一、背景介绍
58大数据团队在计算方面的在离线混部项目已经取得了很好的效果,后续规划将大数据组件与云技术进行逐步的融合,同时在过去几年,58大数据团队已经实施了很多高效的降本增效策略(数据EC、高效压缩、治理优化等等),也取得了不错的成果,2024上半年考虑结合云技术对HBase集群进行云化改造,进一步降低业务成本,减少运营维护成本。
1.1 HBase云化背景
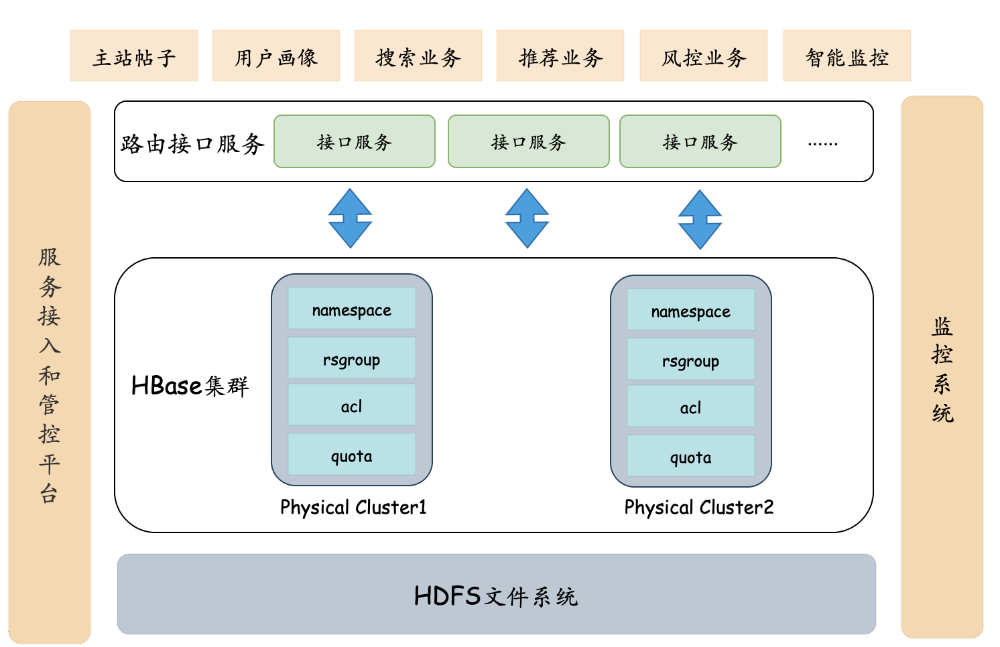
在58的业务场景中,HBase扮演重要角色。例如帖子信息、用户信息等公司基础信息会定期离线同步到HBase中,为各个业务线提供随机查询及更深层次的数据分析。同时各个业务线可以将自己的数据存储在HBase中进行批量查询,可用于用户画像、趋势分析、推荐业务、搜索业务、时序数据存储等场景。整体架构如下图所示:
随着业务不断的增多,HBase集群在长期的运营过程中,发现了很多问题,主要有
1.)业务类型多样,但是整体规格统一,
无法最大化利用资源,
资源浪费。
2.)业务集群较多,业务分组混乱,维护和管控复杂,
运营成本高,扩展性差。
3.)集群升级版本迭代比较麻烦,涉及到环节较多,
迭代和维护成本高。
结合以上问题,考虑可通过云化部署,整体容器化,提升计算资源利用率,减少用户成本。Hbase云化整体目标如下几个方面:
-
原有HBase物理集群
全部云化,所有Hbase业务均迁移到云上。
-
-
开发运维一体化,收敛整体运营能力,降低
运营维护成本,支持高效迭代。
二、HBase云集群建设
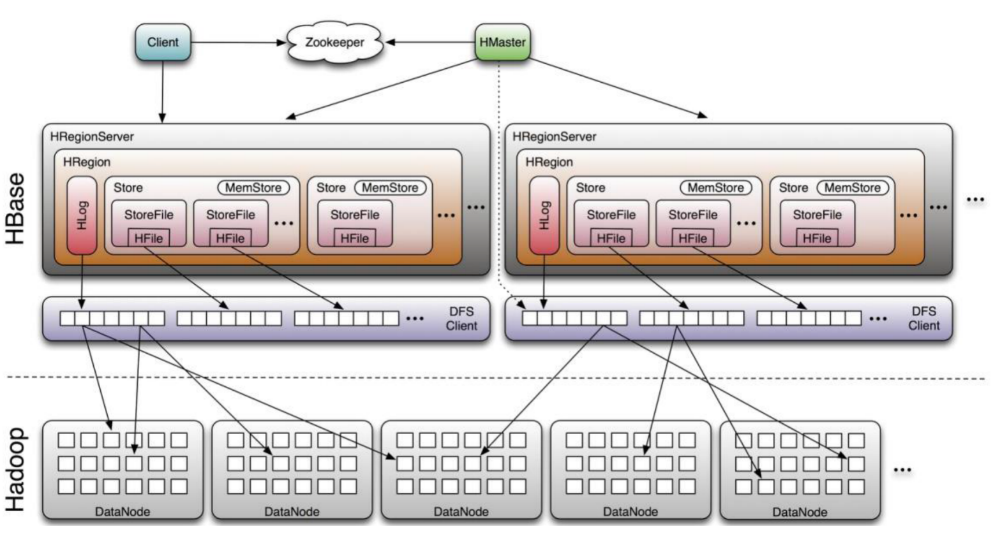
2.1 HBase架构介绍
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式KV存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase体系结构是典型的Master-Slave模型。系统中有一个管理集群的Master节点以及大量实际服务用户读写的RegionServer节点。HBase中所有数据最终都存储在HDFS系统中,系统中还有一个ZooKeeper节点,协助Master服务对集群进行管理。整体如下图所示:
