
引言
在人工智能的浪潮中,魔乐社区(Modelers)以其海量优质的AI模型库、庞大的数据集资源,以及直观易用的工具,逐渐成为开发者们追捧的热点。其中的应用开发套件openMind[i],为开发者在分享和使用数据集时提供强有力的支持。本期,我们来分享将模型分享到魔乐社区的方式。
数据集贡献流程
上传数据集到Modelers数据集仓库的基本流程如下:
- 注册用户并创建Token
- 创建数据集仓库
- 上传数据集
- 数据集文件规范
Tips: 在魔乐社区分享模型时,需要明确自己是以个人名义还是代表组织进行贡献。本文以个人贡献 为例子,如果您选择作为组织贡献者,建议参考管理组织来进行组织和成员的管理。
- 注册用户并创建Token
- 在魔乐社区分享数据集之前,需要先注册一个社区账号。
- 首先您需要明确自己是以个人名义还是代表组织进行贡献。
- 如果您选择作为个人贡献者,在魔乐社区注册账号后,即可贡献数据集。
- 由于在后续与魔乐社区的交互操作过程中需要使用到Token,请您登录魔乐社区,在个人中心单击访问令牌,新建一个具有Write权限的令牌。
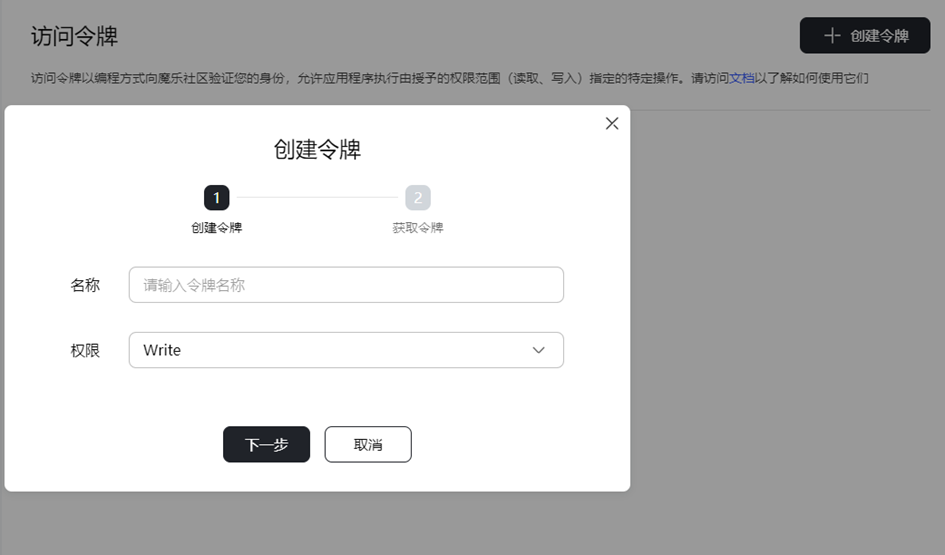
- 此Token仅在创建时展示,请妥善记录保存。
- Read:此Token权限只支持下载。
- Write:此Token权限支持上传和下载。
- 创建数据集仓库
- 登录魔乐社区,在主页右上角找到"用户头像"并在下拉框中找到并单击创建数据集按钮,如下图所示。
- 填写仓库信息后,单击创建按钮,即可创建一个数据仓库。

数据集仓库创建完成后,会自动生成一个数据集卡片,数据集卡片是一个包含数据集信息的README.md文件。为了充分展示您的数据集能力、约束等信息,您可以在页面上直接编辑README.md文件。
- 上传数据集
3.1 安装Git LFS
执行以下命令安装git lfs。安装只需执行一次即可,无需在每个本地仓库都执行。
git lfs install
3.2 追踪大型文件
在本地Git仓库中追踪大型文件(100MB以上)。根据实际需要,追踪相应文件,可以是某一类型,也可以是具体的文件名。示例如下:
git lfs track "*.7z" "*.bin" "*.bz2" "*.ckpt" "*.h5" "*.lfs.*" "*.mlmodel" "*.model"\
"*.npy" "*.npz" "*.onnx" "*.pb" "*.pickle" "*.pkl" "*.pt" "*.pth" "*.rar" "*.safetensors"\
"saved_model/**/*" "*.tar.*" "*.tar" "*.tgz" "*.zip" "*tfevents*" "*.gz"
也可以追踪特定大型文件,示例如下:
git lfs track "big_file.bin"
3.3 使用Git上传
在本地仓库中,将数据集文件添加到Git跟踪中,然后使用Git命令上传。
git add your-model-file
git commit -m 'commit message'
git push
3.4 Git上传账号密码
git上传时需要输入账号与密码,示例如下:
Username for 'https://modelers.cn': 魔乐社区账号名
Password for 'https://modelers.cn': 权限为Write的token
