsed_Average |
MB | userId、appId、instanceId | 实例已使用内存 |
instance_netRecv_Average |
Byte/Second | userId、appId、instanceId | 实例接收字节 |
instance_netRecvBytes_Average |
Byte | userId、appId、instanceId | 实例总接收字节 |
instance_netRecvDrop_Average |
Count/Second | userId、appId、instanceId | 实例接收数据丢包 |
instance_netRecvError_Average |
Count/Second | userId、appId、instanceId | 实例接收错误数据包 |
instance_netRecvPacket_Average |
Count/Second | userId、appId、instanceId | 实例接收数据包 |
instance_netTran_Average |
Byte/Second | userId、appId、instanceId | 实例发送字节 |
instance_netTranBytes_Average |
Byte | userId、appId、instanceId | 实例总发送字节 |
instance_netTranDrop_Average |
Count/Second | userId、appId、instanceId | 实例发送数据丢包 |
instance_netTranError_Average |
Count/Second | userId、appId、instanceId | 实例发送错误数据包 |
instance_netTranPacket_Average |
Count/Second | userId、appId、instanceId | 实例发送数据包 |
instance_tcpActiveConn_Average |
Count | userId、appId、instanceId | 实例活跃TCP连接数 |
instance_tcpInactiveConn_Average |
Count | userId、appId、instanceId | 实例非活跃TCP连接数 |
instance_tcpTotalConn_Average |
Count | userId、appId、instanceId | 实例总TCP连接数 |