架构特点:Master是中心节点,负责维护元数据和集群管理,RegionServer是数据存储节点,Master和RegionServer服务均部署在单独的服务器上,通过zookeeper进行交互,业务直接访问RegionServer服务读写数据。RegionServer数据节点可以横向扩展,同时可以按照业务划分rsgroup,支持多租户,支持完善的权限管理等安全机制。综上,我们看到Hbase原生架构很多方面可以很好地适配云平台的一些特性。
2.2 58云平台介绍
58云平台是为用户打造的一站式云化解决方案,集成了业务开发中常用的云、服务治理平台、中间件、存储等基础平台与组件。58云平台整合了基础架构方面所能提供的所有能力,以集群管理、中间件和存储三个大的维度进行划分。
58云平台上提供了镜像管理、上线发布、配置管理、容器管理、自动化扩缩容、分组管理、回滚降级、权限配额、资源池管理、日志管理、监控管理等集群管理相关的能力。
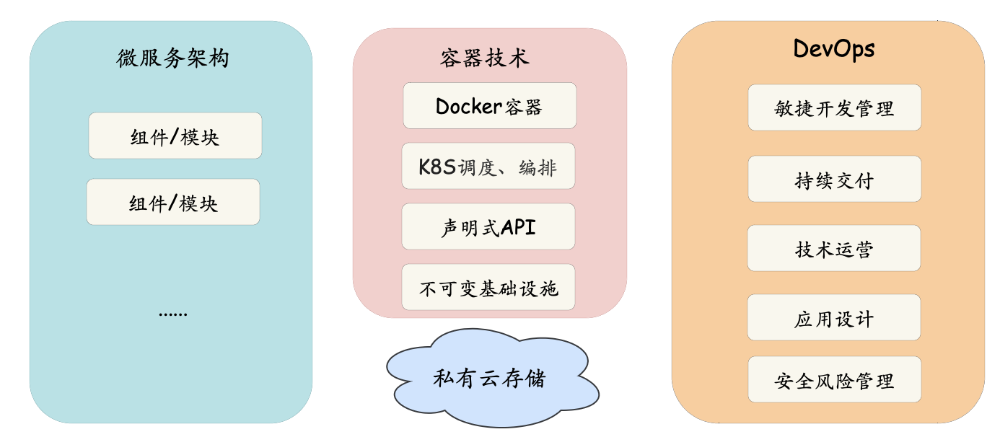
58云平台支持云原生建设的所有相关能力,整体相关的技术概念如下图所示,主要包含微服务架构模式、相关的容器技术、运维开发一体化能力,容器技术包含Docker容器、K8S调度和编排、声明式API、不可变基础设施等。HBase云化可以借助云平台上这些集群管理能力实现自动化集群部署、升级等运维工作,实现运维开发一体化,同时利用云上资源弹性的特点,进行成本优化。
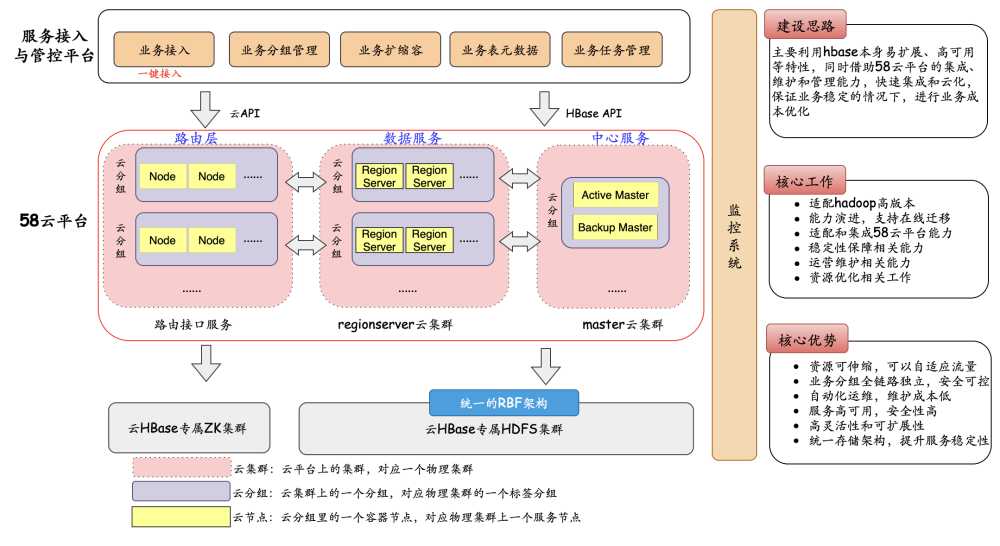
2.3 集群建设
整体HBase云集群的建设思路是
主要利用Hbase本身易扩展、高可用等特性,同时借助58云平台的集成、维护和管理能力,快速集成和云化,保证业务稳定的情况下,进行业务成本优化。相关核心工作主要有适配hadoop高版本、适配和集成58云平台基础能力、稳定性保障相关能力开发、运营维护相关能力开发、资源优化相关工作。
