#!/usr/bin/env python # -*- coding:utf-8 -*- # author:love_cat
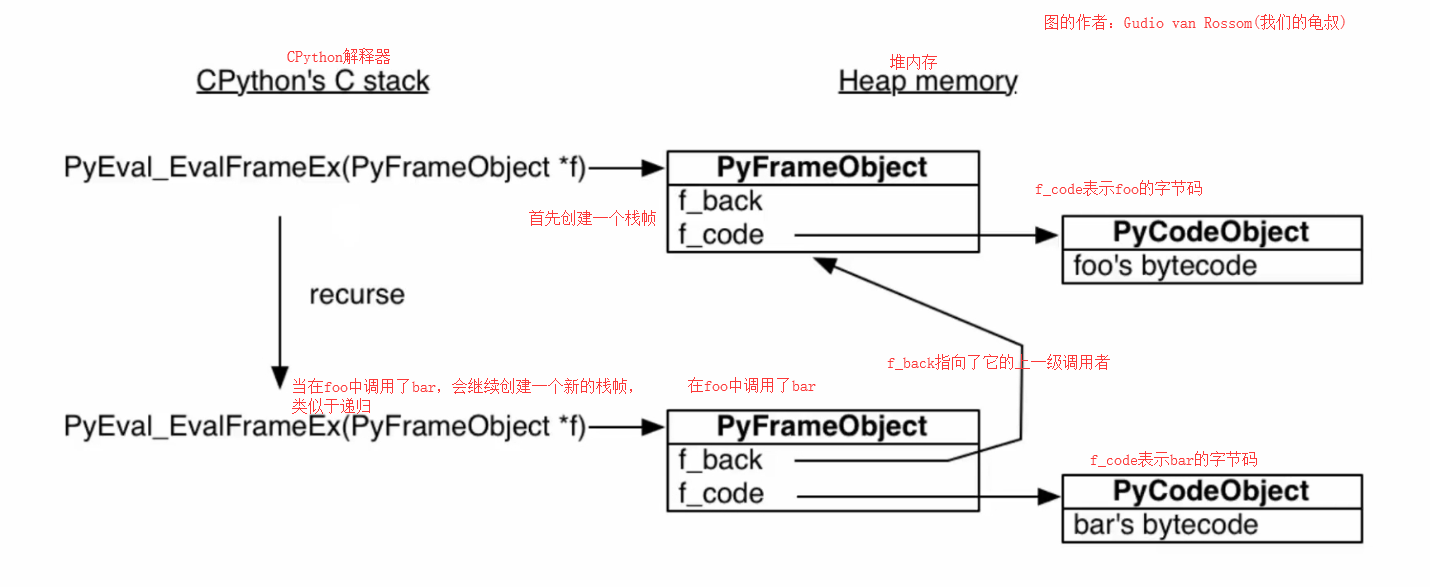
# python的函数是如何工作的 # 比方说我们定义了两个函数 def foo(): bar() def bar(): pass # 首先python解释器(python.exe)会用一个叫做PyEval_EvalFrameEx()的C语言函数去执行foo,所以python的代码是运行在C程序之上的 # 当运行foo函数时,会首先创建一个栈帧(stack frame),表示函数调用栈当中的某一帧,相当于一个上下文,函数要在对应的栈帧上运行。 # 正所谓python一切皆对象,栈帧也是一个对象 # python虽然是解释型语言,但在解释之前也要进行一次预编译,编译成字节码对象,然后在对应的栈帧当中运行 # 关于python的编译过程,我们可以是dis模块查看编译后的字节码是什么样子 import dis print(dis.dis(foo)) # 程序运行结果 ''' 11 0 LOAD_GLOBAL 0 (bar) 2 CALL_FUNCTION 0 4 POP_TOP 6 LOAD_CONST 0 (None) 8 RETURN_VALUE None ''' # 首先LOAD_GLOBAL,把bar这个函数给load进来 # 然后CALL_FUNCTION,调用bar函数的字节码 # POP_POP,从栈的顶端把元素打印出来 # LOAD_CONST,我们这里没有return,所以会把None给load进来 # RETURN_VALUE,把None给返回 ''' 以上是字节码的执行过程 ''' # 过程就是: ''' 1.先预编译,得到字节码对象 2.python解释器去解释字节码 3.当解释到foo函数的字节码时,会为其创建一个栈帧 4.然后调用C函数PyEval_EvalFrameEx()在foo对应的栈帧上执行foo的字节码,参数就是foo对应的栈帧对象 5.当遇到CALL_FUNCTION,也就是在foo执行到bar的字节码时,会继续为其创建一个栈帧 6.然后把控制权交给新创建的栈帧对象,在bar对应的栈帧中运行bar的字节码 ''' # 我们看到目前已经有两个栈帧了,这不是关键。关键所有的栈帧都分配在堆的内存上,而不是栈的内存上 # 堆内存有一个特点,如果你不去释放,那么它就一直待在那儿。这就决定了栈帧可以独立于调用者存在 # 即便调用者不存在,或者函数退出了也没有关系,因为它始终在内存当中。只要有指针指向它,我们就可以对它进行控制 # 这个特性决定了我们对函数的控制会相当精确。
# 我们可以改写这个函数 # 在此之前,我们要引用一个模块inspect,可以获取栈帧 import inspect frame = None def foo(): bar() def bar(): global frame frame = inspect.currentframe() # 将获取到的栈帧对象赋给全局变量 foo() # 此时函数执行完毕,但是我们依然可以拿到栈帧对象 # 栈帧对象一般有三个属性 # 1.f_back,当前栈帧的上一级栈帧 # 2.f_code,当前栈帧对应的字节码 # 3.f_locals,当前栈帧所用的局部变量 print(frame.f_code) print(frame.f_code.co_name) ''' <code object bar at 0x000000000298C300> bar ''' # 可以看出,打印的是我们bar这个栈帧 # 之前说过,栈帧可以独立于调用方而存在 # 我们也可以拿到foo的栈帧,也就是bar栈帧的上一级栈帧 foo_frame = frame.f_back print(foo_frame.f_code) print(foo_frame.f_code.co_name) ''' <code object foo at 0x000000000239C8A0> foo ''' # 我们依然可以拿到foo的栈帧 # 总结一下:就是有点像递归。遇见新的调用,变创建一个新的栈帧,一层层地创建,然后一层层地返回
关于类似于递归这个现象,我们可以看一张图