
序言
问题描述
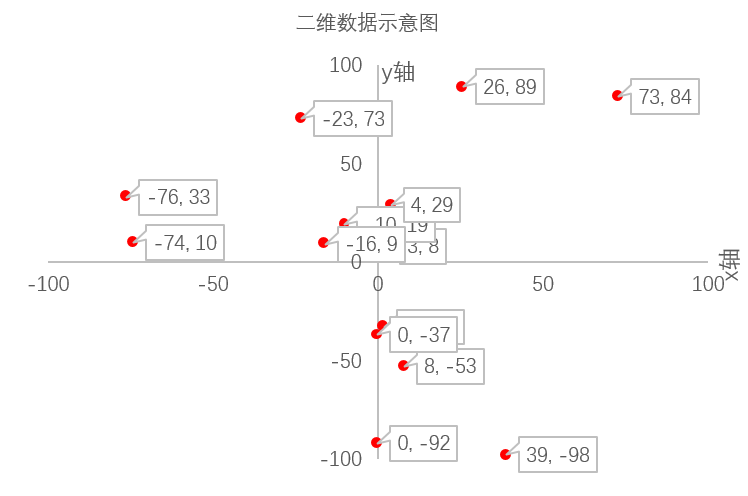
现在有如下示例的14个二维空间的点的数据, 每一行表示一个点数据,冒号前的数值为该点的id,冒号后是一个典型的二维数值的坐标值x和y(假定id和x,y的值都是int类型)。比如第一行0:(3,8) 含义为: 数据id为0, 数据值是一个二维数据,第一维值x=3, 第二维值y=8。
0: (3,8)1: (-74,10)2: (2,-33)3: (0,-92)4: (73,84)5: (-10,19)6: (-23,73)7: (8,-53)8: (0,-37)9: (4,29)10: (39,-98)11: (-16,9)12: (26,89)13: (-76,33)
本文要讨论解决的问题可表述为:
如何从该数值数据点的集合中快速查询出x 值在(-3,8)范围内且y值在(-5,3)范围内所有点(即返回满足范围条件内的所有点的id及其二维数据值x和y本身)?
这就是搜索引擎中非常基础的查询问题之一:大规模数值(类型)数据的范围查询问题, 尤其经常是要在多维的数值数据集合上的范围查询(比如本例中就是一个2维数值数据的查询)。
要查询的目标范围的上下边界值如果设定为同一个值,范围查询就转变为数值数据的精确值查询。因此解决了范围查询问题几乎就解决了数值数据查询的绝大部分问题,因此这个问题具有基础性。
详细分析问题之前,简短描述该问题的关键要素如下:
面对的数据规模大 - 数据个数多, 字段多, 维度多
搜索引擎场景要查询的数据集合通常是海量的,因此数据集合全集通常不能完全存于内存中, 一般还要存储在外部存储器上(比如磁盘)。磁盘IO读写数据速度较慢问题也是重要的解决方案考虑因素之一,后文会涉及描述这一点。
通常不仅仅数据个数多,而且每一个数据还有多个数值字段,每个字段都有快速执行快速范围查询的需求。最后每个字段的数据数值本身可能不止1维,可能是多个维度的。(当然维度数一般不会太大,比如一般最大支持16维或32维即可)。并且,每一维的数值类型也具有多样性,可能是不同字节和精度的整型、浮点型。
要求支持数据的动态更新 - 动态新增数据、删除和修改数据
如果仅仅是要在一个静止不变的静态数据集合上执行范围查询,可能你有所耳闻以传统的KD-Tree数据结构就能满足本问题要求。但是既要支持多维数据快速查询,又要兼顾海量数据的动态更新操作,KD-Tree就不合适了。后文会展开描述KD-Tree的局限性。
综合以上,本文将描述一种能高效地运行在海量的大规模数值数据集合上,既支持海量数据动态更新,又能执行非常快速的数值范围查询的解决方案,即BKD-Tree。BKD-Tree英文全程是:Block K-Dimension Balanced Tree。其中的block意指“一群”,“一簇”,表明BKD-Tree其实是多个tree的集合,即一个森林的数据结构。BKD-Tree最早是杜克大学的几位教授在论文[1]中提出的,它是基于KD-B-Tree设计的,同时结合了一种被称为 “logarithmic method" 的方法使得静态数据动态化。
那么BKD-Tree执行数值查询有多快呢,时间复杂度量化分析如下(假定N是数据集合的元素个数):
BKD-Tree执行精确值查询时间复杂度是O(lgN);
BKD-Tree执行范围查询的耗时依赖于查询结果的元素集合的规模R。最慢的情况如果R的规模是O(N), 则BKD-Tree执行范围查询时间复杂度是O(N);如果R的规模是O(1),则BKD-Tree执行范围查询时间复杂度是O(lgN)。虽然如此,BKD-Tree上执行范围查询能充分利用多维数据分布的局部相似性进行“剪枝”操作,过滤掉众多不必要的数据元素,极大地提高了查询效率。
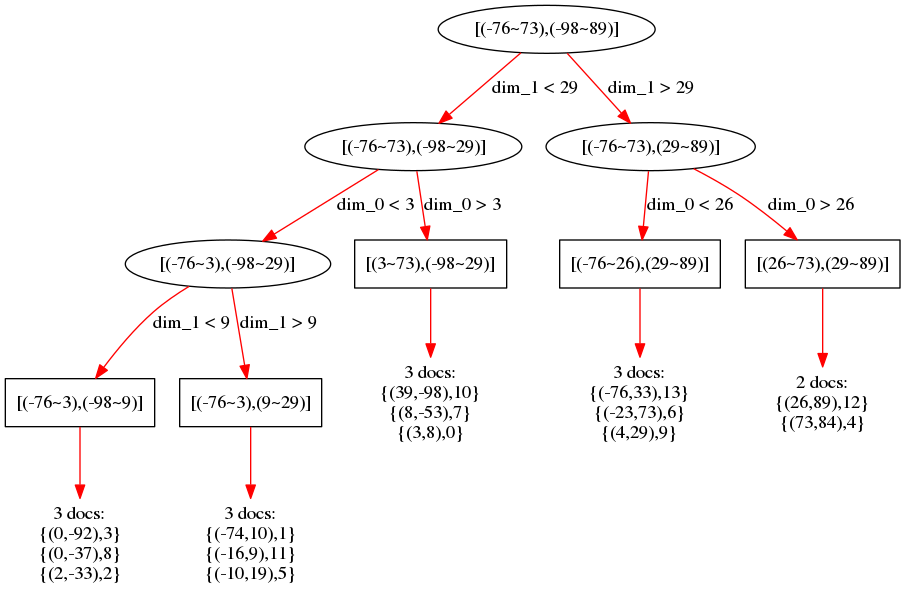
下图是上述问题的14个二维数值点集合构建的BKD-Tree在58搜索中的落地实践的结构示意图:
接下来,本文将从理论上详细阐述BKD-Tree方法的原理, 及其在58搜索引擎中的落地实践操作细节。
解决方案和原理分析
3.1. 解决方案讨论
大规模数值(类型)数据的范围查询问题,有很多可尝试解决方案:FST、BST、B-Tree、B+Tree、KD-Tree、KD-B-Tree、BKD-Tree。综合来看,本文描述的BKD-Tree解决方案最终比较好地解决了该问题,并且在58搜索引擎实践中落地。下面简要分解叙述这6中候选方案的思想原理和优缺点特性。
BKD-Tree是基于KD-B-Tree改进而来,而KD-B-Tree又是KD-Tree和B+Tree的结合体,KD-Tree又是我们最熟悉的二叉查找树BST(Binary Search Tree)在多维数据的自然扩展,它是BSP(Binary Space Partitioning)的一种。B+Tree又是对B-Tree的扩展。以下对这几种树的特点简要描述。
3.1.1. FST
FST(Finite State Transducers, 有穷状态转换器)是搜索引擎倒排索引中支持海量词语高效存储和快速查询的重要数据结构。数值范围查询问题较早的一种不高效的解决方案是:将数值范围查询问题转换成枚举数值范围内全部的可能取值,组成一个候选值集合,然后对该集合执行基于每个元素term的或查询。此方案缺点显而易见:在范围较大是候选值集合容量太大导致查询效率低下,因此实际使用中限制较多。
3.1.2. BST
二叉查找树BST是最基础的数据结构,它基于二分查找的思想,常见的AVL树和红黑树都是其实现自平衡树的变体, 能实现O(lgN)的插入和查找速度,查询非常快。主要通过特定的平衡树插入、删除操作后附带对树节点的调整以保持树的平衡性,从而实现高效的动态数据更新效果。缺点其一是不能处理多维数据,只针对1维数据场景,其二是不适宜处理海量大规模数据。简单解释如下:如果处理海量大规模数据必须要存储到磁盘上时, 因为是二叉树(不是多叉树), 导致数的高度相对多叉树较高, 而且数据本身(或数据本身的地址值)也是存储到树的中间节点(即非叶子节点)上的,导致对数据的读写要经历较长的节点路径(即树高), 考虑到每个树节点的访问都需要磁盘IO, 导致磁盘IO读写次数也较高,而磁盘IO的读写速度相对内存访问速度会慢很多,因此BST不适宜处理海量大规模数据。
3.1.3. B-Tree和B+Tree
相对于BST,B-Tree通过增加子节点的个数,减少了树的层级,解决了平衡二叉树磁盘访问效率低的问题,因此B树适宜处理大规模海量数据。同时,B树本身也是一种自平衡树。如同BST一样,B树可以自适应地动态更新数据,通过节点裂变的方式保持自平衡。因此B树的优缺点显而易见:处理1维数据插入、查询和动态更新效率高,但不适宜处理多维数据;同时相对适宜处理海量大规模数据,因为是多叉树,相对于二叉树来说降低了树高,从而降低了节点访问次数,也就是降低了磁盘IO的次数,数据访问效率较高。
然后需要注意B-Tree的一个重要特点是:其中间节点(即非叶子节点)上仍然是存储数值数据(或数据本身的地址值)的,不像下文提到的B+树中间节点不存储任何数值数据。这样带来的问题是中间节点因为同时存储了数据和子节点的索引数据,体积相对较大,如果都调入到内存中使得内存利用率不高,相对应地, 全部存储数值数据的叶子节点们不能将所有的数值数据都全部包括进来存储到磁盘上,势必导致磁盘空间利用不高。于是就有了B+Tree对这一特性的改进。
B+树(B+Tree)是对B树的一种改进,它与B树的不同点主要包括:
B+树的所有数据本身都存储在叶子节点上,非叶子节点只存储索引;而B树是叶子节点存储数据本身,非叶子节点既存储数据,又存储索引。
B+树的所有叶子节点被一个链表按照数据的从小到大的顺序串联起来。因此B+树上对1维数据的结果集的访问可以不用回溯到非叶子节点直接通过叶子节点链表就可以直接收集,效率比较高。
如前文提及,B+树的中间节点不存储数据本身这一特性,使其索引数据的内存利用率更紧凑,相应地数据磁盘存储的空间利用率更高,多叉树相对二叉树极大降低了树高使得费时的磁盘访问次数尽可能地减少了,最终使得B+树较适宜处理1维的海量大规模数据。
我们说B+树和B树、BST一样都不适宜处理多维数据,为什么呢?解释如下:
在处理1维数据时,B+树和B树、BST的平衡树形式或变种对插入、删除和修改操作都有比较高效的节点调整或裂变等方式来保证树的平衡性,从而保证O(lgN)的高效的时间复杂度。现在假设改为存储了多维数据,那么在插入、删除和修改操作后对相关节点的调整或裂变等附带操作就会带来较大的时间开销:存储1维数据时,父子节点兄弟节点之间的大小有序关系仅存在1个维度上,节点调整或裂变很容易适应1维上的有序关系;而存储多维数据时,父子节点兄弟节点之间的大小有序关系表现在多个维度上,节点调整或裂变操作还需要修改数量较多的离得较远的叶子节点或祖先节点(极限情况可能波及整棵树),导致数据动态更新效率变低。
当然有适合处理多维数据的专门的数据结构: KD-Tree。
3.1.4. KD-Tree
KD-Tree(K-Dimension-Tree),K维树, 顾名思义,是能处理多维数据的树结构。一个典型的KD-Tree的示例如下[2]: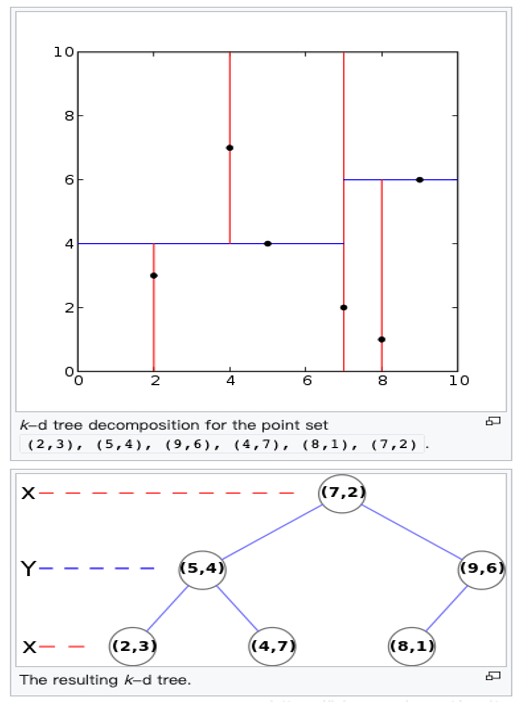
它是对6个二维数据点集合:(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)的存储。它先按照X维度值7把空间一分为二得到x<=7 和 x>7两部分左子树和右子树,接下来对左子树按Y维度4再一分为二,依次递归类推。注意KD-Tree切分数据的维度是依次轮替的:第一层先按X维划分,第二层按Y维度划分, 第三层按X维度划分,第4层再按Y维度划分…。
接下来循着前几节讨论树特性的几个方面简要讨论一下KD-Tree的特性:
首先KD-Tree适宜处理多维数据,查询效率较高。不难知道一个静态多维数据集合建成KD-Tree后查询时间复杂度是O(lgN)。