-
采用独立master云集群+独立regionserver云集群+独立regionserver云集群上多个云分组的架构。
-
独立的Master云集群主要负责维护master服务,可以横向扩展,每个分组部署两个master服务,实现高HA架构,实现服务快速恢复能力。
-
独立regionserver云集群上的每个云分组对应物理集群上的一个RsGroup,利用云平台集群分组的能力,可实现不同业务RsGroup配置维护和管理。每个独立regionserver云集群上的云分组理论上可以无限扩展云分组,每个云分组上可以横向扩容云容器节点,hbase原生的rsgroup分组模式以及regionserver横向扩展能力可以无缝适配。
-
根据业务特点,设置不同的业务类型,按需配置不同的容器规格,利用云平台高效的调度机制进行资源利用率最大化。
-
适配Hadoop3版本,统一底层存储架构,提升服务稳定性以及减少运维成本。
-
充分利用58云平台运维、升级、管理等自动化能力,减少运维成本。
-
运营能力增强,业务一键接入,自动化扩缩容,表认领和交接能力等等。
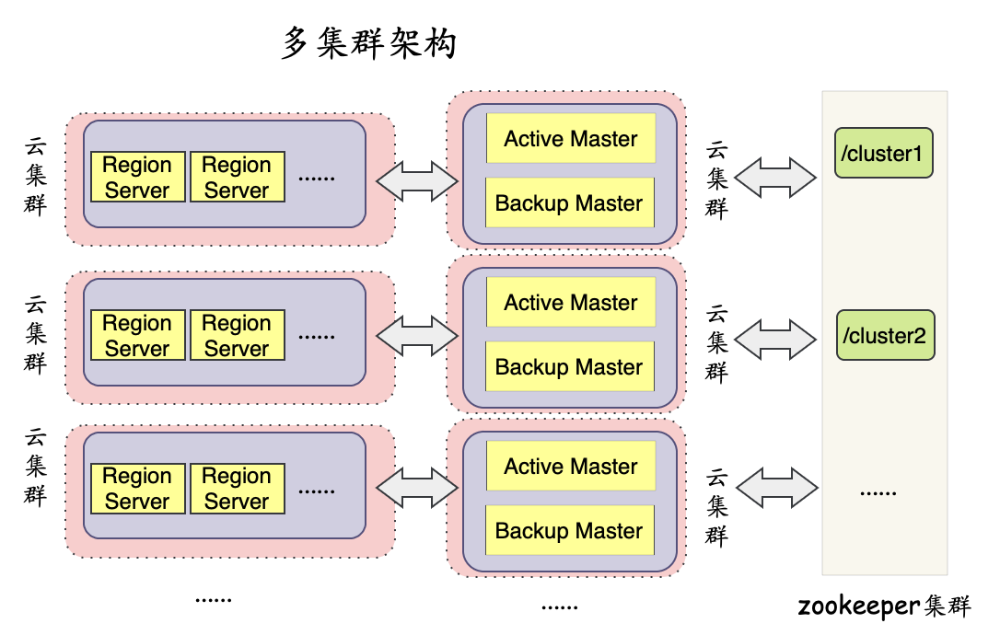
建设1:演进云集群架构
为了适配云平台的集群部署模式,衍生了两种集群架构,第一种是多集群架构,master、regionserver云集群单独部署,每个regionserver云集群对应物理集群上的每个业务分组,每个regionserver云集群对应一个master云集群,master、regionserver云集群都可以横向扩展集群,每个RegionServer云集群也可以横向扩展容器节点数量。详细如下图所示:
这种架构优势为易扩展和易适配,每个集群可以很方便应用定制化的配置,不需要额外的适配开发工作。但是维护比较复杂,维护过多集群,zookeeper集群请求压力较大,同时也浪费资源,和整体云化目标背道而驰。