


接触PyODPS一年之后,现在已经是高端写手了。但仍然有解决不了的问题:
odps没有network,不能和在线配置联动。比如我就有个需求,需要根据在线配置动态决定每天什么上线什么下架。获取根据在线配置动态获取业务关系,用于离线业务处理。
odps没有network,不能在强大的pyodps里按行处理数据并上传oss文件。并把url写入到数据表中。
odps不能接入图片处理/算法能力,离线处理数据。
基于以上,我简单研究了一下PAI-Designer,实现了几个需求。这里分享一下经验~
如何写出来一套牛逼哄哄的万能的离线处理PAI:

初始之地:创建工作流
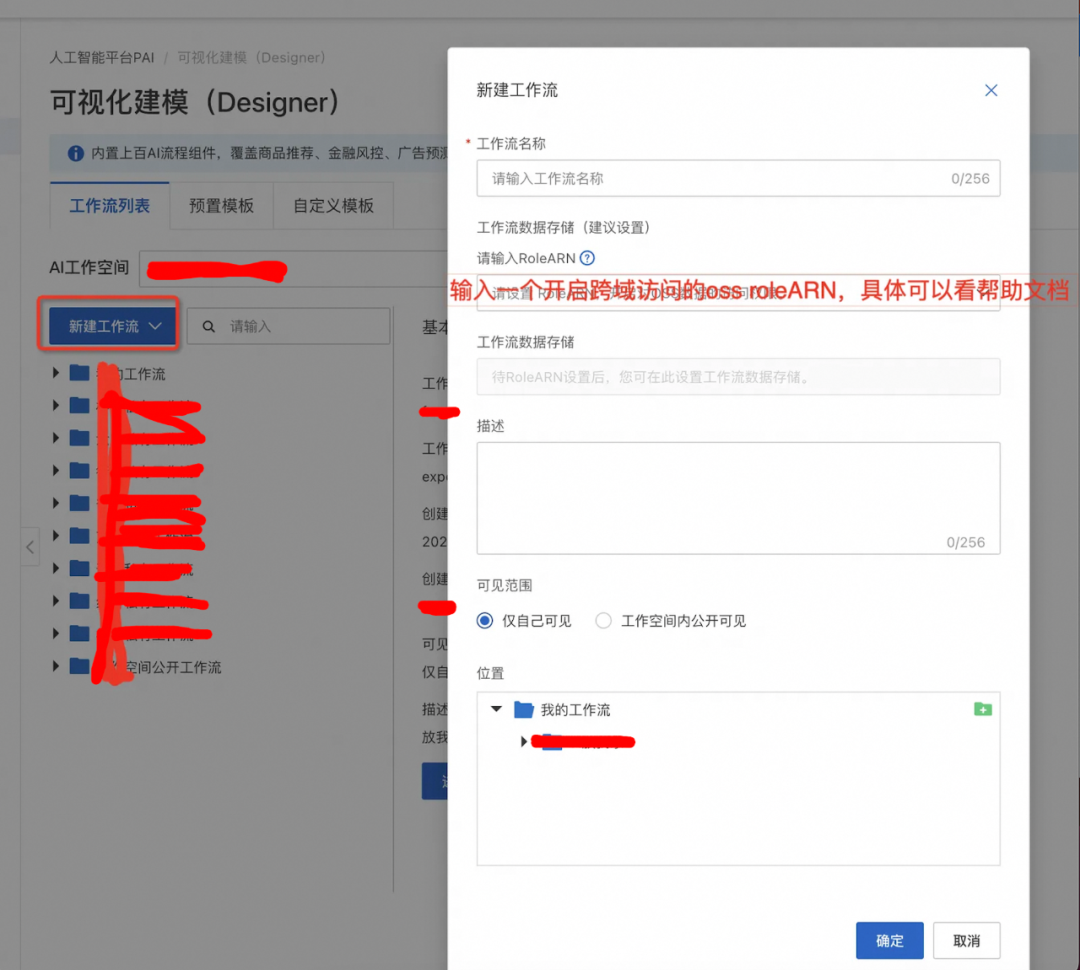
OSS RoleARN看?获取帮助~

嗯,没有这玩意,你写不了代码。

第一个Python脚本
拖一个python脚本出来,在左侧栏的自定义脚本中:
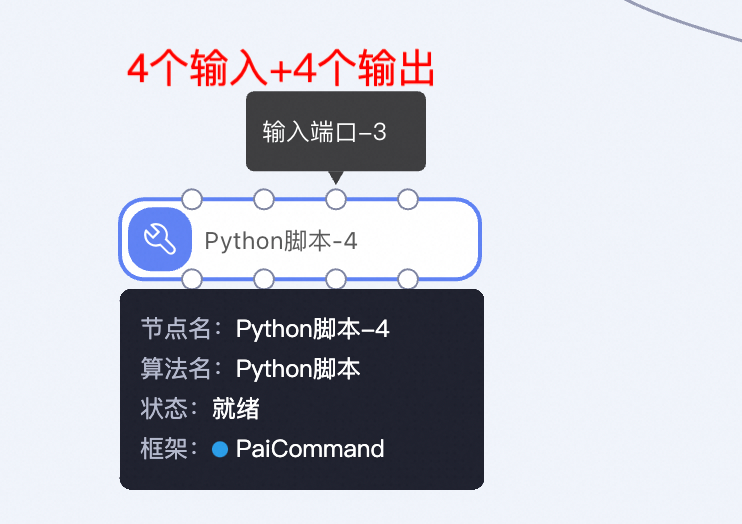
这里可以看到只有4个输入+4个输出,明显是被限制了上下游依赖,这是明示咱们写代码模块划分清晰,每个模块单一职责不要太多代码~
不得不说,pai的这个代码模板写得真好:
import osimport argparseimport json"""Python脚本组件示例代码"""# 当前工作空间下的默认MaxCompute执行环境,包含MaxComputeProject的名称以及Endpoint.# 需要当前的工作空间下有MaxCompute项目时,作业的执行环境才会注入。# 示例: {"endpoint": "http://service.cn.maxcompute.aliyun-inc.com/api", "odpsProject": "lq_test_mc_project"}ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION"def init_odps():"""初始化一个ODPS实例,用于读写MaxCompute数据.具体API请参考PyODPS的文档: https://pyodps.readthedocs.io/"""from odps import ODPS# 当前工作空间的默认MaxCompute项目信息.mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION])o = ODPS(access_id="<YouAccessKeyId>", # ODPS的AccessKeysecret_access_key="<YourAccessKeySecret>", # ODPS的AccessSecret# 请根据Project所在的Region选择: https://help.aliyun.com/document_detail/34951.htmlendpoint=mc_execution["endpoint"],project=mc_execution["odpsProject"],)return odef parse_odps_url(table_uri):"""解析输入的MaxCompute Table URI需要打开的MaxCompute表名,格式为odps://${your_projectname}/tables/${table_name}/${pt_1}/${pt_2}/示例:odps://test/tables/iris/pa=1/pb=1,其中pa=1/pb=1是一个多级partition。Returns:返回三元组(ProjectName, TableName, Partition)"""from urllib import parseparsed = parse.urlparse(table_uri)project_name = parsed.hostnamer = parsed.path.split("/", 2) # 这里血坑,注意把这里的2改成3!!!!!!!!可能是代码错误?table_name = r[2]if len(r) > 3:partition = r[3]else:partition = Nonereturn project_name, table_name, partitiondef parse_args():"""解析给到脚本的arguments."""parser = argparse.ArgumentParser(description="Python component script example.")