在这篇博文中,我们将探讨怎样通过可微分编程技术,实现深度学习中最常用的多层感知器(MLP)模型。我们在这里使用TensorFlow Eager Execution API,并使用多层感知器模型来进行MNIST手写数字识别任务。如果我们单纯想尝试一下自动微分和可微分编程,以及如何用TensorFlow来调用这些技术,我们可以使用TensorFlow内置类来做这个工作,但是这样大家就无从了解实现的细节了,对于深刻掌握可微分编程来说是不利的。因此我们在这篇博文,会尝试从头开始,利用自动微分技术,实现一个简单的多层感知器模型。
我们可以构造一个最简的多层感知器(MLP)模型,来做MNIST手写数字识别工作,如下所示:
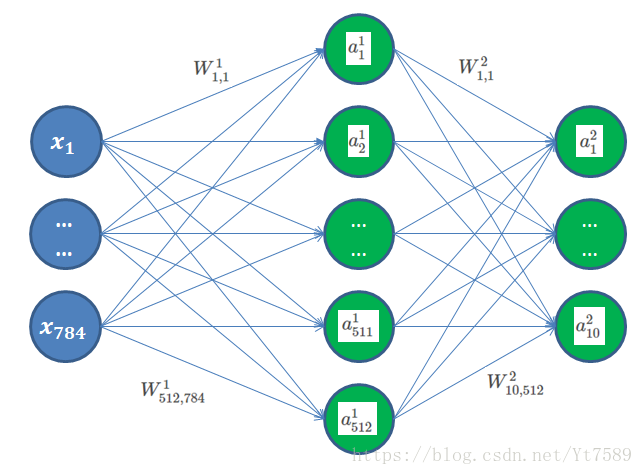
因为MNIST图片为
28×28
的黑白图片,所以输入向量为
x inR784
,这里的
n=784
,即共有784维。对第i个样本,我们用
x(i)
来表示,在本例中,为了讨论问题方便,我们省略的上标仅用
x
表示,但是大家要注意这代表的是某一个样本。对于图中的每个像素点,我们将28行串接起来,组成一个784个的长数列,用下标表示某个像素点的取值,例如第2行第5列的下标为
28×2+5=61
,可以用
x61
来表示。
输入层与第1层采用全连接方式,第1层第i个节点的输入值我们用
z1i
,其为输入层所有神经元的输出值,与该神经元与第1层第i个神经元连接权值相乘再相加的结果,我们假设输入层第j个神经元指向第1层第i个神经元的连接权值用
W1i,j
表示,上标代表为第1层,下标第一个代表是第1层第i个神经元,第二个代表是输入层第j个神经元,我们可以得出第1层第i个神经元的输入值公式:
z1i=W1i,1x1+W1i,2x2+...+W1i,jxj+...+W1i,784x784+b1i(1)
或者简写为:
z1i=∑j=1784W1i,jxj+b1i(2)
我们通常将所有第1层神经元的输入值串起来形成一个向量,如下所示:
z1=⎡⎣⎢⎢⎢⎢z11z12...z1512⎤⎦⎥⎥⎥⎥
我们将第1层神经元的偏置值
b1i
与串在一起形成一个向量,如下所示:
b1=⎡⎣⎢⎢⎢⎢b11b12...b1512⎤⎦⎥⎥⎥⎥
我们将输入层与第1层的连接权值表示为矩阵形式,如下所示:
W1=⎡⎣⎢⎢⎢⎢⎢W11,1W12,1...W1512,1W11,2W12,2...W1512,2............W11,784W12,784...W1512,784⎤⎦⎥⎥⎥⎥⎥
输入信号也表示为向量形式:
x=⎡⎣⎢⎢⎢x1x2...x584⎤⎦⎥⎥⎥(3)
则第1层神经元的输入信号可以表示矩阵向量的运算,如下所示:
z1=W1⋅x+b1(e000001)
我们假设第1层第i个神经元的激活函数为ReLU函数,则其输出为:
a1i=ReLU(z1i)(4)
我们同样将第1层所有神经元的输出串在一起形成一个向量,如下所示:
a1=ReLU(z1)(5)
将式(
e000001
)代入得到:
a1=ReLU(z1)=ReLU(W1⋅x+b1)(e000002)
以上我们讨论的是输入导到第1层,我们可以很容易的将其推广为从第
