
概述
背景
58同城作为中国领先的生活服务平台,业务覆盖招聘、房产、汽车、本地生活服务等领域。每日产出亿级别数据,数据分析师对海量数据多维度展示和数据分析需求强烈。部门内部的可视化基石BI基于用户需求,提供数据自定义看板展示和增强分析能力,支持拖拽式操作和丰富的展示效果,帮助用户灵活搭建数据看板,从不同的角度对数据进行解读和挖掘,对数据进行全面的监控和分析,及时发现异常情况和风险点,提供预警和决策支持。
基石BI平台介绍
不同于传统BI工具,基石BI提供了完整的数据闭环,对数据进行抽取、整理、分析、报表输出等,通过数据对企业决策提供支持和帮助。
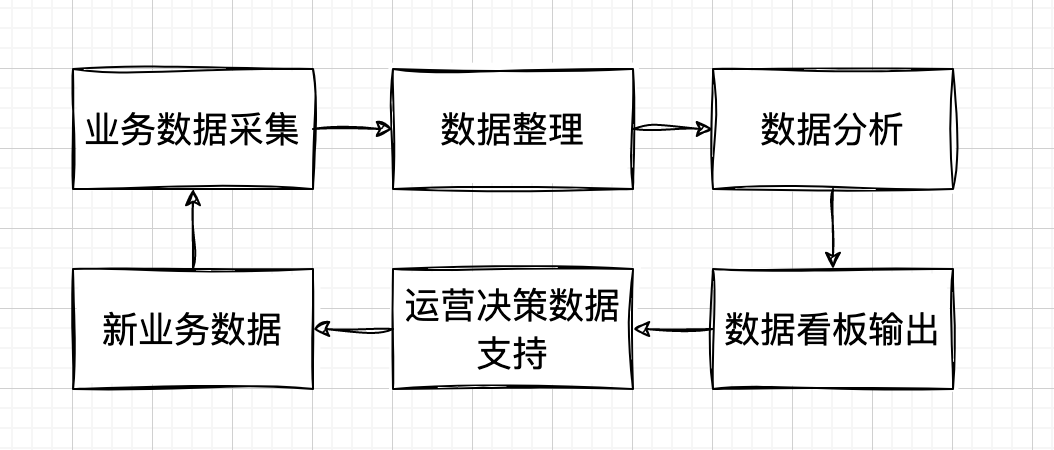
数据连接:用户将要查询的数据表接入到BI中。
数据准备:将数据表进行查询整理,形成数据集,进行数据标注。
数据看板:设置看板对应数据集,拖拽插件进行布局,固化为数据看板。
数据应用:配置应用信息,对外输出数据看板。
增强分析:通过算法模型进行有效的数据分析,查询异动、转化分析数据。
工具化:转化思想,从以往已报表为核心在不同系统开发展示,或是采购其他厂商应用,转化为自研数据工具思维,使功能工具化标准化,提高效率,保证数据一致性和安全性。
平台化:研发BI分析平台,简单快捷的进行可视化看板搭建,对外输出平台化产品,进而实现一处设置,多处使用。
智能化:实现业务智能化,基于算法模型持续产出异动分析、转化分析等智能分析组件,提升平台竞争力,有效为企业决策提供数据支持。