所有节点都存储了数据本身,导致索引数据的内存利用不够紧凑,相应地数据磁盘存储的空间利用不够充分。此外KD-Tree不适宜处理海量数据的动态更新。原因和B树B+树不适宜处理多维数据的动态更新的分析差不多,因为KD-Tree的分层划分是依维度依次轮替进行的,动态更新后调整某个中间节点时,变更的当前维度也同样需要调整其全部子孙节点中的当前维度值,导致对树节点的访问和操作增多,操作耗时增大。可见,KD-Tree更适宜处理的是静态场景的多维海量数据的查询操作。
3.1.5. KD-B-Tree
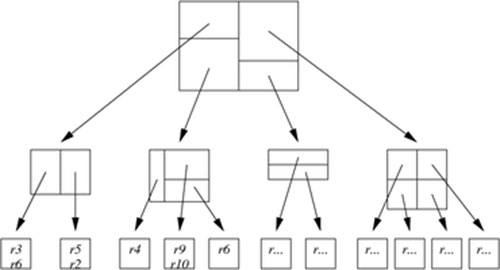
KD-B-Tree(K-Dimension-Balanced-Tree)顾名思义,结合了KD-Tree和B+Tree。它主要解决了KD-Tree的二叉树形式树高较高,对磁盘IO不够友好的缺点,引入了B+树的多叉树形式,不仅降低了树高,而且全部数据都存储在叶子节点,增加了磁盘空间存储利用率。一个KD-B-Tree结构的示意图如下。它同样不适宜多维数据的动态更新场景,原因同KD-Tree一样。
3.1.6. BKD-Tree
BKD-Tree(或BK-D-Tree,全称是Block-K-Dimension-Tree ),顾名思义它是一族或一群(Block)KD-Trees。即它其实是一个森林,不再是一颗树。如前所述,他最早是杜克大学的几位教授在论文[1]中提出的,它是基于KD-B-Tree设计的,同时结合了一种被称为 “logarithmic method" 的方法使得静态数据动态化。区别于KD-B-Tree,它有如下一些特性:
不同于KD-B-Tree的多叉树,BKD-Tree是完全二叉树。虽然二叉树不如多叉树的磁盘IO更友好,但是BKD-Tree仍然采用二叉树的形式主要原因可能在于:1)二叉形式实现起来更直观简便;2) 采用了完全二叉树的形式,类似于堆或优先级队列,能直接通过下标访问父节点或子节点,减少了存储在中间节点中的索引的存储空间,极简紧凑的中间索引节点占用空间更小,甚至中间节点可以一次性全部调入内存存储,调用内存访问索引节点效率更高。
同KD-B-Tree一样,BKD-Tree的全部数据都存储在叶子节点,海量的大规模数据都通过叶子节点存储在外部磁盘上。二叉树的层层分级依照不同子数据集综合统筹的维度空间的切分规划,最终分别落入到每个代表某个相对集中、紧凑和局部相似的局部空间的叶子节点上,全部叶子节点数据空间采用相邻连续存储的方式存储到外部磁盘上,空间利用率高。
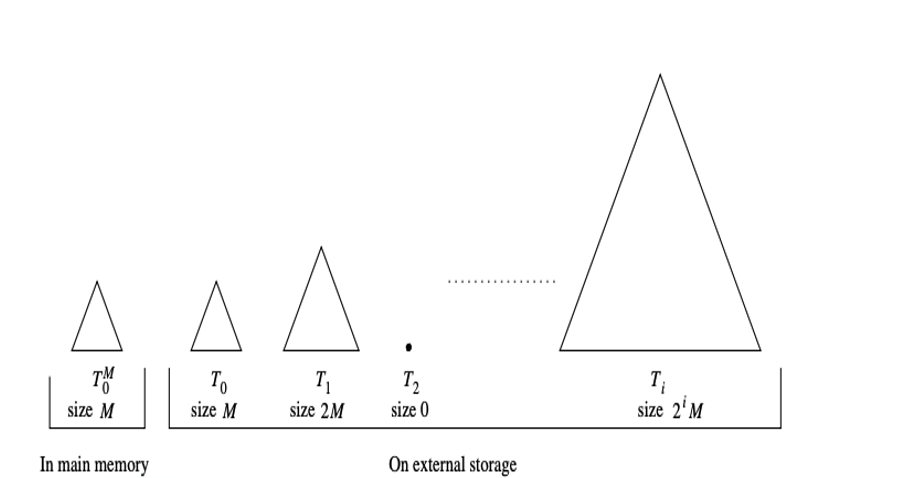
BKD-Tree最创新的特性在于它采用一种被称为 “logarithmic method" 的方法使得静态数据动态化, 极大提高了动态数据更小的效率。简单来说它的思想是采用一个二叉的KD-B-Tree的森林,新增加的数据存储在一个初始支持高效查询和动态更新的小规模数据结构上M,再通过M和多个小的二叉KD-B-Tree以一定的策略和时机合并成大的二叉KD-B-Tree以替换原结构的方式更新数据。此外数据删除可以采取标记删除的方式实现。实现了多维数值数据的高效率动态更新操作。下图是论文[1]中对这种动态更新方式的一个示意图。
更深入详细的BKD-Tree原理分析见后文章节。
综合以上,下表总结了这几种Tree的使用特点。
| 名称 | 全称 | 能处理多维是数据 | 处理海量数据的空间利用率 | 是否适宜数据动态更新 |
|---|---|---|---|---|
| BST | Binary Search Tree | 否 | 低 | 单维适宜 |
| B-Tree | Bushy Tree | 否 | 中 | 单维适宜 |
| B±Tree | Bushy Plus Tree | 否 | 高 | 单维适宜 |
| KD-Tree | K-Dimension-Tree | 是 | 低 | 多维不适宜 |
| KD-B-Tree | K-Dimension-Balanced-Tree | 是 | 高 | 多维不适宜 |
| BK-D-Tree | Block-K-Dimension-Tree | 是 | 高 | 多维适宜 |
3.2. BKD-Tree原理分析
本节将重点详细展开分析BKD-Tree的原理和算法过程,包含构建、查询、数据动态更新过程。
3.2.1. BKD构建算法分析
下面的伪代码示意图BuildBKD(A, k, leavesOffset, leavesCount) 表达了一个递归构建bkd树结构的算法过程。其中:A:输入数值元素数组,k:维度, leavesOffset:当前子树包含的叶子节点集合起始序号 ,numLeaves:当前子树中叶子节点个数。
在初始阶段,输入元素集合整体对应的叶子节点个数numLeaves值的计算,依赖于一个外部设定的配置值 config.maxPointsInLeafNode,其含义为叶节点中最大允许的原始数值数据元素的个数,实际中一般设计为512或1024。numLeaves 可以简化理解为由 count(A) / config.maxPointsInLeafNode计算得到。其中count(A)是原始输入数据集合中元素的个数。
于是BKD递归构建过程BuildBKD(A, k, leavesOffset, numLeaves) 初始调用的参数为BuildBKD(A, k, 0, numLeaves)。
BuildBKD(A, k, leavesOffset, numLeaves)1. if numLeaves == 1 /*递归退出条件*/2. then sortDim <- DecideSortDim() /*确定当前叶子节点中原始数据数据的排序维度*//*按sortDim序号的维度对当前叶子节点中数据排序*/3. SortLeafValues(sortDim)/*将当前叶子节点所包含的原始数值数据集合块数据写入DataOutput外部文件,即.bkd.data文件*/4. WriteLeafBlockToDataOutput(A, leavesOffset,DataOutput)5. else splitDim <- DecideSplitDim() /*确定当前空间切分的维度序号splitDim*//*根据完全二叉树性质计算空间切分后左子树中叶节点个数*/6. numLeftLeafNodes <- GetNumLeftLeafNodes(numLeaves)/*计算空间切分后左子树中含原始数值元素个数*/7. leftCount <- numLeftLeafNodes * maxPointsInLeafNode/*经典选择问题,使得A中前leftCount个元素的splitDim维度值都不大于其后的元素*/8. Select(A, splitDim,leftCount)/*切分后右子树中叶子结点起始序号*/9. rightLeavesOffset <- leavesOffset + numLeftLeafNodes/*递归构建切分后的左子树*/10. BuildBKD(A, k, leavesOffset, numLeftLeafNodes)/*递归构建切分后的右子树*/11. BuildBKD(A, k, rightLeavesOffset, numLeaves - numLeftLeafNodes)
简要分析一下上述BuildBKD递归构建算法过程:
递归调用的退出条件是 当前子树所含的叶子节点个数为1(numLeaves==1),此时在连续的空间切分后,当前子树已经只能包含1个叶子节点了,因此不需要再继续切分了。只需要对其所包含的原始数值数据按某个sortDim维度先排个序,然后写入到某个存储数据值本身的外部介质中即可(通常是一个磁盘文件)。
否则进入numLeaves>1 的情况,因为叶子节点个数不止1个,所以要继续切分空间,具体操作过程大体如下:
以某种适当的策略选取合适当前递归上下文的切分维度序号:SplitDim;
通过父节点为根的子树的叶子节点个数numLeaves结合完全二叉树性质确定未来二叉空间切分后左子树中叶子节点个数numLeftLeafNodes;
计算空间切分后左子树中含原始数值元素个数leftCount, 显然leftCount = numLeftLeafNodes * config.maxPointsInLeafNode;
核心过程:Select(A, splitDim,leftCount), 经典选择问题,选择后要使得A中前leftCount个元素的splitDim维度值都不大于其后的元素。
同时不难得出:切分后右子树中叶子结点起始序号rightLeavesOffset可由leavesOffset + numLeftLeafNodes 计算得到;
最后分别递归构建切分后的左子树BuildBKD(A, k, leavesOffset, numLeftLeafNodes) 和右子树BuildBKD(A, k, rightLeavesOffset, numLeaves - numLeftLeafNodes)即可。
至此BKD递归构建算法过程分析完毕。虽然过程似乎并不复杂,然而有如下几个细节问题仍需解决:
当BuildBKD进入退出条件numLeaves==1分支后,在写当前叶子结点到外部输出介质之前为何还需要按某个sortDim维度对其数据进行排序呢?其中选择sortDim的策略又是什么呢?
写当前叶子结点到外部输出介质,具体有什么高效和优化的落地实践方案?比如能否压缩数据以实现尽可能小的数据空间占用,这样后期读BKD数据时磁盘IO也更加友好读取效率也更高。
进入进入numLeaves>1 的分支后,切分维度splitDim的选择策略是什么?换句话说怎么选当前的切分维度才比较合适?
经典选择过程Select(A, splitDim,leftCount)应该采用什么高效优化的选择算法策略来进行?它的时间复杂度是多少?有没有一些技巧性的优化加速过程?
以上问题1,2,3,4正是下文要重点分析的内容,其解决方案也正是基于数值索引的高效查询问题在58搜索引擎实践落地的重要方面,此处留待后文详述。不过还是简单分析一下问题1:理论上叶子结点中的原始数值数据集合以任何一种顺序存储到外部介质,对未来的BKD数据读取和查询过程的影响基本是无差别的。之所以按特定策略选择出的维度sortDim值提前排序了,是为了提高问题2涉及的叶节点中数据存储的压缩效率,至于sortDim维度选择策略细节以及为什么就能提高数据存储的压缩效率,留到后文详细展开阐述。