l−1
到第
l
层:
al=ReLU(zl)=ReLU(Wl⋅al−1+bl)(e000003)
我们用
Nl−1
代表第
l−1
层神经元数量,用
Nl
表示第
l
层神经元数量,则第
l−1
层输出信号
al−1∈RNl−1
,第
l−1
层到第
l
层连接权值矩阵
Wl∈RNl×Nl−1
,第
l
层偏置值
bl∈RNl
,第
l
层输入信息
zl∈RNl
,第
l
层的输出值
al∈RNl
。
前向传播各层计算公式一样,直到我们的输出层(这里是第2层),我们有10个神经元,分别代表取0~9这10个数字的概率,激活函数采用Softmax函数,取概率最大的那个作为整个网络的分类结果。
神经网络的训练可以采用BP算法,这里有很多成熟的算法库可用。但是我们在这里要采用计算的方式来讲解,同时我们在讲解了计算图的基本原理之后,我们会用TensorFlow Eager Execution API,采用可微分编程方式,实现这一经典算法。
采用计算图方式的话,我们需要引入一种网络的另一种表示方式,如图所示:
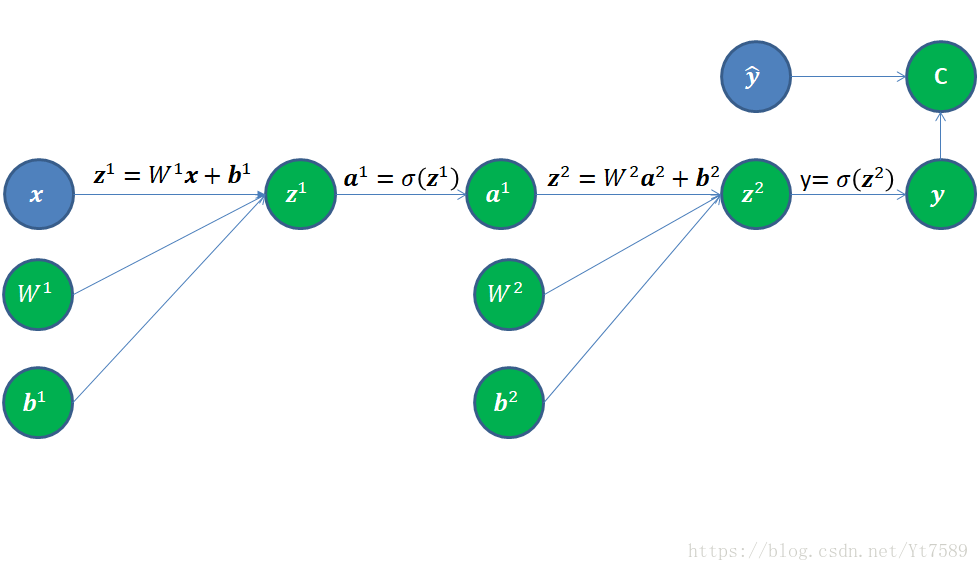
我们将输入信号向量
x
、输入层到第1层的连接权值矩阵
W1
、第1层神经元偏置值向量
b1
放在图的最左侧,将这三个值进行如下运算:
z1=W1x+b1(6)
经过计算得到节点
z1
,我们再经过激活函数得到第1层神经元输出信号
a1=ReLU(z1)
,得到
a1
节点。
我们将第1层输出信号
a1
、第1层到第2层连接权值矩阵
W2
、第2层神经元偏置值向量
b2
放在一起,经过如下运算:
z2=W2a1+b2(7)
第2层也就是输出层的激活函数为Softmax函数:
yi=a2i=ez2i∑N2j=1ez2j(8)
其向量形式表示为:
yi=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢ez21∑N2j=1ez2jez22∑N2j=1ez2j...ez2N2∑N2j=1ez2j⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥(9)
而我们的希望的结果表示为:
y^i=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢0010...0⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥(10)
如上所示,其用one-hot向量形式表示,即只有正确的数字处为1,其余位置为0,例如本例中,就代表其识别结果应该为2。
向量运算的微分
我们先来定义向量微分,假设有向量
y∈Rm
和向量
x∈Rn
,微分
∂y∂x
定义为:
∂y∂x=⎡⎣⎢⎢⎢⎢⎢⎢⎢∂y1∂x1∂y2∂x1...∂ym∂x1∂y1∂x2∂y2∂x2...∂ym∂x2............∂y1∂xn∂y2∂xn...∂ym∂xn⎤⎦⎥⎥⎥⎥⎥⎥⎥(11)
这就是Jacobian矩阵
j∈Rm×n
。代价函数求导
我们首先从计算图最右侧开始反向求导,如图所示:
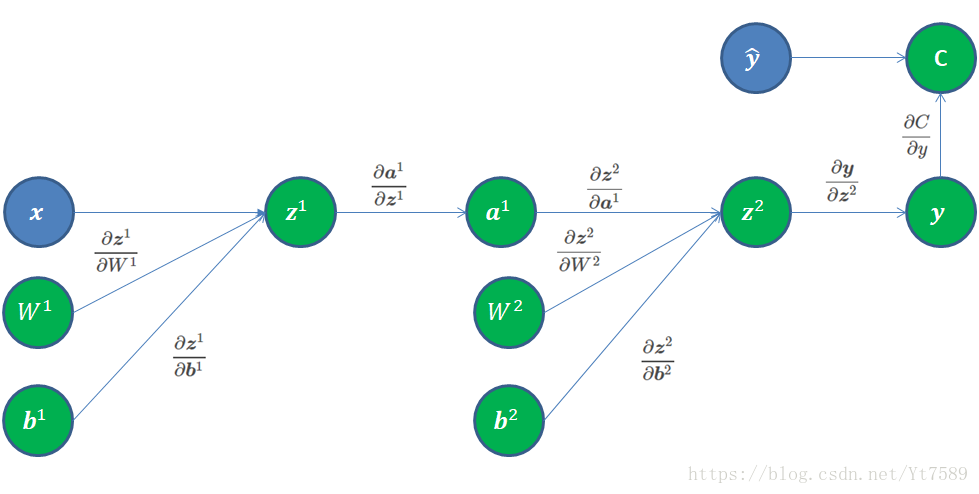
我们首先处理损失函数,这里我们假设不考虑添加调整项的情况,我们的代价函数取交叉熵(cross entropy)函数,根据交叉熵定义:
H(p,q)=Ep(−logq)=H(p)+KL(p∥q)(12)
对离散值情况,交叉熵(cross entropy)可以表示为:
H(p,q)=−∑k=1Kp(k)logq(k)(13)
在这里我们设正确值
y^
的分布为p,而计算值
y=a2
的分布为q,假设共有
K=10
个类别,并且假设第
r
维为正确数字,则代价函数的值为:
C=H(p,q)=−∑k=1Kp(k)logq(k)=−(0∗logy1+0∗logy2+...+1∗logyr+...+0∗logy10)=−logyr(14)
我们可以将代价函数值视为
R1
的向量,我们对
y
求偏导,根据Jacobian矩阵定义,结果为
R1×N2=R1×10
的1行10列的矩阵。结果如下所示:
∂C∂y=[00...−1yr...0](15)
其只有正确数字对应的第r维不为0,其余均为零。
接下来我们来求:
∂y∂z2
,因为
y
和$\boldsymbol{a}^2均为向量,可以直接使用Jacobian矩阵定义得:
∂y∂z2=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢∂y1∂z21∂y2∂z21...∂yN2∂z21∂y1∂z22∂y2∂z22...∂yN2∂z22............∂y1∂z2N2∂y2∂z2N2...∂yN2∂z2N2⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥(16)
式中
N2=10
为第2层即输出层神经元个数。由此可见
∂y∂z2∈RN2×N2(R10×10)
的方阵。
如果我们输出层采用
σ
函数,那么第i个神经元的输出只与其输入有关,与其他神经元无关,因此该矩阵就变为一个对角阵,如下所示:
∂y∂z2=⎡⎣⎢⎢⎢⎢σ′(z21)0...00σ′(z22)...0............00...σ′(z210)⎤⎦⎥⎥⎥⎥(17)
但是我们在这里使用的是Softmax激活函数,每个输出与该层所有神经元的输入均有关,所以其不是对角阵。
接下来我们计算
∂z2∂a1
,根据Jacobian矩阵定义得:
∂z2∂a1=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∂z21∂a11∂z22∂a11...∂z2N2∂a11∂z21∂a12∂z22∂a12...∂z2N2∂a12............∂z21∂a1N1∂z22∂a1N1...∂z2N2∂a1N1⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥(e000004)
我们知道:
z2i=W2i,1a11+W2i,2a12+...+W2i,ja1j+...+W2i,N1a1N1
则其对第1层第j个神经元输出信号求导:
∂z2i∂a1j=W2i,j
所以式(e000004)的最终结果为:
∂z2∂a1=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∂z21∂a11∂z22∂a11...∂z2N2∂a11∂z21∂a12∂z22∂a12...∂z2N2∂a12............∂z21∂a1N1∂z22∂a1N1...∂z2N2∂a1N1⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢W21,1W22,1...W2N2,1W21,2W22,2...W2N2,2............W21,N1W22,N1...W2N2,N1⎤⎦⎥⎥⎥⎥⎥=W2(e000004)
这个结果与我们直接对
z2=W2a1+b2
对
a1
求导得
W2
一致。
接下来我们要求的
∂z2∂W2
,这里是向量对矩阵求偏导,结果将是一个张量(Tensor)。
我们可以将连接权值矩阵
W2
视为由列向量组成:
W2=[w1w2...wN1](18)
其中第
k
个列向量
wk
为:
wk=⎡⎣⎢⎢⎢⎢⎢W21,kW22,k...W2N2,k⎤⎦⎥⎥⎥⎥⎥(19)
这时
∂z2∂W2
就可以转化为对一系列连接权值矩阵组成的列向量求导,就变为列向量求导,如下所示:
∂z2∂W2=[∂z2∂w1∂z2∂w2...∂z2∂wN1](20)
式中的每一项均为向量对向量的导数,其为Jacobian矩阵,因为
z2∈RN2
,且
wk∈RN2
,根据Jacobian矩阵定义,
∂z2∂wk∈RN2×N2
的矩阵,如下所示:
∂z2∂wk=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∂z21∂wk1∂z22∂wk1...∂z2N2∂wk1∂z21∂wk2∂z22∂wk2...∂z2N2∂wk2............∂z21∂wkk∂z22∂wkk...∂z2N2∂wkk............∂z21∂wkN2∂z22∂wkN2...∂z2N2∂wkN2⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥(21)
由此可知其为
RN2×N2
的方阵,对其中第
i
行第
j
列元素:
∂z2i∂wkj=∂z2i∂W2j,k(e000005)
在式(e000005)中,如果
i≠j
,此时连接权值不指向第
i
个神经元,因此值为0。当
i=j
时,
W2i,k
是与第1层的第
k
个神经元的输出
a1k
相乘,因此其导数为
a1k
,当
i=j
时对应的是式(e000005)的对角线,因此其为对角阵,而且其值均为
a1k
,如下所示:
⎡⎣⎢⎢⎢⎢a1k0...00a1k...0............00...a1k⎤⎦⎥⎥⎥⎥(22)
余下部分的偏导求法和上面的方法相同,我们在这里就不再一一列举了。读者可以自行补齐。
到此我们基本把多层感知器模型的计算图讲完了,下一步就是利用TensorFlow Eager Execution API来实现这个模型,我们将在下一篇博文中进行介绍。