周志华《机器学习》笔记:2、模型评估与选择
标签(空格分隔): 机器学习 周志华
因为在学习周志华的西瓜书时,对书上很多东西不甚理解,在经过多方查阅资料后,弄通了一点东西。为了防止以后忘记,把它记录下来,作为学习笔记。
同时,我认为学习笔记,不是对书中内容的概括,而是对其中知识点的理解,是书中内容的扩充。因此,此处只记录我对每章阅读时一时间不懂内容的理解。
本章主要讲了《机器学习》中模型的评估方法,以及选择。
P-R曲线
以二分类问题为例进行说明。分类结果的混淆矩阵如下图所示。
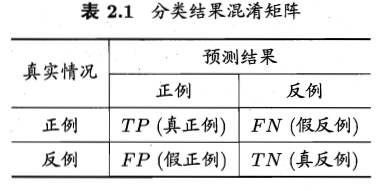
假设,现在我们用某一算法
h
对样本进行二分类(划分为正例、反例)。由于算法可能与理想方法存在误差,因此在划分结果中,划分为正例的那部分样本中,可能存在正例,也可能存在反例。同理,在划分为反例的那部分样本中,也可能存在这样的误差。因此,我们需要定义一些指标来衡量我们的算法的好坏程度。下面是两个是目前常用的指标——查准率、查全率。
查准率
P
定义为:
P=TPTP+FP
查全率
R
定义为:
R=TPTP+FN
P-R曲线,即基于这两个指标对算法进行直观衡量。
下面根据我的理解,谈一下P-R曲线是如何做出来的。
假设,我们的数据集包含n个样本
x1,x2,…,xn
,那么经过算法
h
处理,得到一组数值
h(x1),h(x2),…,h(xn)
。我们将这组值从高到低进行排列,假设排列的顺序就是
h(x1),h(x2),…,h(xn)
,其中
h(xn)
是算法认为最有可能为正例的样本,排在后面的
h(x1)
,是算法认为最不可能为正例的样本。有了排序结果,我们还要定义一个阈值
p0
。在二分类中,高于阈值
p0
被我们认为是正例,低于阈值
p0
的,认为是反例。
假设,我们将阈值设得很高,开始时,只认为
xn
是正例(此时只有
h(xn)>p0
),其他结果都是反例。那么我们可以计算出一组P、R数值。之后,通过不断降低阈值
p0
的设定,使得被算法判定为正例的样本,从只有{
xn
},到{
xn,xn−1
},{
xn,xn−1,xn−2
},直至包含所有样本{
xn,xn−1,…,x1
}。此时可以得到n组不同的P、R值。将查准率P作为横轴,查全率R作为纵轴,在坐标轴上绘制出这些P-R数组,再连成曲线,即可得到相应的P-R曲线图。
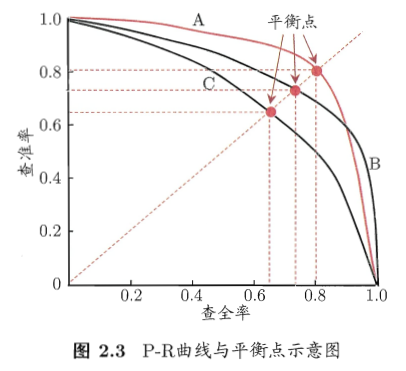
从图上所示,不同的算法,对应着不同的P-R曲线。如图所示,我们有A,B,C三条曲线。通常,我们认为如果一条曲线甲,能够被另一条曲线乙包住,则认为乙的性能优于甲。因为如果我们的算法
h
是最接近真实算法的条件下,在不断调整阈值
p0
过程中,在某一个
p∗0
之前,所有判定为正例的样本的实际标签也是正例(每个样本有两个标签,一个是真实的,一个是算法判定的),因此查准率P应该保持在100%,也就是1.0的位置,这种算法下的
h
,必然能够包括住其他所有曲线。在
p∗0
之后,也可以看出,理想曲线必然包含其他算法
hi
的P-R曲线。