# 从上游连线输入当前组件端口的输入,会通过arguments的方式传递给到执行的脚本# 1. 组件输入# - OSS的输入:# 来自上游组件的OSS输入,会被挂载到脚本执行的节点上, 然后挂载后的文件路径,会arguments的形式,传递给到运行的脚本。# 例如 "python main.py --input1 /ml/input/data/input1 "# - MaxComputeTable的输入:# MaxComputeTable的输入不支持挂载,对应的Table信息会以URI的形式,作为arguments传递给到运行脚本# 例如 "python main.py --input1 odps://some-project-name/tables/table# 对于ODPS URI形式输入,可以用示例的parse_odps_url函数解析出对应的元信息。parser.add_argument("--input1", type=str, default=None, help="Component input port 1.")parser.add_argument("--input2", type=str, default=None, help="Component input port 2.")parser.add_argument("--input3", type=str, default=None, help="Component input port 3.")parser.add_argument("--input4", type=str, default=None, help="Component input port 4.")# 组件输出# - OSS输出# 组件的输出端口1和输出端口2是两个OSS输出端口,可以用于下游的使用OSS路径作为输入的组件。# 配置组件输出任务输出路径,对应的输出目录会被挂载到 /ml/output/ 下。# 组件的输出端口 "OSS输出-1"和"OSS输出-2",分别对应子目录/ml/output/output1 和 ml/output/output2。# - MaxComputeTable的输出# 组件的输出端口3和输出端口4是MaxComputeTable输出.# 如果当前的工作空间配置了MaxComputeProject项目,则组件传递一个临时表URI给到脚本。# 例如 python main.py --output3 odps://<some-project-name>/tables/<output-table-name># 用户的代码可以构建对应的表,写出数据到对应表,然后通过组件连线将表传递给到下游组件。parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.")parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.")parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.")parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.")args, _ = parser.parse_known_args()return argsdef write_table_example(args):"""示例:复制将PAI提供公共表的数据,作为当前组件的临时表输出:更多PyODPS请参考PyODPS文档: https://pyodps.readthedocs.io/"""output_table_uri = args.output3o = init_odps()project_name, table_name, partition = parse_odps_url(output_table_uri)o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;")def write_output1(args):"""将数据结果写入Mount的OSS路径上(output1子目录),对应的结果可以通过连线传递到下游"""output_path = args.output1os.makedirs(output_path, exist_ok=True)p = os.path.join(output_path, "result.text")with open(p, "w") as f:f.write("TestAccuracy=0.88")if __name__ == "__main__":args = parse_args()print("Input1={}".format(args.input1))print("Output1={}".format(args.output1))# write_table_example(args)# write_output1(args)
模板的注释解释的贼清楚,这里就不多赘述了,之所以写这个文章,主要是想分享一下常用的几种Python脚本模板。

在线配置读取
在线配置选型选择了MT3:
用过的同学会发现配置文件都在CDN上,预发配置文件一个地址,线上配置文件一个地址。
可以直接用requests来拉cdn文件。
对应的pai脚本模板代码:
import requestsimport osimport argparseimport json# parse_args与模板一致.def parse_args():parser = argparse.ArgumentParser(description="Python component script example.")parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.")args, _ = parser.parse_known_args()return args# 目标 URLurl = "https://xxx.alicdn.com/fpi/xxxx-data/v1/xxx-config.js?"# 发送 HTTP GET 请求response = requests.get(url)# 检查请求是否成功if response.status_code == 200:# 将响应内容写入文件args = parse_args()"""将数据结果写入Mount的OSS路径上(output1子目录),对应的结果可以通过连线传递到下游"""os.makedirs(args.output1, exist_ok=True)p = os.path.join(args.output1, "result.txt") # 代码里写入的output1,拉线的时候要从output1拉出~with open(p, "wb") as f:f.write(response.content)else:# 失败及时终止任务raise Exception("DIY C端配置读取失败")
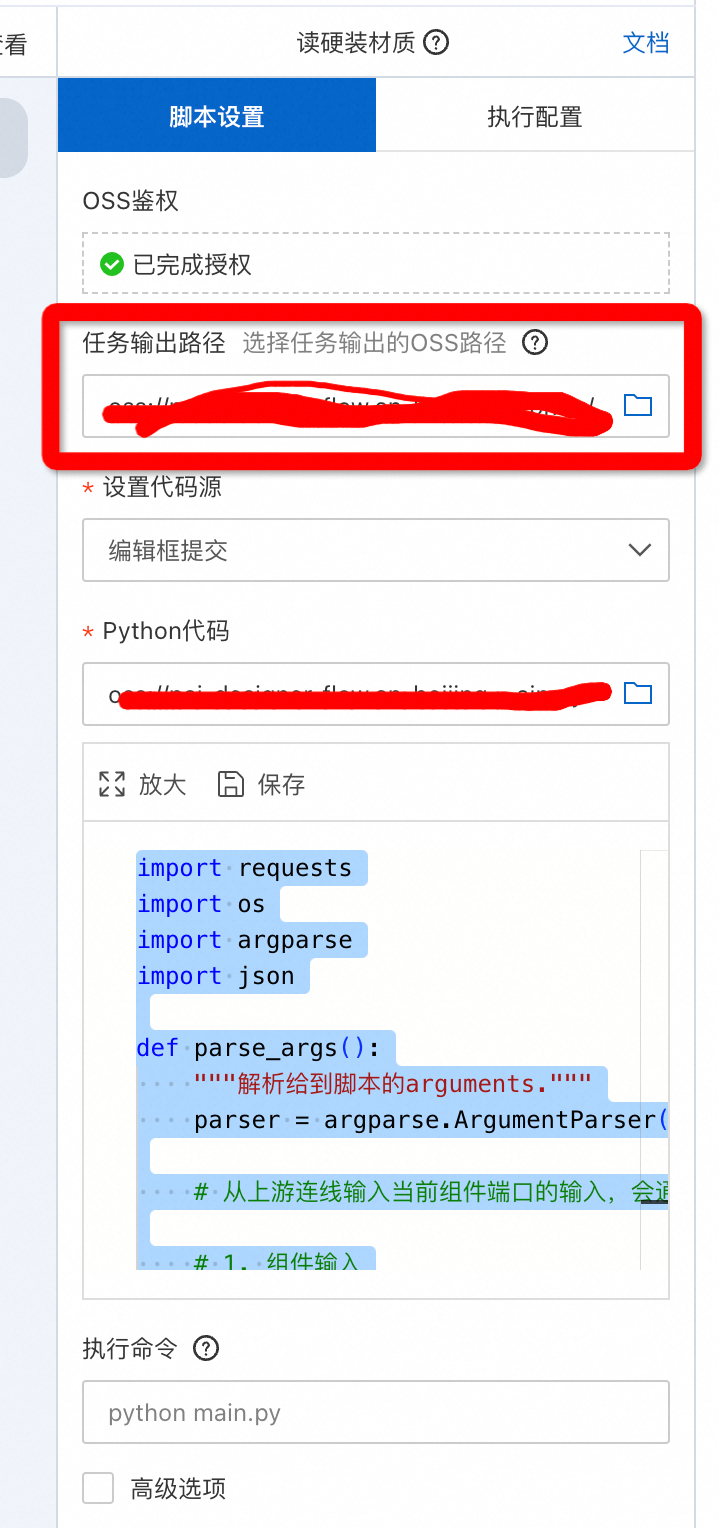
写完代码记得给python脚本的模块配置一个OSS目录。

import argparseimport jsonimport osfrom odps import ODPS, optionsfrom odps.df import DataFrame, Scalar, agg, func, outputoptions.lifecycle=7"""Python脚本组件示例代码"""# 当前工作空间下的默认MaxCompute执行环境,包含MaxComputeProject的名称以及Endpoint.# 需要当前的工作空间下有MaxCompute项目时,作业的执行环境才会注入。# 示例: {"endpoint": "http://service.cn.maxcompute.aliyun-inc.com/api", "odpsProject": "lq_test_mc_project"}ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION"def init_odps():"""初始化一个ODPS实例,用于读写MaxCompute数据.