3.2.2. BKD查询过程分析
假定[minBounds, maxBounds]是由两个k维数值数据构成的k维数值数据的一个范围(Range),那么在BKD结构上基于范围[minBounds, maxBounds]的范围查询问题基本就代表了BKD上的全部查询类型:
要查询返回BKD结构上的全体数据集合,只需要将目标范围[minBounds, maxBounds]设置为[-∞,+∞]然后执行bkd上的范围查询即可;
要查询返回BKD结构上是否精确包含某个数值x, 只需要将目标范围[minBounds, maxBounds]设置为[x,x]然后执行bkd上的范围查询即可;
一般来说,对BKD等Tree类数据结构全部节点的访问或查询通常要用到软件设计模式中一种常用的设计模式:Visitor(访问者)模式[3]。
Visitor模式是典型的面向对象软件的24种基础设计模式之一,它的意图通常为表示一个作用于某对象结构中各元素的操作。它是你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。下图是该模式的一个典型的结构示意图。
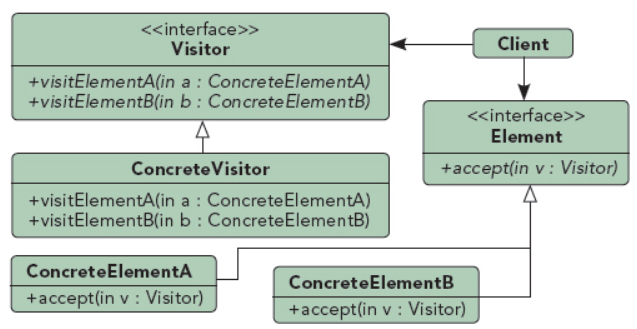
一个典型的BKD-Tree的Visitor类可以设计示意如下:
class BKDVisitor {/*当前节点及其所有子树中元素集合的范围 与 目标范围 的空间集合关系*/enum Relation {INSIDE_QUERY, /*完全在目标范围内部*/OUTSIDE_QUERY, /*在目标范围外部*/CROSSES_QUERY /*跟目标范围部分交叉*/};public:/*比较当前节点及其所有子树中元素集合的范围 与 目标范围 的空间集合关系*/virtual Relation Compare(minBound, maxBound) = 0;/*Compare()返回INSIDE_QUERY时,执行操作的接口*/virtual Visit(int docId) = 0;virtual Visit(docIdSetIterator it) = 0;/*Compare()返回CROSSES_QUERY时,执行操作的接口*/virtual Visit(int docId, minBound, maxBound) = 0;virtual Visit(docIdSetIterator it, minBound, maxBound) = 0;};
不难理解,BKDVisitor类中的注释已经非常清楚地表明了这个Visitor类从BKD-Tree的根节点起访问全部子孙节点过程中要执行的操作。我们只需继承该纯虚基类,重新实现5个虚接口函数,将相关的docid和数值数据收集起来,就可以方便地完成基于BKD-Tree数据结构上数据的范围查询过程。
3.2.3. BKD数据动态更新策略分析
BKD一改传统Tree采用调整父子兄弟节点或节点裂变等方式来动态更新数据的方式,采用"对数法"[logarithmic method] 策略动态更新:
在内存中存储一个大小为M的完全二叉树作为Buffer;
在外部存储器(磁盘)上保存的第i棵树,要么是空的,要么大小是M * 2^i;
每次插入新数据的时候,如果buffer没满, 那就直接插入到内存中的Buffer;如果内存buffer满了,则将目前磁盘上所有的树和buffer合并。
假设磁盘上最大的树的大小是M* 2^i, 那么合并后,新生成的一棵树的大小将是M* 2^(i+1)。
数据删除可以采取以位图标记逻辑删除的方式进行。而修改操作则转化为先删除在新增两个操作进行。
BKD-Tree在58搜索中的实践操作
上面我们已经分析了BKD-Tree的主要算法过程的原理,下面将详细展开阐述BKD在58搜索引擎中实践落地的具体策略与细节。我们称包含数值数据的索引为Point Index(点数值索引)。Point 索引以BKD实现,包含多个字段的数值数据,每一个字段的Point Index是一个独立的BKD-Tree。全部字段的PointIndex持久化到磁盘上以.bkd.data、.bdk.index、.bkd.meta为文件名后缀的3个文件分别存储,分别称为data原始(数值)数据文件、索引文件和meta元数据文件。
4.1. BKD数据组织方式
BKD-Tree结构的数据大体包含了原始(数值)数据、索引数据和meta元数据3部分:
原始(数值)数据:即BKD要读取数据的数值型数据集合数据。这类数据一般规模大,数据元素本身因为维度可能也不小,每个维度数值占用字节也可能不小,因此所占空间一般很大,实际中必须存储到外部磁盘上,读取是通常通过磁盘文件内存映射(Mmap)的方式动态按需调入内存使用,按需淘汰,由操作系统策略管理。这类数据实际存储有数据压缩的必要性,一来本身所占空间就大,二来如果能显著压缩存储空间后通过内存映射方式加载进内存后也能显著降低内存使用量,将更宝贵的内存资源尽可能留给其他两类数据完全加载到内存来提供数据的高效访问辅助。
索引数据:可以简单理解为自根向下遍历bkd树节点所需要的那些辅助数据, 比如splitPackedValues和splitDimensionValues。这类数据本身所占空间比不是很大(规模可分析,见后文对splitPackedValues和splitDimensionValues规模的分析),但为了提高BKD树的查询速度,一般尽可能将这类数据一次性全完加载到内存用于BKD树读取查询。而内存容量有限,落地实践中一般都尽可能地压缩BKD索引数据所占空间。
meta元数据:通常是一些构建和访问BKD树需要的维度相关的前置配置参数值,比如config.numDims, config.bytesPerDim, pointCount, leafCount等。meta元数据一般都是一个常量值,所占空间不大,压缩存储的必要性也不大,使用时也是一次性完全加载到内存中提高高效内存访问。
实践中我们将以上3部分数据分别单独存储到独立的磁盘文件上,以文件名后缀区分,分别是:
.bkd.data文件 - 存储原始数值数据;
.bdk.index文件 - 存储索引数据;
.bkd.meta文件 - 存储meta元数据;
综合以上,.bkd.data文件和.bdk.index文件存储的两类数据:原始数值数据和索引数据有压缩存储必要性的。后文将详细展开论述压缩存储策略。
4.2. BKD数据压缩存储策略
如前文描述,BKD-Tree中存储的两类数据:原始数值数据和索引数据是有压缩存储必要性的。对于原始数值数据而言,其被存储到.bkd.data文件中, 使用时通过Mmap内存映射方式动态按需加载进内存,由操作系统策略管理。如果显著压缩了这类数据的大小,将会降低Mmap加载映射到内存的空间占用,将更宝贵的内存资源尽可能留给其他两类数据完全加载到内存来提供数据的高效访问辅助。而索引数据是提供高效访问和便利BKD树的辅助数据,只有完全加载到内存才能提供高效访问。而要想完全加载到内存,就必须尽可能压缩这部分数据。当前还有个前提,索引数据本身所占存储空间大小适度,不是特别大,也不是特别小。如果特别大则即使压缩之后也可能在一些极端场景下没有完全加载到内存的可能性;而如果特别小那也没有压缩的必要,因为特别小直接加载进内存即可。(meta元数据之所以未压缩就是因为其所占空间太小,没有压缩的必要,后文还将会详细展开解释一点。)
本着索引数据尽可能压缩空间存储的原则出发,接下来将分别阐述原始数值数据和索引数据的BKD压缩存储方法与策略。
4.2.1. 原始数值数据的压缩存储策略
前文3.2.1.节伪代码BuildBKD(A, k, leavesOffset, numLeaves) 中第2~4行中的WriteLeafBlockToDataOutput(A, leavesOffset,DataOutput) 所做的事情,就是将当前叶子节点所包含的原始数值数据集合块数据写入DataOutput外部文件,即文件名后缀为.bkd.data文件。下面重点分析该算法细节。
BKD的叶子节点要存储的原始数值数据包括docIds和pointValues两部分,pointValues是多维数值数据本身,每个pointValue会绑定存储一个对应的docId,docId一般是4字节int类型即可满足应用场景。通过docId关联来定位某个pointValue值属于那篇文档。bkd上执行查询最终返回的结果也是<pointValue, docId>数据对的集合。一般在构建BKD-Tree前会原始数值数据集合组织成如下图所示的连续数组存放(我们从现在起约定该初始数值数据输入数组为A,其元素个数为count(A)), 可见该数组A是由count(A)个输入数据元素构成,每个数据元素的初始存放格式是若干固定维度的数值之后紧跟一个该数值所述的docId。

前节3.2.1中的递归算法BuildBKD本质上就是通过历次中间节点划分空间时对该原始数值数据数组A进行多次选择,以重新排列元素位置的过程(此处的选择算法策略后文将详细展开论述其细节),最终递归算法执行到叶子节点,此时叶子节点包含的原始数值数据只是初始数组A的一个子集M, WriteLeafBlockToDataOutput(M, leavesOffset,DataOutput) 要做的就是把子集M中的数据压缩后存储到外部data文件(后缀为.bkd.data)中去,参数中的leavesOffset很容易理解,就是子集M在全集A中的起始偏移量。原始数值数据压缩存储显然包含两部分:docIds和 pointValues,下面分别展开详述。
4.2.1.1. DocIds压缩存储方案
下面的伪代码WriteDocIds(docIdsArr, count, dataOut) 表达了 docIds的压缩存储策略。参数说明:docIdsArr是叶子节点的数值数据数组,count是其元素个数, dataOut是data file(即文件名后缀为.bkd.data的文件)的文件句柄。该算法定义了如下5种枚举类型表明5种不同的docIds分布情形,在一开始以1个字节写入,读取时以该1字节值对应枚举值确定docIds存储样式STYLE。