然后衍生出了第二种架构,一集群多分组架构,master、regionserver云集群还是单独部署(因为服务进程和类型不同,所以尽量独立),master、regionserver云集群各只有一套,regionserver云集群里每个云分组对应物理集群上不同的业务分组(RsGroup),云集群上可以横向扩展业务分组,master云集群上的云分组也可以根据集群负载情况进行扩展新的master云分组。然后RegionServer云集群每个分组也可以横向扩展容器节点,这种架构优势是方便维护,节约云化成本。但是需要集成单集群多分组的定制化配置管理等,有一定的开发适配成本。我们主要选择了以集群多分组架构,在这个架构基础上进行完善和优化,逐步达到集群云化目标。
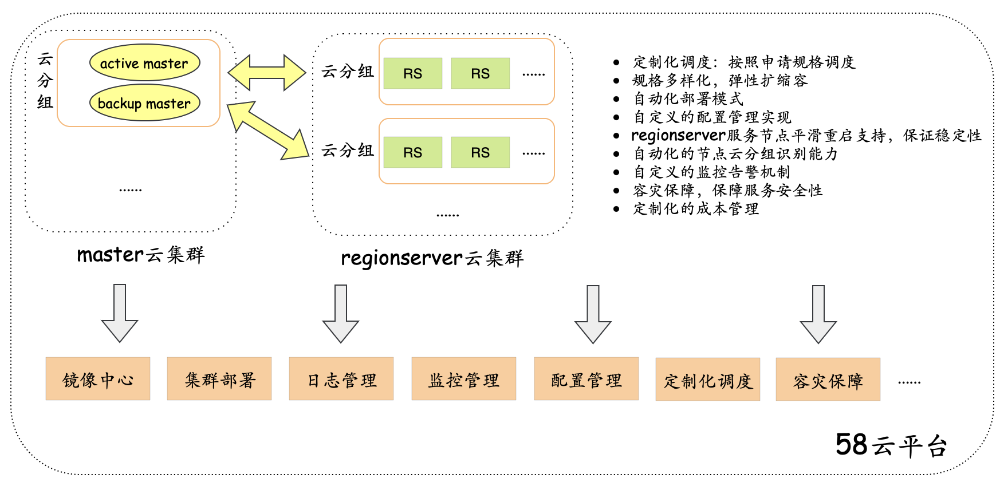
建设2:适配云平台-完善基础能力
适配云平台集群维护相关的能力,主要包含集成部署、配置管理监控告警、故障处理、日志管理等,同时支持定制化资源调度,容灾故障等,保障集群稳定性情况下进行成本优化。详细如下图所示:
建设3:集群能力演进
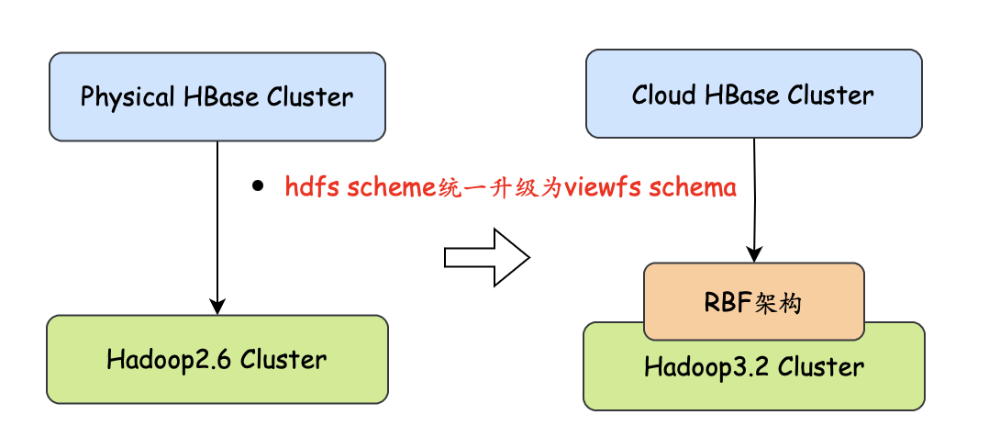
为了更好的适配云平台和迁移,我们同步做了相关集群底层架构和能力的演进,主要包含如下三个方面,涉及底层存储架构统一、HBase迁移能力完善、路由接口服务升级。详细如下:
-
适配高版本hadoop集群,统一架构---->提升集群稳定性和维护效率
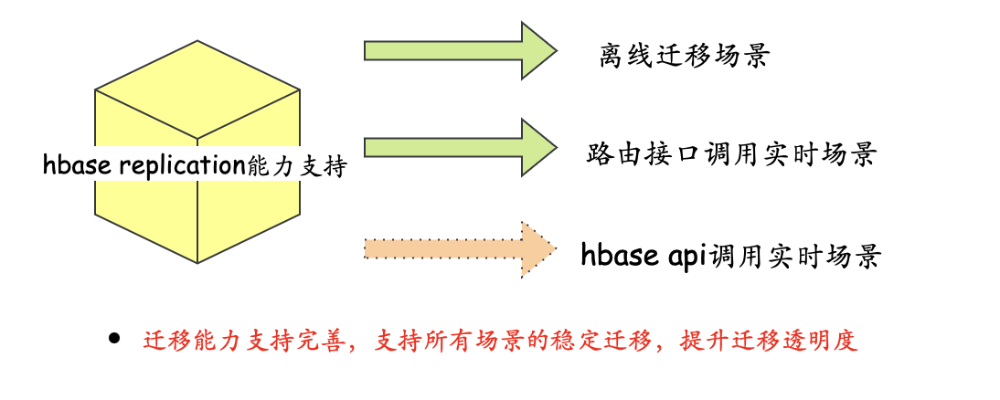
-
HBase replication能力支持,支持在线场景迁移---->支持所有业务场景稳定迁移,提升迁移透明度
-
路由接口服务架构升级,适配云平台,同时审计增强---->支持对所有调用者透明迁移
建设4:运营管理适配云平台、能力增强
为了支持集群云化,需要对集群运营管理能力进行适配云平台的全新模式,同时需要对相关能力进行增强,提高业务接入效率,提升平台运营能力。主要包含如下几个方面:
-
规范化运营流程:补全工单扩缩容等---->提升运营效率,提升服务安全性
-
优化接入流程:实现一键接入,补全元数据认领、交接能力等---->提升业务接入效率,提升使用便捷性