具体API请参考PyODPS的文档: https://pyodps.readthedocs.io/"""# 当前工作空间的默认MaxCompute项目信息.mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION])o = ODPS(access_id="",secret_access_key="",# 请根据Project所在的Region选择: https://help.aliyun.com/document_detail/34951.htmlendpoint=mc_execution["endpoint"],project=mc_execution["odpsProject"],)return odef parse_odps_url(table_uri):"""解析输入的MaxCompute Table URI需要打开的MaxCompute表名,格式为odps://${your_projectname}/tables/${table_name}/${pt_1}/${pt_2}/示例:odps://test/tables/iris/pa=1/pb=1,其中pa=1/pb=1是一个多级partition。Returns:返回三元组(ProjectName, TableName, Partition)"""from urllib import parseparsed = parse.urlparse(table_uri)project_name = parsed.hostnamer = parsed.path.split("/", 3)table_name = r[2]if len(r) > 3:partition = r[3]else:partition = Nonereturn project_name, table_name, partitiondef parse_args():"""解析给到脚本的arguments."""parser = argparse.ArgumentParser(description="Python component script example.")# 从上游连线输入当前组件端口的输入,会通过arguments的方式传递给到执行的脚本# 1. 组件输入# - OSS的输入:# 来自上游组件的OSS输入,会被挂载到脚本执行的节点上, 然后挂载后的文件路径,会arguments的形式,传递给到运行的脚本。# 例如 "python main.py --input1 /ml/input/data/input1 "# - MaxComputeTable的输入:# MaxComputeTable的输入不支持挂载,对应的Table信息会以URI的形式,作为arguments传递给到运行脚本# 例如 "python main.py --input1 odps://some-project-name/tables/table# 对于ODPS URI形式输入,可以用示例的parse_odps_url函数解析出对应的元信息。parser.add_argument("--input1", type=str, default=None, help="Component input port 1.")parser.add_argument("--input2", type=str, default=None, help="Component input port 2.")parser.add_argument("--input3", type=str, default=None, help="Component input port 3.")parser.add_argument("--input4", type=str, default=None, help="Component input port 4.")# 组件输出# - OSS输出# 组件的输出端口1和输出端口2是两个OSS输出端口,可以用于下游的使用OSS路径作为输入的组件。# 配置组件输出任务输出路径,对应的输出目录会被挂载到 /ml/output/ 下。# 组件的输出端口 "OSS输出-1"和"OSS输出-2",分别对应子目录/ml/output/output1 和 ml/output/output2。# - MaxComputeTable的输出# 组件的输出端口3和输出端口4是MaxComputeTable输出.# 如果当前的工作空间配置了MaxComputeProject项目,则组件传递一个临时表URI给到脚本。