enum DOC_ID_STORE_STYLE_ENUM {CONTINUOUS_IDS,BITSET_IDS,DELTA_16_STYLE,MERGE_24_STYLE,SIMPLE_32_STYLE};WriteDocIds(docIdsArr, count, dataOut)1. dataOut->WriteVint(count)2. (min, max, maxMinDiff, strictAsc) <- DecideMinMaxStrictAsc(docIdsArr)3. if strictAsc == true4. then if maxMinDiff == count5. then dataOut->WriteByte(CONTINUOUS_IDS)6. dataOut->Writeint(docIdsArr[0])7. else if count >= maxMinDiff/168. then dataOut->WriteByte(BITSET_IDS)9. WriteIdsAsBitSet(dataOut, docIdsArr)10. else if maxMinDiff <= 0xFFFF11. then dataOut->WriteByte(DELTA_16_STYLE)12. dataOut->WriteInt(min)13. WriteDiffsOverMin(dataOut, docIdsArr)14. else if max < 0xFFFFFF15. then dataOut->WriteByte(MERGE_24_STYLE)16. WriteMerge24Docids(dataOut, docIdsArr)17. else dataOut->WriteByte(SIMPLE_32_STYLE)18. WriteSimple32Docids(dataOut, docIdsArr)
下面简要分析一下WriteDocIds()算法过程:
第1行:存储docId个数;第2行:只需遍历一趟数值数组docIdsArr即可统计获得最小值/最大值: min/max, 最大值与最小值的差值maxMinDiff = max - min; strictAsc是个bool变量,其含义是判断数组docIdsArr元素是否严格单调递增,即任意一个元素都严格小于其前一个元素值。
第3~6行:如果数组严格单调递增,且maxMinDiff == count, 表明是连续无空隙的数值序列,直接写出1个字节CONTINUOUS_IDS值,同时将第1个值写出即可。
第7~9行:虽然是严格单调递增数组,但是有空隙,不过数据分布还挺紧密,紧密程度表现为元素个数超过了maxMinDiff/16,则以bitset位图方式存储更省空间;
第10~13行:如果maxMinDiff < 0xFFFF, 即全部差值都可用16位整形表达,则存储1字节样式DELTA_16_STYLE,同时存储最小值min和所有差值,注意差值存储16位short类型整数即可。
第14~16行:如果最大值max < 0xFFFFFF, 即最大值可用24位表达,则WriteMerge24Docids()内部策略是依次将连续的8个docId的每个数值的有效的低24位依次按顺序按位或操作,合并成3个int64_t的长整型存储,因为24 * 8 等于3 * 64,bit位数刚刚好,也节省了存储空间。
最后17~18行:前面所有情况都不是,则原样存储docId 数值数据即可。
不难发现,WriteDocIds压缩存储策略对空间的节省达到了极致。
4.2.1.2. Point Values压缩存储方案
Point values压缩存储方案的核心思想依赖于一个概念:数据集合的 “基数”(cardinality),相关定义如下:
定义4-1. Cardinality : 基数 - 是一个数据集合中独一无二数据的数量。
定义4-2. High Cardinality : 高基数 - 指一个数据集合中独一无二的数据的数量占比非常高,基本上不重复或重复率非常低。
定义4-3. Low Cardinality : 低基数 - 指一个数据集合中独一无二的数据的数量占比非常低,有大量重复的数据或重复率非常高。
通过以上定义不难得出:如果一个数据集合的基数cardinality越大,即越High Cardinality, 其数据重复度越小,也就是说数据集合中充斥着大量彼此互不相同的数据,因此这样的数据集合较难以压缩存储,因为压缩存储的本质就是要尽可能找出最大相同的部分"最大公约数","最大公约数"只需要存储一份,从而达到压缩节省存储空间的目的。
对应到本文的多维度的point values数值数据集合中,基数(cardinality)概念涉及2个:sortDimCardinality和leafCardinality。
1.sortDimCardinality: 顾名思义sortDimCardinality直观理解是sortDim这个维度(每个数值元素都有config.numDims维度,sortDim值 属于 [0, config.numDims) )上值的集合的基数。那么sortDim怎么确定呢?这也是前文2.2.1节最后留的问题1。此处作出解释。首先看看prefix有关的概念:prefixLengthsOut 和 prefixValuesOut。如下ComputeCommonPrefixLength伪代码过程所示:
ComputeCommonPrefixLength(pointsArr, count, prefixLengthsOut, prefixValuesOut)1. prefixValuesOut <- pointsArr[0]2. for dim <- 0 to config.numDims3. do prefixLengthsOut[dim] <- config.bytesPerDim4. for i <- 1 to count5. do for dim <- 0 to config.numDims6. do if prefixLengthsOut[dim] != 07. then prefix <- PrefixCompare(prefixValutsOut[dim], pointsArr[i][dim])8. prefixLengthsOut[dim] <- Min(prefixLengthsOut[dim], prefix)
不难看出:ComputeCommonPrefixLength() 计算求出了count个元素组成的数值集合pointsArr 中的每个元素在各个维度上(总的维度数是config.numDims)所有值字节序列的最长公共子序列的长度:prefixLengthsOut。对于第K维, 如果prefixLengthsOut[k] 等于0 ,说明k维上所有值都不相同,都是独一无二的;如果prefixLengthsOut[k]值等于config.bytesPerDim, 则说明k维上所有值都是完全相同的。prefixValuesOut 存储了数组中第一个元素的值,那么很容易知道任意k维度上全部数据值的最长字节序列前缀是prefixValuesOut[0…prefixLengthsOut[k] ]。
计算好了prefixLengthsOut信息后,下面的伪代码过程DecideSortDim() 是真正计算确定sortDim值的。
DecideSortDim(pointsArr, count, prefixLengthsOut)1. sortDim <- 0; sortDimCardinality <- INT_MAX2. for dim <- 0 to config.numDims3. do prefix <- prefixLengthsOut[dim]4. if prefix < config.bytesPerDim5. then bitset <- GetFixedBitSet(256)6. for i <- 0 to count7. do bucket <- pointsArr[i][dim][prefix] & 0xFF8. bitset.Set(bucket)9. if bitset.Cardinality() < sortDimCardinality10. then sortDim <- dim11. sortDimCardinality <- bitset.Cardinality()
不难分析总结出sortDim的选择策略如下:
sortDim的选择策略: 对于多维度数值数组pointsArr中任意元素pointsArr[i] , 令 任意维度k ∈ [0, config.numDims), prefix = prefixLength[k] 是全部元素在k维度上的值的字节序列的最长公共前缀长度,则firstDiffByte = pointsArr[i][prefix]是第i个元素对应的k维度上全部元素值字节序列中从前往后数第一个不全部相同的字节值。称count(pointsArr)个firstDiffByte值组成的集合中独一无二的元素的数量为sortDimCardinality。全部维度上sortDimCardinality值最小的那个维度即为 sortDim。
跳出现象看本质,既然已经明确了sortDim的选择策略,那么为什么要这么选择sortDim呢?假使我们就随便选择一个别的维度作为sortDim有何坏处呢?真正要想彻底理解这个问题,其实需要在看完本节后面Point Values压缩存储算法过程后才能理解得深刻。这里提前简单阐述一下:根据定义知道sortDim维度上prefix之后的firstDiffByte首字节值集合是最低基数的(最Low Cardinality),换句话说这个sortDim维度上的firstDiffByte字节是重复度最大的,值的重复度越大,那么存储这个字节值的集合时,压缩存储的效果空间就最大,其它的维度按此字节值压缩存储节省的空间都不如这个大。