- 使用openMind Hub Client上传数据集
使用openMind Hub Client[ii]管理数据集,包括创建数据集和上传数据集到魔乐社区。
from openmind_hub import upload_folder
upload_folder(
token="xxx",
folder_path="/path/to/local/dataset",
repo_id="username/my-dataset",
)
token:对目标仓库具有可写权限的访问令牌,必选。folder_path: 要上传的本地文件夹的路径,必选。repo_id:目标仓库,必选。
如果您想对要上传的文件类型进行过滤,可以使用allow_patterns和ignore_patterns参数。
-
allow_patterns:只允许某类文件上传。如allow_patterns=["*.bin", "*.txt"]表示只上传以.bin和.txt结尾的文件。 -
ignore_patterns:忽略某类文件的上传。如ignore_patterns=["*.log"]表示忽略所有日志文件。
- 数据集文件规范
数据集上传过程目前只对License有强校验。License相关信息在README.md里的metadata更新,目前的规范如下:
-
不允许License为空
-
不允许License为[]
-
支持单一协议
license: mit
-
支持多协议, 以下为2种支持的写法
#格式1 license: [mit, gfdl]
#格式2 license:
- mit
- gfdl
结语
作为AI生态社区的新星,魔乐社区致力于为开发者打造一个开放、共享的人工智能生态社区。本次我们主要分享在魔乐社区上传数据集的经验,希望能够助力开发者们更高效地利用社区资源,促进知识交流和技术进步。
通过上传高质量的数据集,开发者不仅可以为自己的项目提供支持,还能与其他社区成员共享数据,从而在机器学习、深度学习等领域推动模型训练和算法研究的发展。我们也提供了一系列的工具和指导文档,帮助开发者们更好地管理和发布数据集,共同构建一个健康、活跃的AI技术交流平台。

[i] openMind,一款应用使能开发套件,为各大模型社区提供支持,提供海量模型/数据托管能力、在线推理体验服务,同时具备模型训练、微调、评估、推理等全流程开发能力。开发者通过简单的API接口即可实现微调、推理等任务,极大缩短开发周期,助力AI技术的创新发展。目前,openMind已支持欢迎在魔乐等AI生态社区,欢迎了解。
[ii] openMind Hub Client介绍:https://modelers.cn/docs/zh/openmind-hub-client/overview.html
微软开源基于 Rust 的 OpenHCL 字节跳动商业化团队模型训练被“投毒”,内部人士称未影响豆包大模型 华为正式发布原生鸿蒙系统 OpenJDK 新提案:将 JDK 大小减少约 25% Node.js 23 正式发布,不再支持 32 位 Windows 系统 Linux 大规模移除疑似俄开发者,开源药丸? QUIC 在高速网络下不够快 RustDesk 远程桌面 Web 客户端 V2 预览 前端开发框架 Svelte 5 发布,历史上最重要的版本 开源日报 | 北大实习生攻击字节AI训练集群;Bitwarden进一步脱离开源;新一代MoE架构;给手机装Linux;英伟达真正的护城河是什么?