# 例如 python main.py --output3 odps://<some-project-name>/tables/<output-table-name># 用户的代码可以构建对应的表,写出数据到对应表,然后通过组件连线将表传递给到下游组件。parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.")parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.")parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.")parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.")args, _ = parser.parse_known_args()return argsdef merge_item(args):"""示例:复制将PAI提供公共表的数据,作为当前组件的临时表输出:更多PyODPS请参考PyODPS文档: https://pyodps.readthedocs.io/"""config = None # 这里是读OSS的配置,这个oss的配置是一段文本,可以直接加载进来用。with open(args.input3 + "/result.txt") as f:config = json.loads(f.read())o = init_odps()(item_project_name,item_table_name,item_partition,) = parse_odps_url(args.input1)output_project, output_table_name, output_partition = parse_odps_url(args.output3)# 这里的item表来自组件《读数据表》item_table = DataFrame(o.get_table(f"{item_project_name}.{item_table_name}").get_partition(item_partition))# 如果不想要依赖某个表,可以用get_max_partition()取一个最大的分区。room_table = DataFrame(o.get_table("project.room_table").get_max_partition())t = item_table.left_join(room_table, on=[item_table.room_id == room_table.id])def handle_value(row):import urllib.parse# url格式是%2D,这种urlencode的格式,这里做一下decode.yield {"sku_id": row.sku_id,"url": urllib.parse.unquote(row.url)}t = t[t.item_id,t.apply(handle_value, axis = 1)]## 做一些超绝的数据聚合,避免重复,如何选择数据。class Agg(object):def buffer(self):# 第一个对象是以RoomId为key,值为url路径列表的value# 第二个对象是以RoomId为key,值为skuId列表的value# 第三个对象是以skuId为key,值为url路径的value# 目标:让尽可能多的skuId都在同一个RoomId下。return {"roomid_2_url_list": {},"roomid_2_skuid_list": {},"skuid_2_url": {}}def __call__(self, buffer, value):value = json.loads(value)if value["sku_id"] not in buffer["skuid_2_url"].keys():buffer["skuid_2_url"][value["sku_id"]]= valueif value["room_id"] not in buffer[roomid_2_url_list]:buffer["roomid_2_url_list"][value["room_id"]] = [value]buffer["roomid_2_skuid_list"][value["room_id"]] = [value["sku_id"]]else:if