基石BI平台实践
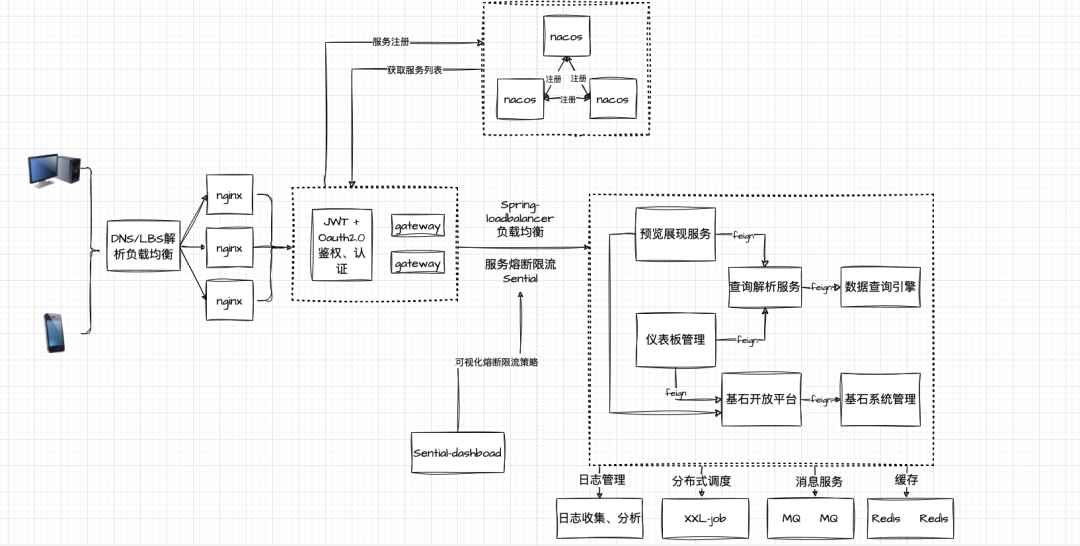
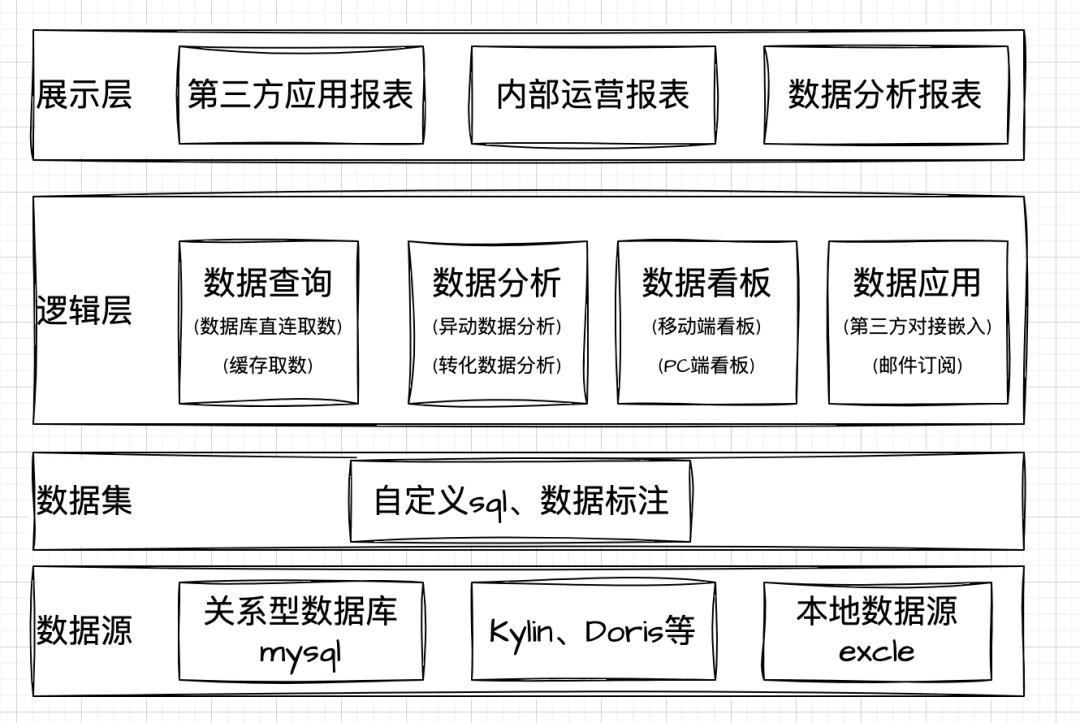
数据接入层:统一数据源,多类型数据源接入BI体系,支持定时同步,数据加工管理,让数据更好的展现。
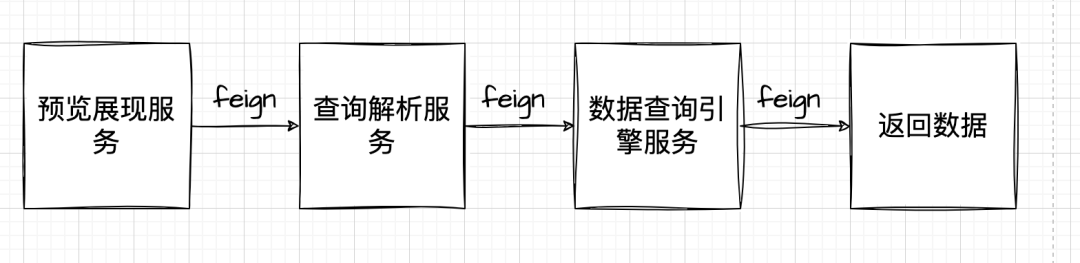
数据服务层:研发数据查询引擎,提供查询解析和结果聚合服务,能够处理数据复杂查询,提升效率。
数据展现层:基于数据查询解析、数据预览服务,搭建用户需求分析看板,设置权限管理,使数据灵活展现。
增强分析层:结合算法模型,更深层挖掘数据潜力,智能诊断,支持维度下钻、指标探查等,为企业运营提供多维度数据支持。
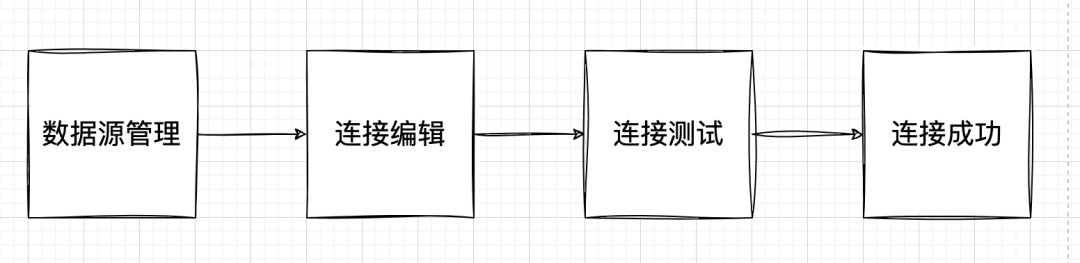
统一数据源,通过权限设置,将数据有效管理。
支持数据源实时校验,数据连接。
页面组件优化:优化组件拖拽显示体验,做到低延迟高流畅;对组件进行二次开发,提升数据展示效果。
交互效果优化:平台前后端调用交互优化,合理构建组件数据查询参数,提高平台解析数据效率;平台操作页面交互优化,让用户使用更便捷,提高操作易用性。
字段条件优化:动态设置字段过滤器,添加多种格式设置,支持日期、数值、字典字段等自定义配置,更加灵活进行数据过滤。
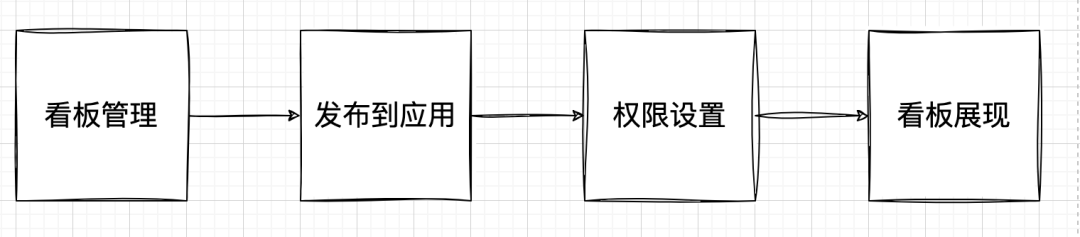