计算获得sortDim后,就可以对pointsArr按sortDim上值prefix长度之后的值字节序列从小到大进行原地排序,比如可以采取快速排序算法进行原地排序,考虑到一般情况下每个叶子节点中原始数值元素个数一般最大不超过confog.maxPointsInLeafNode,该值通常设置为512或1024, 元素个数很小,因此此处的sortDim排序执行的会非常快,一些特殊场景下比如叶子节点中原始数值元素个数很小比如<100时,像插入排序或冒泡排序法也可能是可取的排序方法,不一定非得是快速排序方法。那么问题来了,为什么要按照sortDim排序呢?因为最多1024个数值数据已经来到了叶子节点上,不排序就直接存储,未来BKD查询的时候也能依次遍历不排序的存储数据而取得候选docIds集合。原因是后文基于sortDim上firstDiffByte的压缩存储方式[也叫runLength压缩]依赖于sortDim的排序。
2.leafCardinality: 叶节点基数(Leaf Cardinality) 反映了叶子节点原始数值数组pointsArr依次相邻的互不相同的元素的数量,它是Point values压缩存储策略中绕不开的一个指标。下面给出其伪代码ComputeCardinality():
ComputeCardinality(pointsArr)1. cardinality <- 12. for i <- 1 to count(pointsArr)3. do if pointsArr[i] != pointsArr[i-1]4. then cardinality <- cardinality + 15. return cardinality
可见ComputeCardinality计算所得不是客观事实上的pointsArr数组中绝对互不相同的元素的数量,而是数组pointsArr依次相邻的互不相同的元素的数量,为什么呢?原因是存储数组值的时候是依次按着从前往后的顺序存储的,每当遇到一个不同的元素值,就把在此之前遇到的一连串相同的元素值都压缩地存储起来。这种依次依序存储的方式决定了leafCardinality只需要计算依次相邻的互不相同的元素的数量即可。当然我们知道,计算依次相邻的互不相同的元素的数量只需要对数组执行一趟遍历即可;如果计算客观事实上的pointsArr数组中绝对互不相同的元素的数量,那复杂度会高很多,这点也是我们不能承受的。
经历了以上这些预备步骤之后,下面正式进入Point values数值数据的压缩存储过程,包括写前缀WriteCommonPrefixes和写后缀WriteSuffixes两个过程:
1.WriteCommonPrefixes: WriteCommonPrefixes 伪代码如下所示,只需按照维度次序依次存储每个维度的值前缀长度和前缀字节序列即可。
WriteCommonPrefixes(prefixLengths, prefixValues, dataOut)1. for dim <- 0 to config.numDims2. do dataOut->WriteVInt(prefixLengths[dim])3. dataOut->WriteBytes(prefixValues[dim][0...prefixLengths[dim] ])
2.WriteSuffixes: 顾名思义WriteSuffixes是用来存储全部维度数值的后缀数据的。
WriteSuffixes(pointsArr, count, prefixLengths, leafCardinality, sortDim)1. prefixLenSum <- Accumulate(prefixLengths)2. if prefixLenSum == config.packedBytesLen3. then dataOut.WriteByte(-1)4. else if leafCardinality == count5. then (lowCardinalityCost, highCardinalityCost) <- (1, 0)6. else numRunLens <- ComputeRunLens(sortDim, prefixLens)7. highCardinalityCost<-count*(config.packedBytesLen-prefixLenSum-1)+2*numRunLens8. lowCardinalityCost<-leafCardinality*(config.packedBytesLen-prefixLenSum+1)9. if lowCardinalityCost <= highCardinalityCost10. then dataOut.WriteByte(-2)11. WriteLowCardSuffixes()12. else dataOut.WriteByte(sortDim)13. WriteHighCardSuffixes()
WriteSuffixes伪代码过程简要解释如下:
第1行:计算全部维度上公共前缀长度之和prefixLenSum;
第2~3行:如果prefixLenSum 等于config.packedBytesLen,说明全部数值都相同,直接记录写一字节标识值-1即可。
第4~5行:如果leafCardinality等于数值集合元素个数count,说明全部数值都彼此互不相同,重复度最低,是极其的高基数(High cardinality)情况,应该走highCardinality场景存储,故让lowCardinalityCost等于1, highCardinalityCost 等于0,这样后面这两个值比较大小时自然能cost代价较小的highCardinality场景的存储方案;
第6~7行:假定进行run-length压缩,ComputeRunLens()计算获得可以执行numRunLens次run-length压缩,于是以第7行的高基数代价计算公式可以计算出执行高基数的代价:highCardinalityCost = count*(config.packedBytesLen-prefixLenSum-1)+2 * numRunLens。第8行是假定进行低基数压缩存储的低基数代价:lowCardinalityCost = leafCardinality*(config.packedBytesLen-prefixLenSum+1)。这两个公式的详细理解见下文对高低基数压缩存储的过程的解释。
第9~13行:比较lowCardinalityCost和 highCardinalityCost 谁的代价小,就采用其代表的压缩存储方式。
WriteLowCardSuffixes(pointsArr, count, prefixLens, dataOut)1. cardinality <- 12. lastPoint <- pointsArr[0]3. for i <- 1 to count4. do if pointsArr[i] == lastPoint5. then cardinality <- cadinality + 16. else dataOut.WriteVInt(cardinality)7. dataOut.WritePoint(lastPoint)8. cardinality <- 19. lastPoint <- pointsArr[i]10. dataOut.WriteVInt(cardinality)11. dataOut.WritePoint(lastPoint)
WriteLowCardes对应低基数情况下数值后缀压缩存储算法过程,低基数顾名思义就是指count个数值的数组pointsArr中独一无二的数值数量"低", 即有大量重复数值,重复度高。那么很自然的我们想到可以把数组pointsArr中连续相同的数值只存1份以节省存储空间。这就是低基数情况下数值后缀压缩存储的核心思想。循着这个思想,伪代码相对容易理解,此处略去不再详述。
WriteHighCardSuffixes(pointsArr, count, sortDim, prefixLens, dataOut)1. if config.numDims != 12. then WriteActualBounds()3. compressionByteOffset <- sortDim*config.bytesPerDim + prefixLens[sorDim]4. prefixLens[sortDim] <- prefixLens[sortDim] + 15. for i <- 0 to count6. do runStep <- RunLens(pointsArr, i, compressionByteOffset)7. prefixByte <- pointsArr[i][compressionByteOffset]8. dataOut.WriteByte(prefixByte)9. dataOut.WriteByte(runStep)10. WriteSuffixesRange(pointsArr, i, i+runStep, prefixLens)11. i <- i + runStep
上面伪代码WriteHighCardSuffixes表达了高基数情况下数值后缀压缩存储算法过程。与低基数情况相反,高基数场景下数组pointsArr中独一无二的数值数量"高",即重复度极低,大量元素都是彼此互不相同的。显然不能用低基数的思想去压缩数据了。高基数场景压缩的核心思想是根据每个数据的compressionByteOffset 这个字节位上的字节值的重复程度进行压缩。从上述第3行可以看出compressionByteOffset就是sortDim维度上公共前缀长度后第一个字节位置。第6行RunLens()过程其实就是在计算数组pointsArr中从当前数值元素下标i开始compressionByteOffset 字节位上值连续相同的个数runStep。每runStep个数值的compressionByteOffset位上字节就可以只存储一份,以达到节省空间的目的。当然该字节位之后的部分仍然正常差异化存储,见第10行。那么,这种压缩思想的合理性在哪呢?稍微往深度思考不难发现:如果sortDim维度上compressionByteOffset字节位置上字节值的重复度尽可能高的话,此处的高基数压缩思想就有可能有较好的省空间效果。而通过前文的描述我们知道sortDim选择的原则就是sortDimCardinality值最小原则选取出来的,即该维度上该字节处的值重复度就是最高的,那么这样压缩就存在可能性。再加上WriteSuffixes()过程第9行已经对这两种压缩代价提前进行了预估和比较。因此有理由相信此处的压缩思想是合理的。