value["sku_id"] not in buffer["roomid_2_skuid_list"][value["room_id"]]:buffer["roomid_2_url_list"][value["room_id"]].append(value)buffer["roomid_2_skuid_list"][value["room_id"]].append(value["sku_id"])def merge(self, buffer, pbuffer):for room_id, value_list in pbuffer[0].items():if room_id not in buffer["roomid_2_url_list"].keys():buffer["roomid_2_url_list"][room_id] = pbuffer["roomid_2_url_list"][room_id]buffer["roomid_2_skuid_list"][room_id] = pbuffer["roomid_2_skuid_list"][room_id]continuefor i in range(0, len(value_list)):if pbuffer["roomid_2_skuid_list"][room_id][i] not in buffer["roomid_2_skuid_list"][room_id]:buffer["roomid_2_url_list"][room_id].append(pbuffer["roomid_2_url_list"][room_id][i])buffer["roomid_2_skuid_list"][room_id].append(pbuffer["roomid_2_skuid_list"][room_id][i])for sku_id, value in pbuffer["skuid_2_url"].items():if sku_id not in buffer["skuid_2_url"].keys():buffer["skuid_2_url"][sku_id]= valuedef getvalue(self, buffer):res = []# 优先roomId最多的那个组合,剩下的随机取一个。for room_id, value_list in buffer[0].items():if len(value_list) > len(res):res = value_listall_ready_sku_id = [x["skuId"] for x in res]for x, v in buffer[2].items():if x not in all_ready_sku_id:# 从剩余的数据里随便挑一个.res.append(v)return json.dumps(res)to_agg = agg([t.value], Agg, rtype='string')t=t.groupby("item_id").agg(value=to_agg)t=t[t.item_id,t.value,Scalar(1).rename("status")]t.persist(f"{output_project}.{output_table_name}")if __name__ == "__main__":args = parse_args()merge_item(args)
执行以下,可以看到我们能通过pyodps实现非常复杂的数据处理,这是之前ODPS SQL无法带给我们的能力。

我们会看到如下执行参数,这里的input就是之前的输入:
ODPS的input就是读数据表,或者上游的MAXCompute的输出而类似:--input2 /ml/input/data/input2/output1 就是文件资源,上游通常为oss的output。所以oss的文件在代码中是通过读文件的方式读取的。

超绝的图片处理

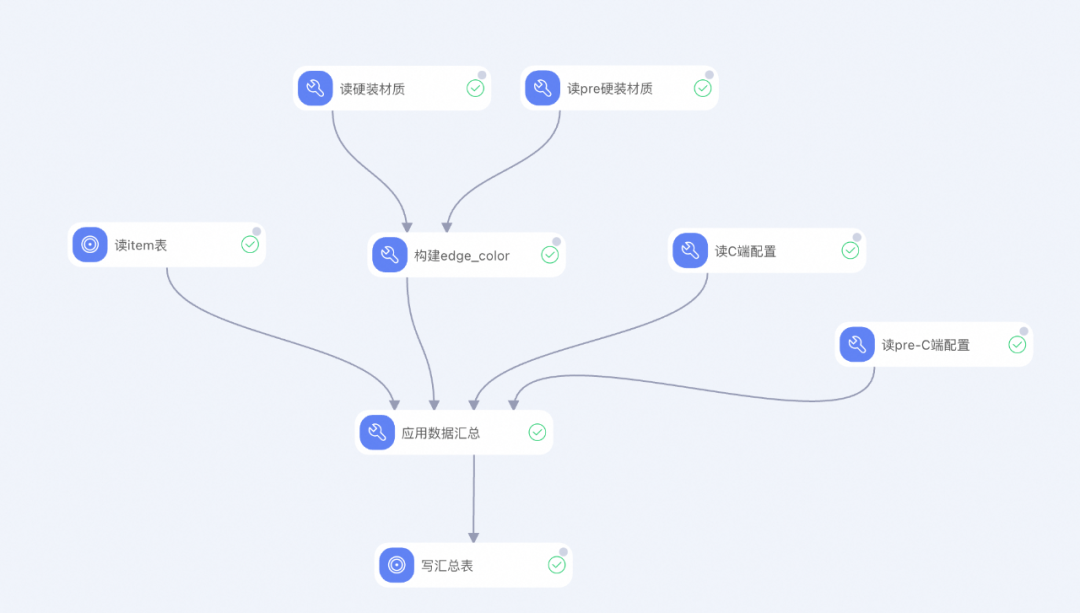
可以看到我这个构建edge_color模块不仅根据配置读取了表的数据,并且将表中的url下载计算edge_color,写入了数据表。
极其强大!