应用信息:对应用进行管理,配置每个应用唯一的授权Key,设置授权模式、授权域、令牌时效信息,安全稳定的与第三方业务应用进行对接。
看板嵌入:将平台看板和应用进行绑定,实现一处配置,多处展示。提供对接服务,高效快捷的使看板嵌入其他业务应用。
数据权限:通过设置 应用-看板-用户 数据权限关系,精确设置到每个组件不同人员查看的行权限,做到千人千面,灵活展示。

邮件推送:平台提供截图服务,对定时发送的数据报告提供邮件推送能力。
多端展现:在PC端配置完成后,能在移动端和H5端自动适配,动态适应看板展示场景。
分析展现:提供下钻维度、智能分析等多种展现功能,提高数据使用率,充分挖掘数据深度。
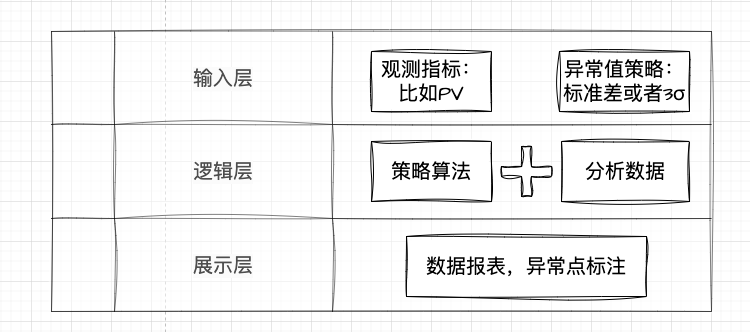
统计方法:基准值指定为均值。均值的计算设定为,以近期(7天、30天)数据进行滚动均值计算。误差的范围选取,以 标准差或者3σ 为建议范围。
阈值方法:基准值指定为环同比的上周期数据,允许分析师自定义波动阈值。根据自定义的阈值,进行数据波动范围可视化展示。
建模方法:基准值通过ARMA时间序列预测&fb-prophet时序预测获取。异常判断将更智能,兼容性更好。
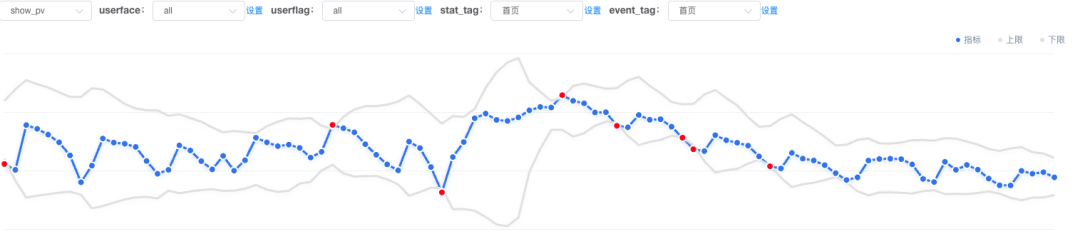
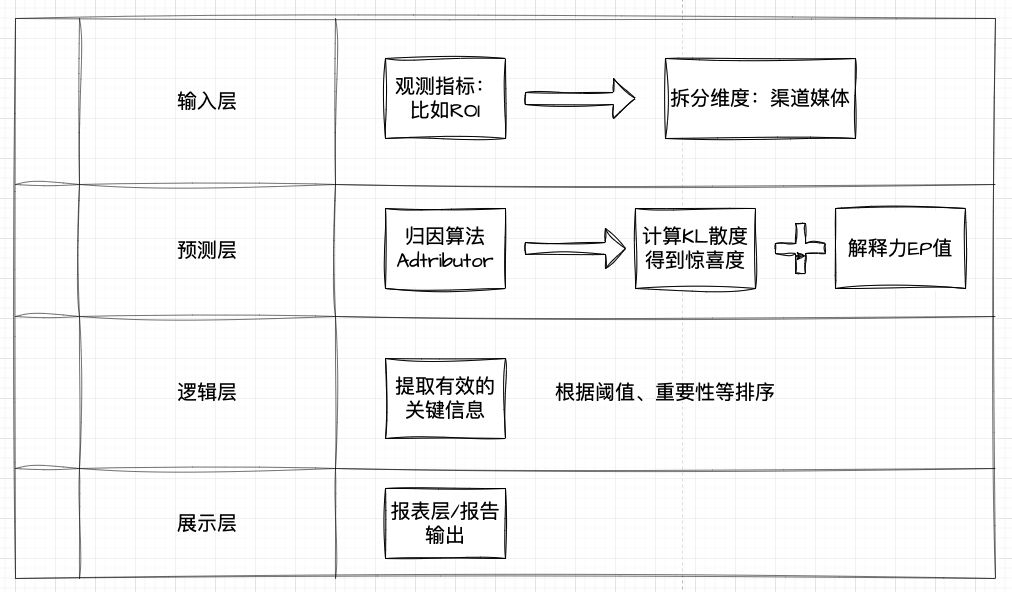
基于Adtributor算法对异动点分析,算法的核心主要是:惊喜度SURPRISE,解释力EP。Adtributor对异常指标的所有维度和元素,根据当前的数值和参考的数值,计算EP值和S值
