爬取的网址:http://jwxt.gdufe.edu.cn/jsxsd/
最近在研究python爬虫,就拿了自己学校的一个相当于教务系统的东西?来模拟登陆了一下。网上查了一下资料,
教务系统好像通常都是爬虫新手&学生的挚爱,因为登陆简单不用验证码等等等。。
其实这个还是挺简单的,但是我在分析HTTP的请求和响应的时候中了一个坑,所以搞了一天。。真是弱,好烦
先说说用到的python库是urllib.request和http.cookiejar。模拟登陆需要使用cookie去保持登陆的状态,若不懂就自行百度。
这里主要想聊一聊如何抓包和分析HTTP请求和响应的消息头。
先看看这个系统的登陆界面:

我就直接登陆然后用360自带的功能进行抓包,看看在登陆的时候模拟器和服务器之间干了些什么。登陆前按F12就可以了:
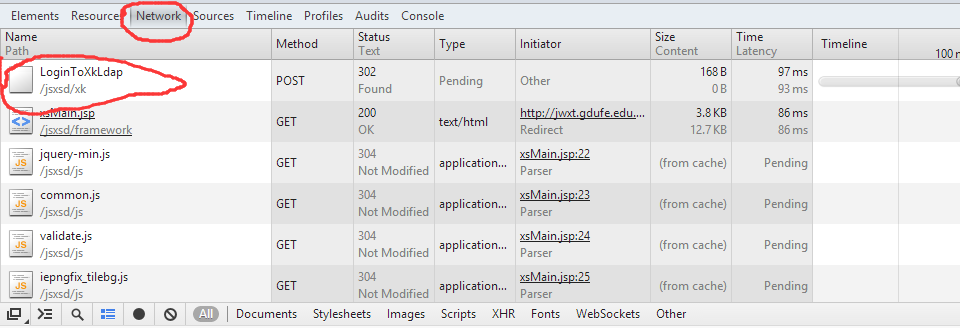
我们关注Network,里面显示的是抓到的包。看名字第一个就是登陆相关的,点进去看看吧:
这里就是登陆的时候发送和收到的请求和响应消息,有了这些信息,我们就可以模拟浏览器去登陆系统了。
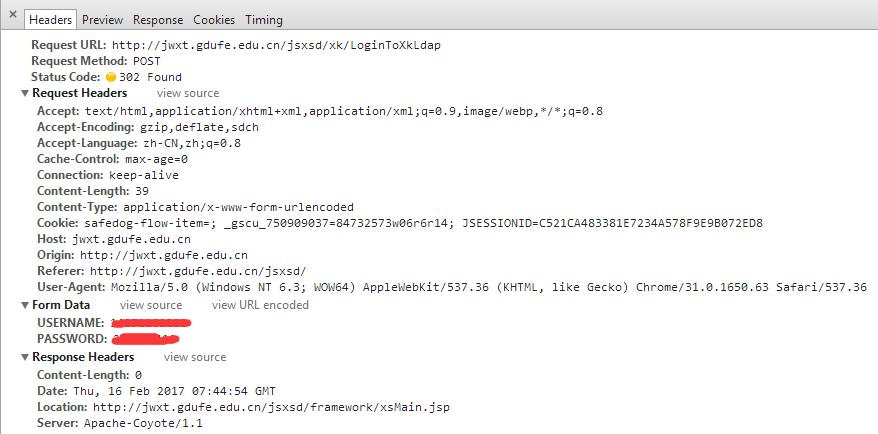
Request Headers:
请求的header在这里不重要,这个系统似乎也没有任何手段去阻拦程序去访问,有些网站就会根据User-Agent去识别你是否浏览器访问。
python就可以根据这个参数伪装成浏览器去访问了。
Form Data:
这里就是登陆的时候需要提交的表单数据,这里只需要提交账号和密码
Response Headers:
这里是服务器响应的消息,Location是重定向的地址。表单提交后登陆成功就会转到这个地址。
这里说说我踩到的坑,看看第一行的Request URL是表单提交请求的URL,也就是说,表单应该提交到这个网址,这里才是程序登陆的入口!!
而不是我一开始给的网址:http://jwxt.gdufe.edu.cn/jsxsd/;考虑一下程序的行为:把消息头表单数据提交到这个网址,它并没有表单处理的功能,
当然就登陆失败了,虽然它还是会返回一个cookie给你,但是使用这个cookie并不能登陆。
下面是代码:
from http import cookiejar
from urllib import request
from urllib import parse
#这个是提交表单的url
url = 'http://jwxt.gdufe.edu.cn/jsxsd/xk/LoginToXkLdap'
file = 'C:/Users/Administrator/Desktop/cookie.txt'
post_data = parse.urlencode({
'USERNAME':'14251102221',
'PASSWORD':'291608411'
}).encode(encoding='utf8')
header = {
'Referer':'http://jwxt.gdufe.edu.cn/jsxsd/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36'
}
req = request.Request(url,post_data,header)
#使用cookie创建自己的opener
cookie = cookiejar.CookieJar()
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
f = opener.open(req)
#登陆成功后保存了cookie,然后就可以访问登陆后的其他url了,这个是课程表的url
gradeURL = 'http://jwxt.gdufe.edu.cn/jsxsd/xskb/xskb_list.do'
result = opener.open(gradeURL)
f = open('C:/Users/Administrator/Desktop/1.html','wb')
f.write(result.read())