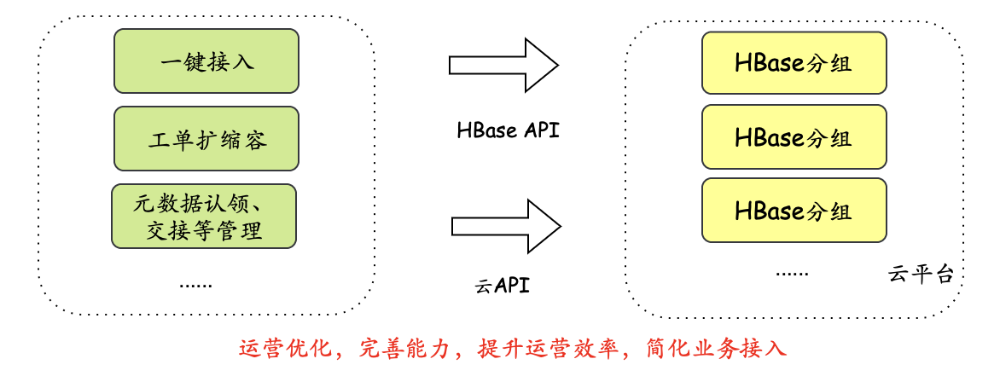
2.4 核心问题&解决方案
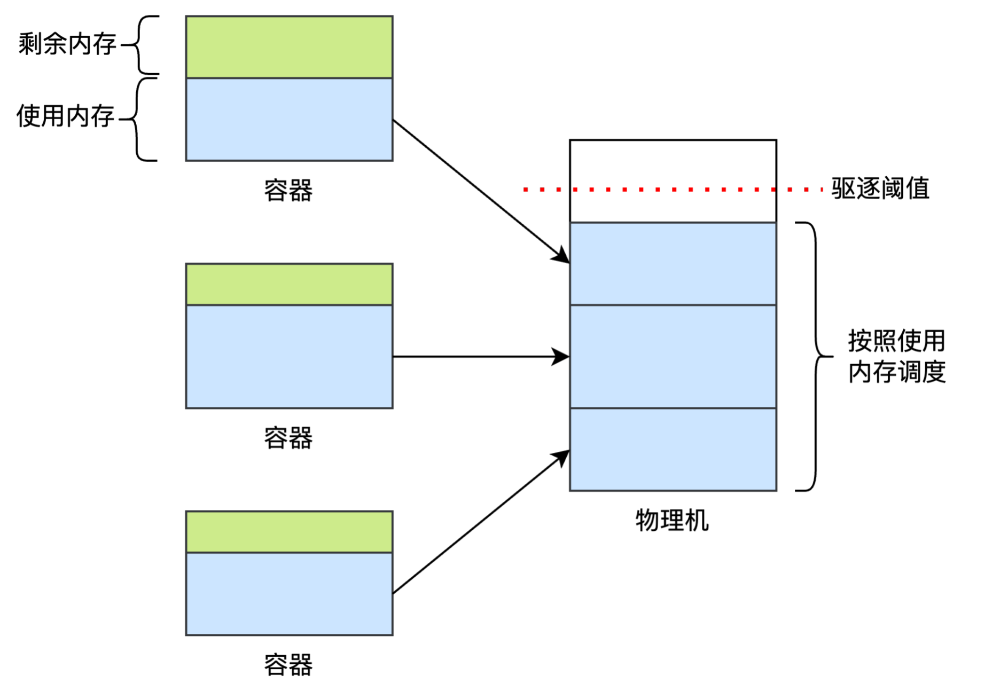
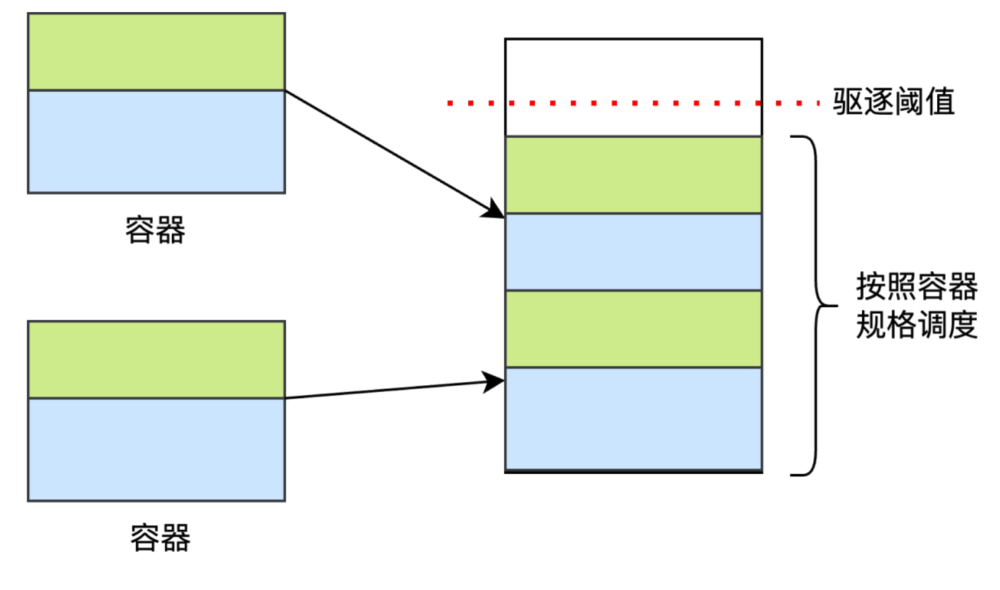
(1)容器进程(RegionServer)频繁驱逐问题:在云平台中,传统的资源调度策略是基于容器实际内存使用量进行动态调整,这种策略可能导致物理节点上的容器超额分配,尤其是在处理如HBase RegionServer这类内存需求波动较大的服务时。HBase RegionServer的内存消耗受用户读写请求量和数据压缩任务等因素影响,呈现出显著的波动性,这不仅使得物理集群的内存利用率不稳定,还可能频繁触发过载迁移机制,导致整个云集群出现节点频繁漂移的现象,严重影响HBase集群的稳定性和性能。
解决方案:为解决这一问题,建议采用基于容器规格的调度策略。在这种策略下,创建容器时即明确指定其资源规格,调度器据此进行资源分配,从而有效避免物理机器上的超分现象。这种预定义的资源分配方式有助于实现更均衡的资源利用,减少因内存波动引起的调度不稳定性,进而提升整个HBase集群的运行稳定性和效率。
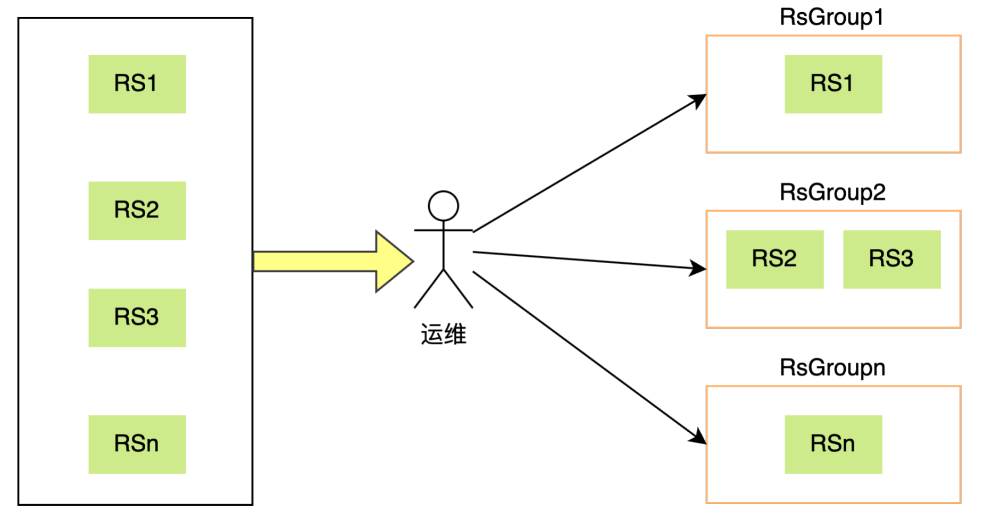
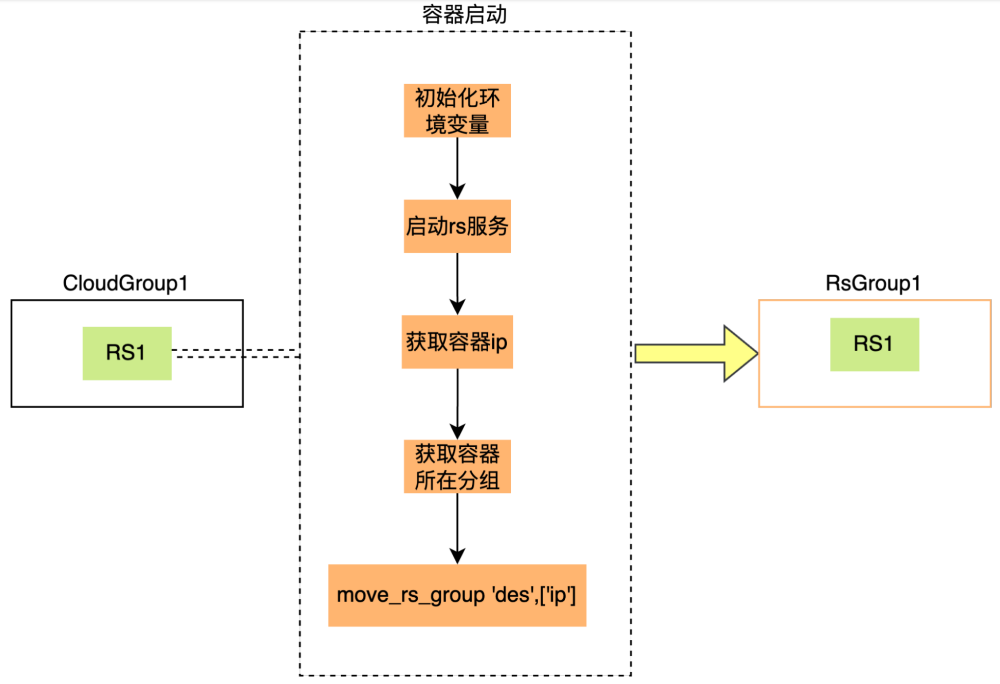
(2)分组节点迁移:在传统物理机环境中,部署HBase RegionServer服务时,可以通过手动操作将节点加入到特定的HBase RsGroup中。然而,在云环境中,由于节点的动态扩缩容特性以及IP地址的不确定性和漂移现象,手动管理节点分组变得极为繁琐且不切实际。
解决方案:为应对这一挑战,实施一种自动化策略,即在容器节点启动时集成自动分组迁移逻辑。具体而言,当容器节点在云环境中启动时,系统应能够识别其所属的云分组,并自动调用HBase的API或命令行工具,执行相应的分组移动操作,将容器节点自动迁移至预设的目标RsGroup。这种自动化机制不仅减轻了运维负担,还确保了HBase集群的动态适应性和高效管理。