S值 :
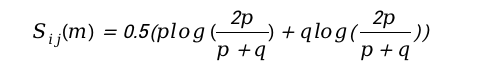 根据惊喜度计算出,针对关键的指标,计算所有维度下的所有元素和参考值的差异,即计算每个元素的Sij(m),然后进行求和得到S值,然后找出哪些维度可能存在异常,根据S值进行降序排序,找出最意外的维度。
根据惊喜度计算出,针对关键的指标,计算所有维度下的所有元素和参考值的差异,即计算每个元素的Sij(m),然后进行求和得到S值,然后找出哪些维度可能存在异常,根据S值进行降序排序,找出最意外的维度。
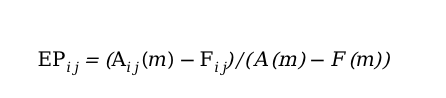 EP值:计算每个维度下每个元素在该分析的指标上的变化总数的占比,EP值是针对单个维度进行衡量每个元素的重要程度。
EP值:计算每个维度下每个元素在该分析的指标上的变化总数的占比,EP值是针对单个维度进行衡量每个元素的重要程度。简单来说,就是针对单个维度进行归因分析,根据S值找出最大的异常维度,根据EP值给出解释说明。
1)漏斗分析是衡量转化效果、进行转化分析的重要工具,是一种常见的流程式的数据分析方法。它能够帮助你清晰地了解转化情况,从多角度剖析对比,定位流失原因,提升转化表现。
2)
a.漏斗分类
【计算规则】: 假设一个漏斗中包含了 A、B、C 3个步骤,A步骤发生的时间可以在B步骤之前,也可以在B的后面。 用户的行为顺序为A、B、C的组合都算成功的漏斗转化。 即使漏斗步骤之间穿插一些其他事件步骤,依然视作该用户完成一次成功的漏斗转化。