load_Average |
min | userId、appId | 应用平均负载 |
memoryTotal_Average |
MB | userId、appId | 应用总内存 |
memoryUsed_Average |
MB | userId、appId | 应用已使用内存 |
netRecv_Average |
Byte/Second | userId、appId | 应用接收字节 |
netRecvBytes_Average |
Byte | userId、appId | 应用总接收字节 |
netRecvDrop_Average |
Count/Second | userId、appId | 应用接收数据丢包 |
netRecvError_Average |
Count/Second | userId、appId | 应用接收错误数据包 |
netRecvPacket_Average |
Count/Second | userId、appId | 应用接收数据包 |
netTran_Average |
Byte/Second | userId、appId | 应用发送字节 |
netTranBytes_Average |
Byte | userId、appId | 应用总发送字节 |
netTranDrop_Average |
Count/Second | userId、appId | 应用发送数据丢包 |
netTranError_Average |
Count/Second | userId、appId | 应用发送错误数据包 |
netTranPacket_Average |
Count/Second | userId、appId | 应用发送数据包 |
tcpActiveConn_Average |
Count | userId、appId | 应用活跃TCP连接数 |
tcpInactiveConn_Average |
Count | userId、appId | 应用非活跃TCP连接数 |
tcpTotalConn_Average |
Count | userId、appId | 应用总TCP连接数 |
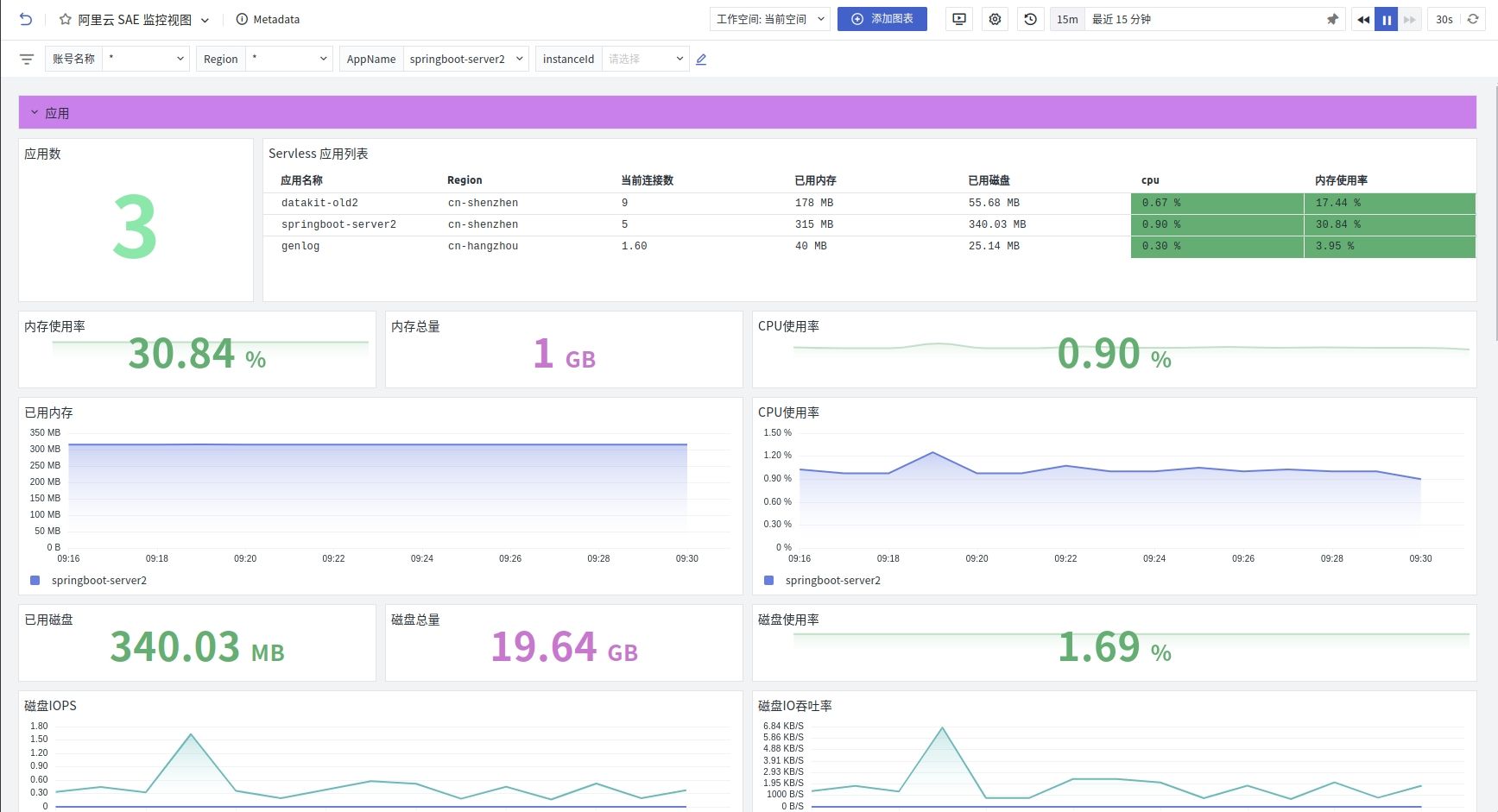
仪表板
- 应用
- 实例

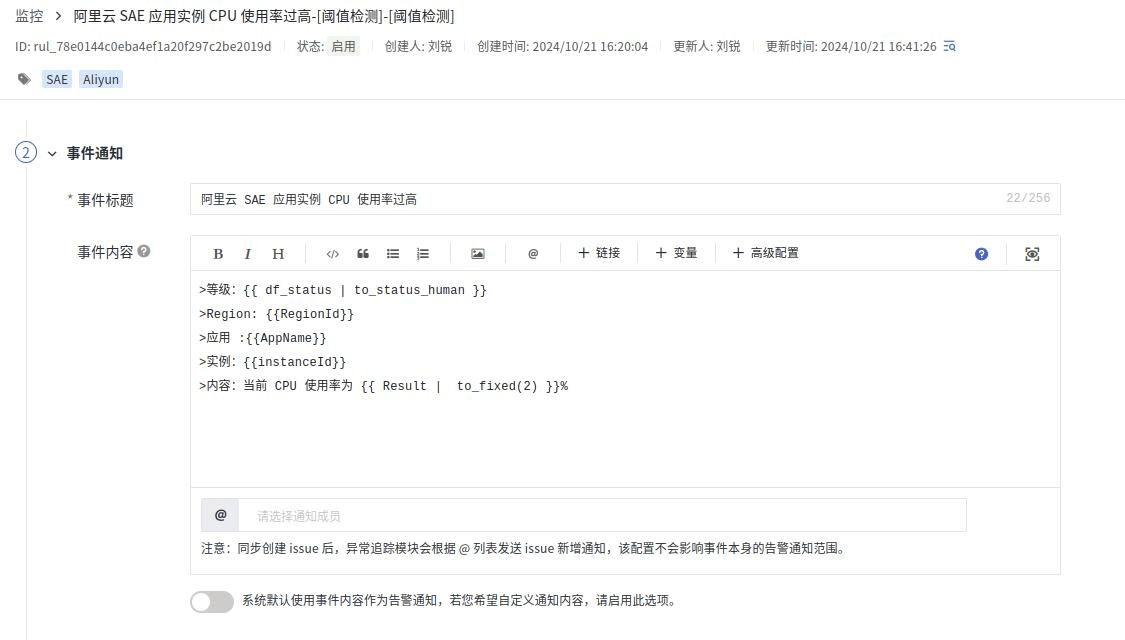
监控器
内置了一部分 SAE 监控器,方便对 SAE 应用进行监控。
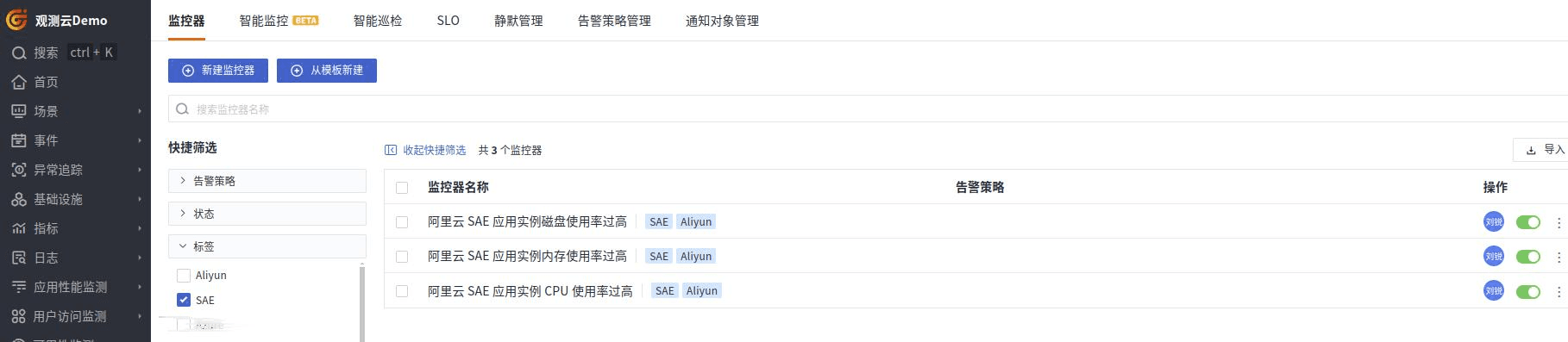
模板内容可以调整。