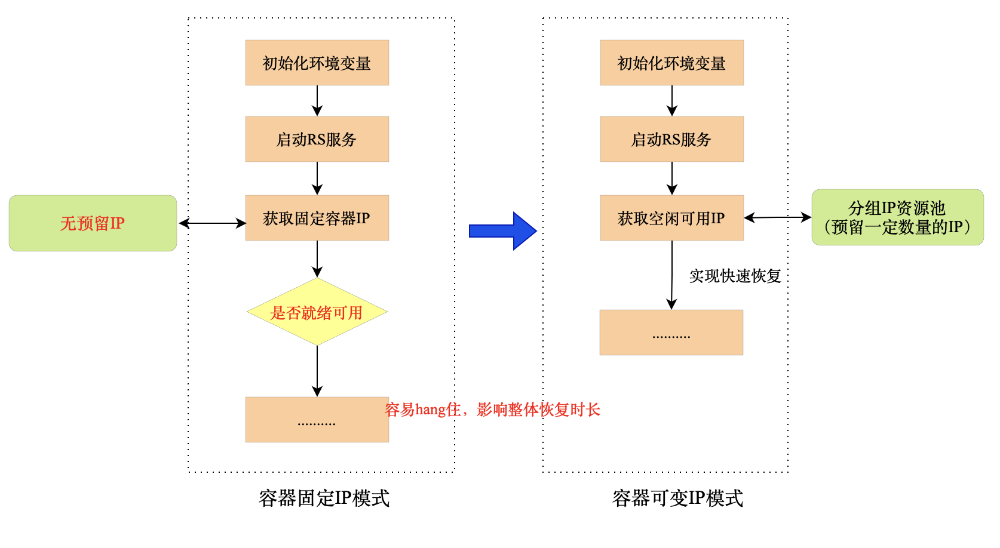
(3)服务故障恢复问题:在传统物理集群上,一台RegionServer服务挂掉后,会自动把相关region数据移动到RsGroup上其他服务节点上,需要等待对应节点上的服务恢复。对应上云后如果严格限制容器使用固定IP,不预留buffer,在容器故障恢复过程中需要等待分组上的固定IP可用后才能继续启动容器进程,会有一定的时间损耗,严重情况下会长时间hang住,导致长时间无法恢复问题,影响分组服务的稳定性。
解决方案:线上云集群我们为每个分组会预留一些容器IP,采用非严格限制,允许容器进程重启用不同的IP,在容器进程故障恢复中会从分组IP资源池中获取空闲的可用IP,实现整体快速恢复。
(4)配置管理:当前物理环境的HBase配置采用puppet进行配置的管理,实现配置的维护和动态刷新,但这依赖于已知机器的ip。在云原生环境,容器的ip是不确定的,此外启动puppet agent服务也占用额外的系统资源。
解决方案:容器启动时拉取配置文件的逻辑,每次容器重启即可获取到最新的配置。
(5)zgc内存统计:HBase使用了ZGC,服务上云后,由于 ZGC 使用系统 shmem(共享内存) 的机制,导致申请的内存,虽只使用了很少一点,但仍被系统算做全部占用,这导致使用top命令查看进程内存占用时,进程内存被重复计算。此外,云平台在进行容器内存使用统计的时候,只采集了RSS,未计算shmem部分。这导致从监控上看,容器的内存利用率很低,但实际的内存使用已处于较高水平。
解决方案:一方面
在
内核启动参数中增加 “
file_zeropage=1 ” 来启用 file_zeropage 配置,解决top命令内存统计不准的问题;另一方面容器的实际内存统计采用RSS+部分shmem(根据物理节点上实际分配的容器节点数按比例统计),解决云平台监控容器内存使用率不准的问题。
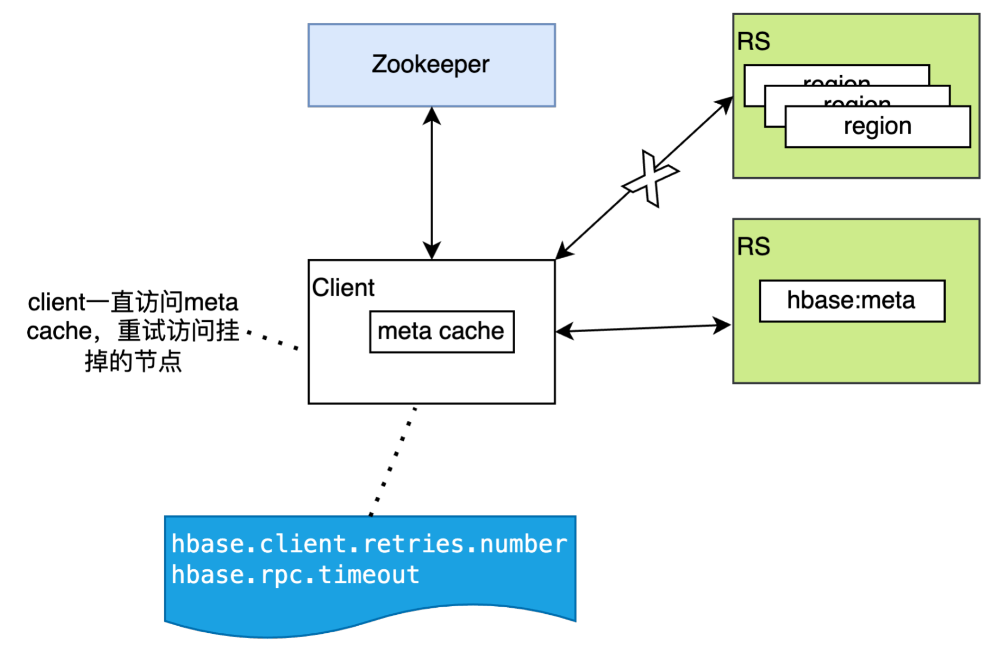