但是我们会有个问题,pai是怎么具有图片处理的能力的呢?答案来自他的执行配置:
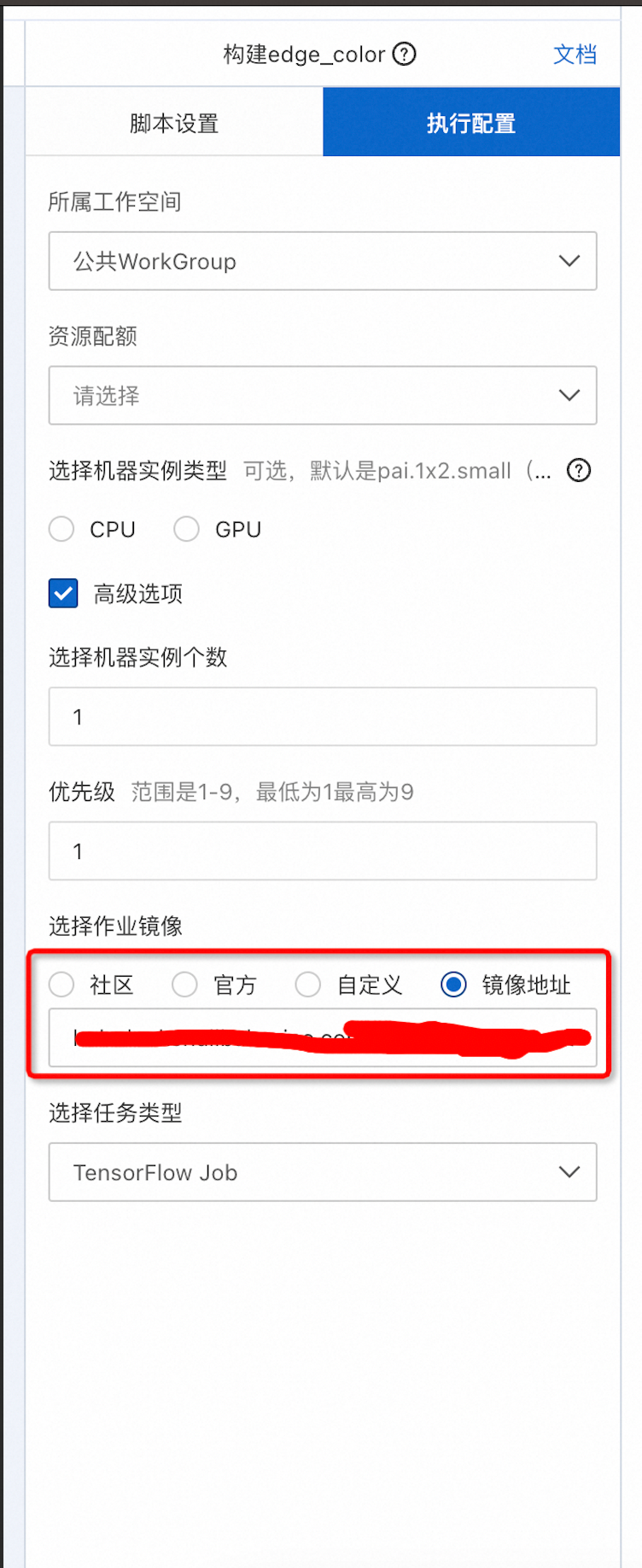
可以自定义镜像!当然,如果只是简单的图片处理也可以通过。
安装一些包。这里是为了探索镜像构建的流程,整理了个自己的Docker镜像。
▐ 镜像构建
我的dockerfile:
FROM reg.docker.alibaba-inc.com/alibase/alios7u2-min:1.13COPY ./resource/Python-3.9.18.tar.xz /home/admin/Python-3.9.18.tar.xzWORKDIR /home/adminRUN rpm --rebuilddb && yum install -y gcc gcc-c++ automake autoconf libtool make zlib-devel openssl openssl-devel libxslt-devel libxml2-develRUN rpm --rebuilddb && yum install -y pcre pcre-devel zlib zlib-devel libffi-devel# 安装pythonRUN tar xJf Python-3.9.18.tar.xz && \cd Python-3.9.18 && ./configure --prefix=/usr/local/python && make && make install && \rm -rf /usr/bin/python && \ln -s /usr/local/python/bin/python3 /usr/bin/python && ln -s /usr/local/python/bin/pip3 /usr/bin/pip# 建议换一个自己相关的源RUN pip install --upgrade pip && pip config set global.index-url https://xxxx.xxxx-xxxx.cn/simple/RUN pip install setuptools>=3.0 pyodps pillow requests numpy scipy matplotlib
下载Python的安装包确实太慢了,就把python的zip也传到了code的repo里。
PS: 大家不要模仿,完全可以把安装包传到OSS之类的地方加个速。不能什么大文件都往git传。
可以看到我的镜像里安装了pillow、numpy、pyodps。构建完镜像,上传到对应的镜像仓库,如:docker hub等。
▐ 脚本编写
在pai-designer的 python脚本 的执行配置中配置上自己的景象地址之后就可以写main脚本了。
def execute(args):# 读线上的配置.room_config = Nonewith open(args.input1 + "/result.txt") as f:room_config = json.loads(f.read())room_ids = [int(x["roomId"]) for x in room_config]# 因为是要计算所有的room的edgeColor,所以这里再读一份预发的.room_config_pre = Nonewith open(args.input2 + "/result.txt") as f:room_config_pre = json.loads(f.read())for x in room_config_pre:if int(x["roomId"]) not in