经过以上高低基数场景下压缩伪代码的分析,相信highCardinalityCost和lowCardinalityCost两个计算公式应该不难理解了。
4.2.2. 索引数据压缩存储策略
索引数据压缩(Pack Index)主要做的事情是:包装3个数组:leafBlocksFps和splitPackedValues、splitDimensionValues, 将完全二叉树形式的BKD-Tree自根节点向下以深度优先遍历方式表达为一个紧凑的字节数组。leafBlocksFps和splitPackedValues、splitDimensionValues、leafBlocksFps 3个数组的含义如下:
leafBlocksFps :顾名思义leafBlocksFps指的是leaf-blocks-file-pointers即叶节点数据块存储到外部磁盘文件上的文件指针偏移量。前文2.2.1节中BKD构建过程BuildBKD(A, k, leavesOffset, numLeaves)伪代码第4行WriteLeafBlockToDataOutput(A, leavesOffset) 过程就包含了将每个叶子节点的原始数值数据写到外部磁盘文件上去,并记录下每个叶子节点对应文件指针偏移量。显然这个叶子指针存储的文件指针偏移量数组的大小就等同于叶子节点个数。不难得出,在执行Pack Index过程时该数组元素的值都是确定已知的。
splitPackedValues 和 splitDimensionValues
设想未来可能的在BKD上进行范围查询的操作思路:对BKD表达的完全二叉树,执行自根节点开始的深度或广度优先的递归遍历过程中,遍历到每个节点都需要知道当前节点是在K维数值的哪个维度即splitDimension上以该维度的哪个值即splitPackedValue进行的空间划分,将范围查询的目标范围值中特定维度splitDimension上的值与此splitPackedValue值进行大小比较,以确定递归下一步是往左子树还是右子树走,达到匹配相应的“剪枝”效果。而划分维度splitDimension和划分维度值splitPackedValue是怎么存储成紧凑的数组形式的呢?策略如下: 要构建BKD的初始静态数据集合A, 通过集合元素大小count(A)直接计算可得到未来存储成bkd完全二叉树形式的叶子节点个数numLeaves, 不难发现:有numLeaves个叶子节点,就意味着BKD构建过程是执行了numLeaves-1次空间划分而成。因此,splitPackedValues 和 splitDimensionValues两个数组大小都是numLeaves-1。比如:splitPackedValues[3] = 0x32143026, splitDimensionValues[3] = 1 可能代表的还以就是 第3次空间划分时,按照多维度数值的第1维度的上的0x32143026值进行的空间划分, 左子树上的数据的第1维度上值都小于或等于0x32143026,右子树上所有数据的第1维度值都大于0x32143026。
叶节点块数据文件偏移量、空间切分维度和维度值3个信息是查询访问BKD树不可缺少的,存储这3个值的数组大小基本与叶子节点个数numLeaves相当。正如前文3.2.1.节已经提及的numLeaves 可以简化理解为由 count(A) / config.maxPointsInLeafNode 计算得到。其中count(A) 是原始输入数据集合中元素的个数, 而config.maxPointsInLeafNode实际中通常设置为512或1024。
简要做个算术题:假定count(A) 为100亿(10^10), config.maxPointsInLeafNode为512,那么有numLeaves = (10^10) /512个叶子结点,则这3个数组的规模都大体是(10^10) /512。leafBlocksFps数值元素类型一般是int64_t,字节数为8(文件偏移量数值一般是64位整数才能包含),splitDimensionValues数组元素一般是uint8_t就可以(因为实际中对维度数值大小一般限定在16或32维以内,太大的维度实际中没用应用意义,uint8_t足够存储), splitPackedValues数值元素原始数值每一维度的字节数,假定每一个维度都是double类型,子节数为8。于是3个数组合计占用内存空间为:(8+1+8) * (10^10)/512=332MB。这332M内存空间能否适度压缩呢?答案是肯定的。
本着索引数据尽可能压缩空间存储的原则,压缩版Pack Index算法过程伪代码示意如下:
RecursivePackIndex()是递归执行PackIndex的函数,其各参数含义是:
lastSplitValues - 对bkd深度优先遍历过程中上次在父节点进行某个维度splitDim上进行空间切分的该维度上切分值(一般是字节序列), 注意该值的初始值通常采用全是0的一个字节序列;
minBlockFp - bkd深度优先遍历中当前子树包含的叶节点数据存储在外部文件上的最小文件指针偏移量。(一般是一个int64_t类型值);
leavesOffset - 当前子树包含的叶子节点在外部文件上存储的文件偏移量数组的下标;
numLeaves - 当前子树包含的叶子节点个数;
isLeft - 当前子树是否是父亲节点的左子树, false值意味是右子树;
blocksOut - 输出数据块数组,最终所有的packedIndex数据字节流以及二叉树的父子逻辑关系都会存储到blocksOut里;
writeBuffer - 字节数据输出缓冲区
RecursivePackIndex(lastSplitValues, minBlockFp, leavesOffset,numLeaves, isLeft, blocksOut, writeBuffer)1. if numLeaves == 1 /*递归退出条件*/2. then if isLeft == true /*当前属于左子树*/3. then return 0 /*只包含1个叶子结点的左子树,直接能定位到目标叶节点*//*只包含1个叶子结点的右子树,需要记录起始叶子节点的偏移量以定位到目标叶节点*/4. else writeBuffer.Write(GetLeafFp(leavesOffset) - minBlockFp)/*将字节数据流中全部数据转出到内存数据块容器, 返回新增数据块所占空间字节数*/5. return AppendBlock(blocksOut, writeBuffer)6. else if isLeft == true /*当前属于左子树*//*当前根节点的左子树的叶节点文件偏移量leftBlockFp同当前子树最小偏移量minBlockFp一致*/7. then leftBlockFp <- minBlockFp8. else leftBlockFp <- GetLeafFp(leavesOffset) /*计算右子树文件偏移量*//*将左子树文件偏移量与minBlockFp差值写入到写缓冲区*/9. writeBuffer.Write(leftBlockFp - minBlockFp)10. numLeftLeafNodes <- GetNumLeftLeafNodes(numLeaves) /*计算左子树叶节点个数*/11. rightLeafOffset <- leavesOffset + numLeftLeafNodes /*计算右子树叶节点文件偏移量值序号*/12. splitOffset <- rightLeafOffset - 1 /*当前子树根节点空间切分值对应的数组下标*//*当前子树根节点空间切分维度splitDim,和该维度切分值splitValue*/13. (splitDim, splitValue) <- GetSplitDimValues(splitOffset)/*深度优先遍历时上次切分值lastSplitValues与当前splitValue在splitDim的公共字节前缀串的长度prefix*/14. prefix <- CompareDiff(lastSplitValues, splitValue, splitDim)/*lastSplitValues与当前splitValue在splitDim维度上字节数组中第一个不相同的字节值*/15. fistDiffByteDelta <- FirstDiffByte(lastSplitValues, splitValue, splitDim, prefix)/*更新当前splitValue到lastSplitValues中去*/16. UpdateLastSplitValues(lastSplitValues, splitDim, prefix, splitValue)/*拼接一个int类型整型数值code,包括了fistDiffByteDelta、prefix和splitDim 3个值的信息*/17. code <- (fistDiffByteDelta*(1+config.bytesPerDim)+prefix)*config.numDims+splitDim18. writeBuffer.Write(code) /*将code值写入到输出缓冲区*//*将当前切分维度上的切分值prefix之后字节序列写出到输出缓冲区*/19. writeBuffer.Write( GetDiffValue(splitValue, prefix) )/*将输出缓冲区全部字节序列写入到输出block数据块中,并返回当前新增快的字节大小numBytes*/20. numBytes <- AppendBlock(blocksOut, writeBuffer)/*append一个新增空数据块用以占位,存储左子树数据块的字节序号大小值*/21. blockPlaceHolder <- AppendBlock(blocksOut)/*递归调用左子树packindex, 返回左子树packedindex数据的字节大小值leftNumBytes*/22. leftNumBytes <- RecursivePackIndex(lastSplitValues,leftBlockFp,leavesOffset, numLeftLeafOffset,true,blocksOut,writeBuffer)/*把leftNumBytes写入到输出缓冲区,并填充到占位数据块blockPlaceHolder*/writeBuffer.Write(leftNumBytes)leftMetaBytes <- ReplaceBlock(blockPlaceHolder, writeBuffer)/*递归调用右子树packindex, 返回右子树packedindex数据的字节大小值rightNumBytes*/23. rightNumBytes <- RecursivePackIndex(lastSplitValues,leftBlockFp,rightLeafOffset,numLeaves-numLeftLeafOffset,false,blocksOut,writeBuffer)/*返回4部分字节序列长度之和,即为当前子树的packedindex字节序列长度*/24. return numBytes+leftMetaBytes+leftNumBytes+rightNumBytes
RecursivePackIndex算法过程简要分析如下:
1~4行是递归函数退出条件分支,当numLeaves == 1时,如果当前子树是父亲节点的左子树,表明已经定位到目标叶节点,不需要转储了,直接返回0(转储的字节序列大小值);如果是右子树,只需要记录叶节点文件偏移量与minBlockFp的差值然后输出到blocksOut中去即可。
6~9行主要计算当前子树未来的左子树的叶节点文件偏移量leftBlockFp。如果是右子树,还需要把文件偏移量做minBlockFp的差值输出到blocksOut中去。
10~13行主要计算了几个变量的值:numLeftLeafNodes是当前子树的左子树叶子结点个数(根据是完全二叉树的特性)。rightLeafOffset是计算右子树叶节点文件偏移量值序号;splitOffset是当前子树根节点空间切分值对应的数组下标;当前子树根节点空间切分维度splitDim,和该维度切分值splitValue。
第14行计算了深度优先遍历时上次切分值lastSplitValues与当前splitValue在splitDim的公共字节前缀串的长度prefix。很显然prefix <= config.bytesPerDim。config.bytesPerDim 是用户提前设定的每个维度数值所占字节个数,比如double占8个字节,int占4个字节等。
第15行计算lastSplitValues与当前splitValue在splitDim维度上字节数组中第一个不相同的字节值fistDiffByteDelta。
第16行更新lastSplitValues值;第17行拼接一个int类型整型数值code,包括了fistDiffByteDelta、prefix和splitDim 3个值的信息;
18~20行将code值和当前切分维度上的切分值prefix之后字节序列 都写到输出缓冲区,最后转储到blocksOut数据块数组中;
21行在blocksOut中预先占位存储一个空的数据块,用以后期递归packIndex左子树后得到左子树packedIndex字节序列大小后替换改数据块;这个大小主要是用于未来递归夺取左子树数据时知道左子树数据字节序列的长度。
22~23分别递归调用左右子树的PackIndex过程,分别返回packedIndex的字节序列大小值leftNumBytes和 rightNumBytes。
第24行返回4部分字节序列numBytes 、leftMetaBytes 、 leftNumBytes 、rightNumBytes长度之和,即为当前子树的packedindex字节序列长度。
综合RecursivePackIndex算法全过程,不难发现索引数据尽可能压缩空间存储的原则主要表现在如下几点:
code <- (fistDiffByteDelta * (1+config.bytesPerDim) + prefix) * config.numDims+splitDim , 用一个int整形值code代替了fistDiffByteDelta、prefix、splitDim 三个值的存储;读取时可以采取多次除法求商和余数的方式依次计算获得所需的这3个变量值;
以简短的prefix和GetDiffValue(splitValue, prefix) 代替了每个节点上的较长的splitPackedValue值的存储;
如果当前子树是父节点左子树时,都不需要记录leftBlockFp,因为此时该值就等于minBlockFp(这个值是递归函数调用一直传递下来的栈上的临时值);只在当前子树是父节点右子树时,需要记录存储未来左子树叶节点文件偏移量与minBlockFp差值delta。这个delta差值类型虽然也是int64_t类型,但是差值通常比文件指针偏移量值本身小太多,存储时采用VInt方式按需申请存储空间大小,实际中也通常比存储原值所需空间少一些。
在完成RecursivePackIndex()过程将全部未来深度优先遍历BKD树可能用到的索引数据都尽可能压缩地存储到数据块数组blocksOut后,再设计PackIndex() 函数将blocksOut字节数据块数组中的全部数据都依次连续地追加输出到一个连续字节序列数组packed_index中即可用于后续索引序列化。
4.2.3. Meta元数据存储方法
上一节我们PackIndex() 函数压缩封装产生了访问BKD(通常是以Visitor模式的深度优先遍历)树需要的索引数据的连续字节序列packed_index(长度为packed_index_length)。到目前为止连续字节序列packed_index都还是存储在内存中的。接下来本节调用WriteIndex()算法函数一些构建和访问BKD树需要的维度相关的前置配置参数值等存储到外部磁盘文件meta_file(通常文件名后缀是.bkd.meta)中去。meta_file顾名思义是BKD树需要的元数据,其包含内容如下(最开始包含的version等头信息略过不提):
config.numDims - 当前BKD存储的字段的数值数据的维度,是几维的。比如2维;
config.maxPointsInLeafNode - 每个叶子节点允许包含的最大原始数值元素个数(通常设置为512或1024);
config.bytesPerDim - 数值数据每一维的值由多少个字节表达,比如float类型是4字节,short类型是2个字节等;
num_leaves - 当前BKD叶子节点个数;
min_packed_value/ max_packed_value - 当前BKD所包括的全部数值的在各个维度上的最小值/最大值;
point_count - 原始数值数据元素个数
packed_index_length - 索引数据的连续字节序列packed_index的字节长度;
data_start_fp - 另一个存储原始数值数据的data文件(后缀为.bkd.data)中存储当前字段对应的数值数据序列的起始文件偏移量;
packed_index_fp - 另一个存储索引数据的index文件(后缀为.bkd.index)中存储连续字节序列packed_index的起始文件偏移量;
上面就是每个字段对应的bkd树对应的meta存储文件中对应的一段元数据信息。前面的值不难理解,需要注意最后两个值:data_start_fp 和 packed_index_fp都是另外两个文件中数据的文件偏移量值,data_start_fp是存储原始数值数据的data文件(通常文件名后缀为.bkd.data)中存储当前字段对应的数值数据序列的起始文件偏移量。packed_index_fp是存储索引数据的index文件(通常文件名后缀为.bkd.index)中存储连续字节序列packed_index的起始文件偏移量。存储他们是为了查询访问BKD是能找到索引的原始数值数据和索引数据。下面是一段meta文件中对应一棵bkd树的meta信息的结构示意图(.bkd.meta文件):
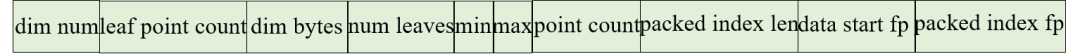
记录完了packed_index_fp 之后,紧接着在index_file(文件名后缀为.bkd.index)中文件指针偏移量packed_index_fp位置开始写入连续字节序列packed_index。下面是写入的数据packed_index结构示意图:

可以看出,packed_index文件结构是一个递归结构,包含3个部分:current pack index是当前子树的几个索引相关信息;left child tree 和right child tree 分别又是一个相同结构的递归左右子树。
4.3. 构建BKD的选择算法与策略
前文3.2.1. 节中 BuildBKD()算法第8行如下:
/*经典选择问题,使得数组A中前leftCount个元素的splitDim维度值都不大于其后的元素*/8. Select(A, splitDim,leftCount)
Select(A, splitDim,leftCount)算法解决的问题是:通过选择和交换,使得数组A中前leftCount个元素的splitDim维度值都不大于其后的元素。这是一个经典的选择问题在多维数值数据集合上的延伸。这个问题怎样操作才能执行最快呢?最快的操作过程时间复杂度是多少呢?
4.3.1. 经典的数据集合上的选择问题
先快速回忆一下经典的选择问题:
假定数组A是一个全部由整数数值组成的无序数据。怎么用最快的算法找出其中第K大的数?最快算法的时间复杂度是多少?