(6)节点平滑重启:云容器节点重启或关闭会直接销毁容器,这会导致容器上的RegionServer服务被直接关闭,类似于物理机的宕机。这时候由于客户端无法感知RS服务是否正常,会不停地重试,并且在重试的时候由于hbase访问的本地的meta cache,所以会一直访问挂掉的节点,直到超过重试次数或者超时,线上HBase服务稳定性受到较大影响。在集群升级或者节点故障迁移的时候,这种销毁容器导致的性能波动对业务来说是无法容忍的。
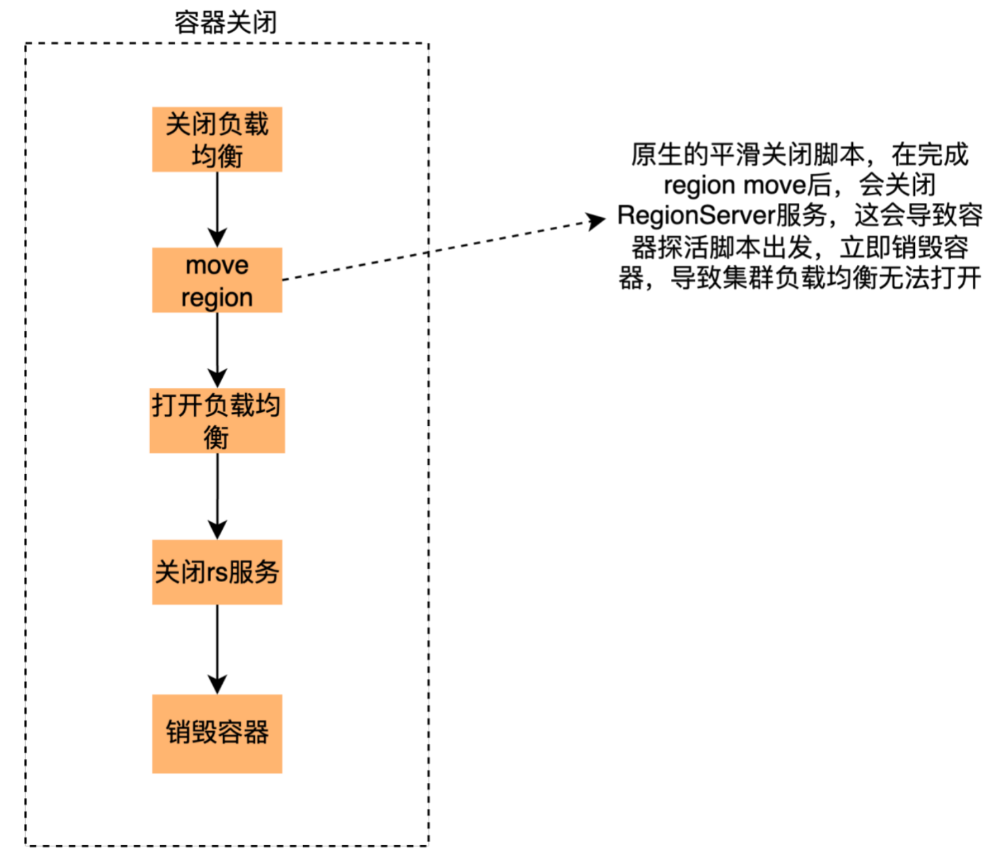
解决方案:针对这个问题,我们将HBase的平滑关闭脚本进行了改造,并集成到容器的关闭逻辑中。具体来说,在容器销毁之前会执行HBase的平滑关闭脚本,首先关闭集群的自动负载均衡,然后对当前节点的Region进行驱逐,驱逐完毕后打开自动负载均衡。在等待关闭脚本执行完毕或者超过指定时间后进行容器销毁。因为是重启之前主动触发Region的移动,Regino移动后master会通知client更新本地meta cache中regino的位置,最大程度减少因容器节点重启或关闭对业务的影响。
三、HBase业务迁移
3.1 迁移方案
迁移方案主要有三种不同模式,每种模式都有不同的场景和特点,主要包括离线模式、路由双写模式、replication双写模式。下边分别介绍下每种模式。
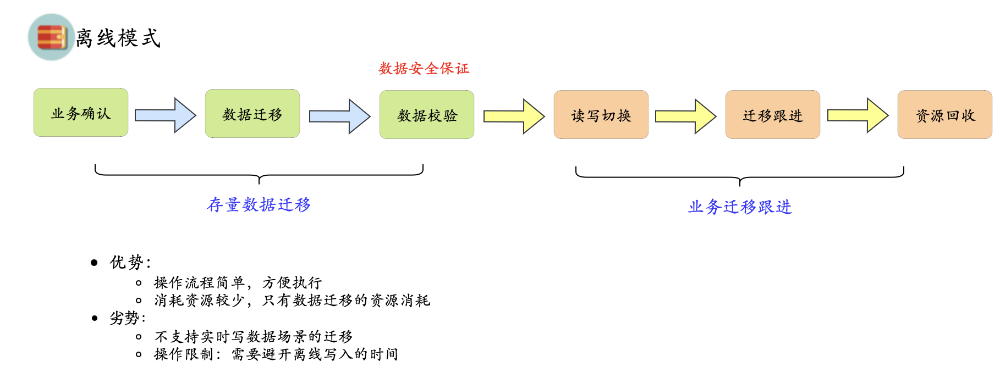
第一种为离线模式,主要针对离线写入(导入)的场景,需要避开写入任务运行的时间进行迁移,详细如下图所示:
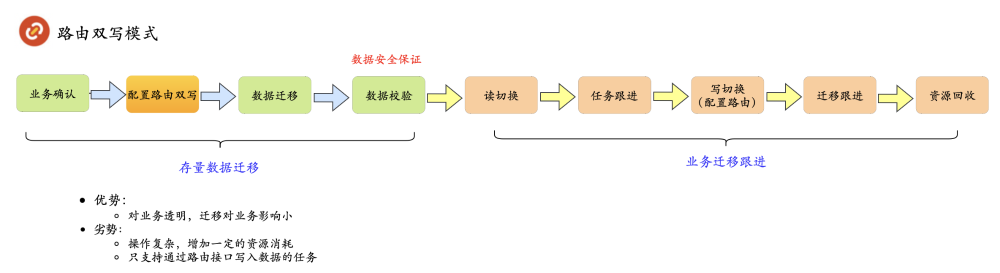
第二种为路由双写模式,主要针对路由接口写入的场景,整体由平台侧操作,对业务透明,详细如下图所示:
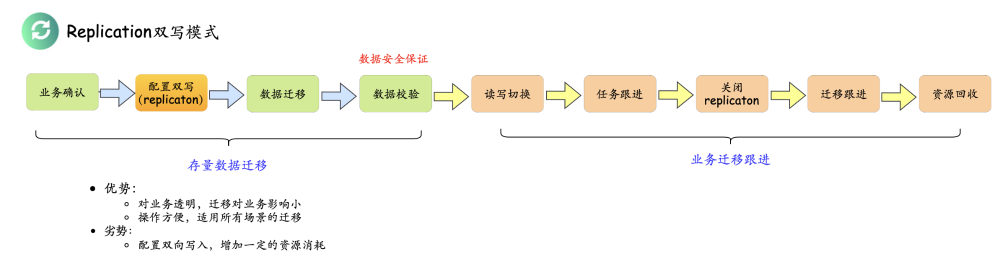
第三种为replication双写模式,支持在线迁移场景(hbase api、路由接口实时写入),可以保障整体对业务透明,可以保障数据的安全性,详细如下图所示:
3.2 迁移相关问题和处理
(1)迁移过程中对集群的压力增大,影响云集群稳定性的问题