room_ids:room_ids.append(int(x["roomId"]))o = init_odps()output_project, output_table_name, output_partition = parse_odps_url(args.output3)room_table = DataFrame(o.get_table("project.room_table").get_max_partition())# 用room_ids的id做一下过滤room_table = room_table[room_table.id.isin(room_ids)]edge_color_result = {}# 实际上配置不到100条数据.for current in room_table.head(100):# 下载图片并解析edgeColorurl = current[1]image = download_image(url)edge_color = get_average_color(image)edge_color_result[current[0]]= edge_coloros.makedirs(args.output1, exist_ok=True)p = os.path.join(args.output1, "result.txt")with open(p, "w") as f:f.write(json.dumps(edge_color_result))
就贴一下关键的部分代码。这里get_average_color调用pillow去获取和计算图片边缘的颜色。
这里有几个注意点:
pyodps的@output以及自定义聚合函数Agg的数据处理方法并不能引用非基础库的依赖。 -- 这里给大家踩过坑啦。
因为我的数据不多,所以可以head一下全拿出来,在主进程中做成一个dict,为后续链路使用。但实际上head是有上限的。而且不建议这么用。
建议写法,参考帮助文档:
https://pyodps.readthedocs.io/zh-cn/stable/base-tables.html#table-read
with t.open_reader(partition='pt=test,pt2=test2') as reader:count = reader.countfor record in reader[5:10]: # 可以执行多次,直到将count数量的record读完,这里可以改造成并行操作# 处理一条记录

结语
PAI-Designer作为一个强大的离线数据处理工具,不仅能够弥补传统ODPS在处理动态配置、网络访问及复杂数据处理上的不足,还通过高度可定制的Python脚本组件和灵活的环境配置,极大地扩展了其应用范围。用户能够借助PAI-Designer构建出既满足特定业务需求又具备高度灵活性的离线数据处理流程,尤其是在需要集成外部服务或进行复杂数据转换的场景下,其价值尤为显著。然而,随着功能的增强,用户也需谨记安全与合规操作的重要性,确保数据处理过程的安全性。

团队介绍
我们是淘天集团的场景智能技术团队,作为一支专注于通过AI和3D技术驱动商业创新的技术团队, 依托大淘宝丰富的业务形态和海量的用户、数据, 致力于为消费者提供创新的场景化导购体验, 为商家提供高效的场景化内容创作工具, 为淘宝打造围绕家的场景的第一消费入口。我们不断探索并实践新的技术, 通过持续的技术创新和突破,创新用户导购体验, 提升商家内容生产力, 让用户享受更好的消费体验, 让商家更高效、低成本地经营。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。