【计算规则】: 假设一个漏斗中包含了 A、B、C 3个步骤,A步骤发生的时间必须在B步骤之前,用户的行为顺序必须为A->B->C 。 和无序漏斗一样,漏斗步骤之间穿插一些其他事件步骤,依然视作该用户完成一次成功的漏斗转化。
b.漏斗创建
-
选取漏斗类型 :有序漏斗和无序漏斗,平台默认选择有序。 -
添加漏斗步骤 :漏斗步骤就是漏斗分析的核心部分,步骤间统计数据的对比,就是我们分析步骤间数据的转化和流失的关键指标。 -
确定漏斗的时间区间和周期 : 一般来说,此类数据的数仓表是按照时间分区的。所以选择时间区间,本质就是选择要计算的数据范围。周期是指一个漏斗从第一步流转到最后一步的时间限制,即是用来界定怎样是一个完整的漏斗。
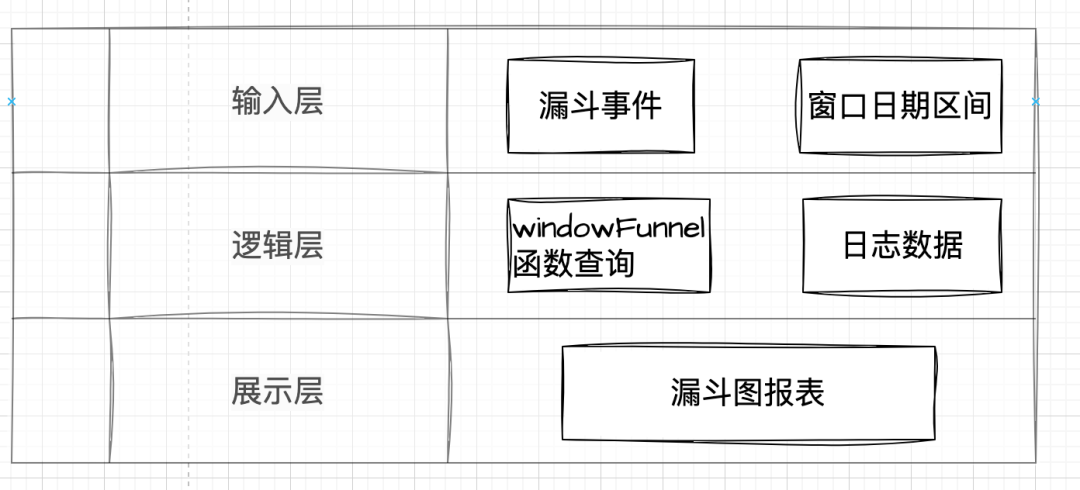
3) 平台漏斗实现

总结
刘乃翔,后端研发工程师,58同城用户价值增长中心-增长数据研发部,主要负责数据平台、增长策略服务等后端架构设计和开发工作。
【部门简介】
58同城用户价值增长中心-增长数据研发部,主要负责用户增长相关数据仓库、数据平台建设,旨在数据赋能业务,为企业运营提供更高效的数据支持。
本文分享自微信公众号 - 58技术(architects_58)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。