具体问题:数据量较大的表在做数据拷贝过程中,占用了较高的网络和磁盘IO资源,导致对线上业务的读写产生了影响。
解决方案:增加拷贝数据的限流,降低迁移对在线业务的影响,减少资源竞争。同时分步、分批次进行迁移,优先保证服务质量。
具体问题:大表在迁移后会有一段时间无法命中缓存(no cache)导致访问延迟较高的问题。
解决方案:提前对热数据进行缓存预热,缓慢透明迁移调用者减少访问量。根据访问数据p99来进行判断是否可以切换下一个调用者,迁移完成后业务基本无感知。
具体问题:审计能力较弱,无法准确确定相互应用和重复使用的调用情况,产生了迁移后有关联的调用遗漏问题,导致业务报错。
解决方案:做了审计增强,同时调用DAG算法计算迁移组,这样确保了迁移过去的表和调用者不会出现无法访问的问题。
(4)大数据量表做major compact资源风险问题
具体问题:大表做major compact一般需要消耗较多系统资源,由于原来在物理节点上,平时会有一些资源空闲,这样运行major compact对集群压力整体可控,但是迁移到云上后,每台容器节点资源使用较高,空闲较少,整体做major compact对服务稳定性会产生很大隐患。
解决方案:按表类型周期做major compact时增加按照regionserver.table粒度执行,这样对整体分组的影响可控,同时结合对major compact操作的并发和资源限制,保障集群整体稳定性。
四、云原生总结
4.1 项目收益:
项目收益主要体现在三个方面,第一个是HBase业务云化带来的成本优化、资源利用提高等,然后是是运营维护提效方面,实现运维自动化,运营优化。最后是底层架构迭代方面,完成了hadoop版本的统一。详细收益如下图所示:
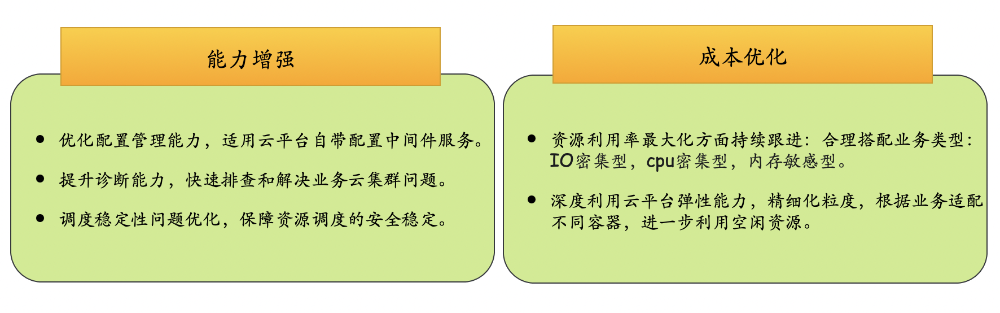
4.2 后续规划:
后续规划主要在能力增强和成本优化两个方面,比如适用云平台配置中间件、提升诊断能力等,详细规划如下图所示:
五、作者简介
李营,
樊乐,
沈晨航,数据架构部存储方向研发,
最后感谢云平台团队和运维团队的大力支持。