简短分析如下:首先数组A中全是int类型整数,不过是无序的。K数值可能很大,比如A的元素个数是1亿,K是5000万。当然我们知道如果K很小比如k=1或2,我们对数组A执行一次遍历就可以解决问题。但是此处K通常是很大,对应到构建BKD-Tree的场景中,K往往是数组元素个数的1/2左右的大小。解决此问题,最粗暴的做法是一次排序(比如快速排序)O(N * lgN)时间复杂度内数组从小到大排好序了,然后直接取下标为K的元素即可。这种做法的时间复杂度显然是O(N*lgN)。还有没有更快的算法呢?下面给出更快的期望线性时间复杂度的选择算法伪代码:
其中Partition(A, p, r)函数的功能就是以元素A[r]值为大小分界,通过选择和交换,将数组分成前后两部分,前部分中的任意元素值都小于等于原A[r]值,并且也小于等于后部分中任意元素的值。RandomizedPartition(A, p, r)是提前对A[r]值做了个随机化然后再执行Partition分割。这就是快速排序的核心步骤,很简单。
RandomizedSelect(A, p, r, k) 是一个递归函数,它要求返回数组A的子数组A[p…r]中的第k小的数。它的过程不难理解:它借用了快排的思想,先随机地对A[p…r]进行前后快大小分割, 分割的返回位置是q,然后比较q与k的大小以决定继续往前半部分还是后半部分执行递归。<<算法导论>>[4] 中7.4.2节对此伪代码的时间复杂度有详细的理论证明:该选择问题的期望的时间复杂度能达到线性即O(N)(虽然系数可能会大一点)。
RandomizedPartition(A, p, r)1. k <- Random(p, r)2. exchange A[r] <-> A[k]3. return Partition(A, p, r)Partition(A, p, r)1. x <- A[r]2. i <- p-13. for j <- p to r-14. do if A[j] <= x5. then i <- i + 16. exchange A[i] <-> A[j]7. exchange A[i+1] <-> A[r]8. return i+1RandomizedSelect(A, p, r, k)1. if p == r2. then return A[p]3. q <- RandomizedPartition(A, p, r)4. i <- q-p+15. if i == k6. then return A[q]7. elseif k < i8. then return RandomizedSelect(A, p, q-1, k)9. else return RandomizedSelect(A, q+1,r, k-i)
那么,多维度数值数据的选择问题理论上也可以采取上述RandomizedSelect方法,这样的话,BuildBKD过程的整个事件复杂度能达到O(NlgN)。(N是原始数值数据的个数,lgN是树高,BKD树的每一层的内节点的划分大约耗时O(N),于是总的时间复杂度是O(NlgN)。
然而,本文接下来要阐述的算法表明,BKD构建过程中的选择问题解决方案采用了更加巧妙的实现方案,更加适用于构建BKD过程的数据上下文场景特点,为了便于表述,我们称这种选择算法策略为:基于逐字节计数法的选择算法策略。
4.3.2. 基于逐字节计数法的选择算法策略
“基于逐字节计数法的选择算法策略” 充分利用了BKD构建过程的上下文场景特点:
处理的数据元素都是多维数值,而每个数值的维度值一般不会太大,实际中一般限定维度阈值为16或32;
每一维度的数值都可转换位可以从前往后逐个字节比较大小的字节序列。当然,我们知道每个字节计算机用8位表达,取值范围在0~255之间。于是可以利用一个长度为256的数组:int64_t histogram[256] 迅速表达和查询某个字节值的出现的个数;
BKD-Tree 从根节点开始往下的递归构建过程中, 每个内部节点的空间划分时,都自然维护了一个可能不太紧确的、传递下来的当前数据的最小值和最大值:[minBounds, maxBounds]。可以充分利用[minBounds, maxBounds] 预先提前快速计算得到所有数据在划分splitDim上值的公共字节前缀长度的下界。据此下界在计算真实的splitDim上值的公共字节前缀长度效率更高;
据此,“基于逐字节计数法的选择算法策略” 伪代码如下:
BytewiseCounterSelector(points, from, to, partitionPoint,splitDim, baseCommonPrefix, leftPointsOut, rightPointsOut)1. (commonPrefix, histogram) <- FastGetCommonPrefixAndCountDiffByte(points, from, to,baseCommonPrefix, splitDim)2. if commonPrefix == config.bytesPerDim3. then return DirectlyPartition(points, from, to, partitionPoint,splitDim, leftPointsOut, rightPointsOut)4. elseif commonPrefix == config.bytesPerDim-15. then return BaseSelectByByteValue(points, from, to, partitionPoint,commonPrefix, leftPointsOut, rightPointsOut)6. (leftCount, rightCount, deltaCount) <- StatLeftRightDeltaCounts(histogram, partitionPoint)7. AppendLeftRightPoints(leftPointsOut, rightPoints, points, from, to, leftCount, rightCount)8. deltaPoints <- CreateDeltaPoints(points, histogram, deltaCount)9. newPartitionPoint <- partitionPoint - from - leftCount10.BytewiseCounterSelector(deltaPoints, 0, deltaCount, newPartitionPoint,splitDim, ++commonPrefix,leftPointsOut, rightPointsOut)
BytewiseCounterSelector 是一个递归过程,输入参数中partitionPoint是 根据BKD完全二叉树性质确定的左右子树的划分点下标;splitDim是切分维度;baseCommonPrefix 是利用[minBounds, maxBounds] 预先提前快速计算得到所有数据在划分splitDim上值的公共字节前缀长度的下界, 他可以加速真实commonPrefix的计算,因为commPrefix 必然是大于或等于baseCommonPrefix的;leftPointsOut和rightPointsOut 是划分的前后两部分的结果集合。
第1行:快速计算points[from…to] 集合在splitDim上的字节序列公共前缀长度commonPrefix; histogram是一个长度为256的值类型为int64_t的数组,其记录的是points[from…to]集合中所有数据在commonPrefix+1位置字节值的出现次数计数;
第2~5行是递归的退出条件:如果前缀表明所有数值都相同则直接划分两部分即可;否则如果commonPrefix表明递归已经来到最后一个字节位置不同,则直接根据最后一个字节值统计的histogram值,依次将最小的partitionPoint个元素放进leftPointsOut中,其他的放进rightPointsOut中即可;
第6行:根据histogram统计放进左边部分、右边部分和 等于commonPrefix+1位置字节值的元素个数;
第7行:遍历histogram将leftCount个元素放进leftPointsOut, 将rightCount个元素放进rightPointsOut; 第8行将等于commonPrefix+1位置字节值的deltaCount个元素构建新的deltaPoints, 作为下一次递归的输入数组;
第9~10行:确定新的分割点,递归调用BytewiseCounterSelector继续分割。
4.4. BKD合并策略与优化
BKD合并策略本质上就是将多个待合并的BKD-Tree中的数据, 通过特定的能访问到BKD上全部数据的Visitor类读取后先放入数据缓冲区收集。待全部收集完成后, 执行BKD构建过程构建新的BKD-Tree即可。
然而特殊场景下仍然有策略优化空间,即一维数值数据场景下的BKD合并算法。如果要构建BKD的数值都是一维的,那么合并BKD的过程可以采用如下更加高效的优化合并策略:
算法伪代码如下,直接将全部待合并的1维BKD-Tree中的叶子节点数据的leafBlocks数组分别作为单个元素添加到一个特定的优先级队列中。然后不断执行出队列,再入队列的操作,实现按数值从小到大顺序, 依次抽取队列中的全部数值元素到一个额外的新数组中去。完成后的新数组中包括了全部待合并的1维BKD-Tree中的叶子节点数据中的数值元素,且是有序的。然后跳过BuildBKD递归划分空间过程,直接在该数组元素集合上执行PackIndex和WriteIndex等后续过程建立新的BKD-Tree。该优化策略利用了一维数值集合如果是有序的就不再需要额外的空间划分操作的特性,极大地提高了BKD合并的效率。
FastMerge1DBKD(bkdReaders, dataOut)1. q <- CreateQueuePriority()2. for i <- 0 to count(bkdReaders)3. then q.Push(bdkReaders[i]->leafBlocksArr)4. newLeafBlocksArr <- CreateNewLeafBlock()5. while q.Empty() == false6. do e <- q.Pop()7. Append(newLeafBlocksArr, e.GetCurData())8. e.Next()9. q.Push(e)10. dataOut.WriteLeafBlocks(newLeafBlocksArr)
结语
最后对通篇所述做个总结,本文首先对数值数据查询问题的解决方案做了优缺点对比讨论,从而引入BKD-Tree 数据结构的概念。接下来分别对BKD的构建、查询、数据动态更新过程的算法原理作了阐述,使读者能对BKD的主要算法原理有一个宏观的掌握和理解。 最后着重分别详细展开论述了BKD在58搜索落地实践中使用的实现手段与策略技巧,主要包括对数据的压缩存储策略、BKD构建过程中对数值数据集合的选择算法与策略、BKD合并过程的优化策略等。
附录
[1]. Bkd-Tree: A Dynamic Scalable kd-Tree
[2]. https://blog.csdn.net/waltonhuang/article/details/106690961
[3]. <<设计模式:可复用面向对象软件的基础>>
[4]. <<Introduction to Algorithms>>
[5]. https://github.com/apache/lucene
【作者简介】
丁斌,硕士毕业于清华大学软件工程专业,58同城TEG搜索推荐部后端架构师,专注于搜索引擎相关技术,主要负责搜索内核功能开发、搜索引擎系统性能优化等搜索相关的后端架构设计和开发工作。
本文分享自微信公众号 - 58技术(architects_58)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。