在图2.3上,就是曲线B的性能要高于曲线C。但是A和B发生了交叉,所以不能判断出A、B之间哪个算法更优。
比较两个分类器好坏时,显然是查得又准又全的比较好,也就是的PR曲线越往坐标(1,1)的位置靠近越好。因此,在图上标记了“平衡点(Break-Even Point,简称BEP)”。它是“查准率=查全率”时的取值,同时也是我们衡量算法优劣的一个参考。
ROC
主要对应书中P33~35部分内容。这里对ROC,和他的“损失”(
lrank
)进行了补充解释。
ROC的具体画法,可以参阅下面的参考3(分类器性能指标之ROC曲线、AUC值)
还是以上面的表2.1来谈,ROC和PR曲线类似,都是对算法性能的一种评估。
ROC曲线以真正例率和假正例率为Y、X轴。其定义如下
真正例率:
TPR=TPTP+FN
假正例率:
FPR=FPTN+FP
从表2.1可以看到,真正例率和假正例率的分母,就是真实的正例个数,和反例个数。对一组数据
D
来说,假设其中有
m+
个正例,
m−
个反例,那么ROC图上,真正例率轴上的单位刻度应该是
1m+
,假正例率轴上的单位刻度是
1m−
。(这里对应的是离散的情况,也就是图2.4 b锯齿状图的情况)
在某一算法
h
作用下,假设当前阈值
p0
下的TPR,FPR数值对在图上坐标是
(x,y)
,改变阈值后,后面一个样本被判为正例(参考ROC曲线图做法),当这个是真正例时,TP=TP+1,但是分母没有变(因为分母是真实的正例数目,真正例增加一个,必然意味着假反例减少一个),所以
TPR=TP+1TP+1+FN−1=TPTP+FN+1TP+FN=TPTP+FN+1m+
也就是书上说的,此时的数值对为
(x,y+1m+)
。同理可以得到新增的预测正例是假正例的情况。
因此,
ROC曲线是一个单调曲线。
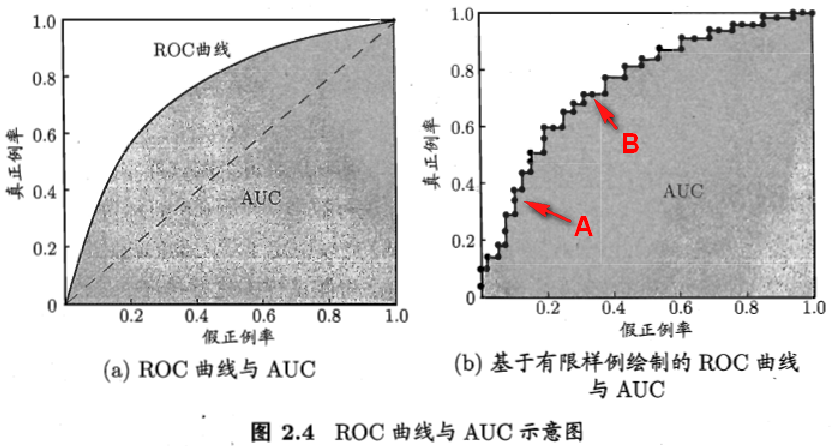
从图上可以看出来,有限样本下ROC曲线从左往右,每次新增的数据点只有两种情况,或者向右一格,或者向上一格。
因此,AUC的面积可以这样算:
AUC=12∑i=1m−1(xi+1−xi)(yi+yi+1)
ROC曲线图的对角线
在ROC曲线上的对角线上的点,其真正例率=假正例率。这个结果,可以认为是随机猜测的结果。也就是随机猜测时,一个样例有一半的可能是被认为是“真”,一半的可能被认为是“反”。一个好的预测方法,起ROC曲线应该包含这条对角线,即优于随机猜测结果。
疑问
在图2.4 b 中A点处,可以看成
xi+1−xi=0
,这部分不参加计算,只有B点处参加计算。但是B点的情况是
yi=yi+1
。因此感觉如果把公式写成
AUC=∑i=1m−1(xi+1−xi)yi
会不会更简洁一些???
参照下面公式2.21的解释,这部分
12(yi+yi+1)
应该是用来平衡两个样本预测结果相同的情形。
关于损失公式的理解
指示函数,这里用
I(X)
来表示
在ROC图上,关于损失的定义是书中的公式2.21:
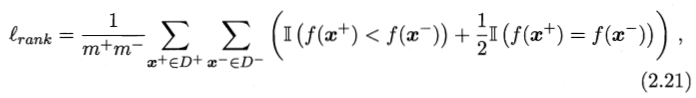
x+,x−
分别表示样本中的正例和反例(这个是真实的正例与反例)
$
f(x^+)
代价曲线
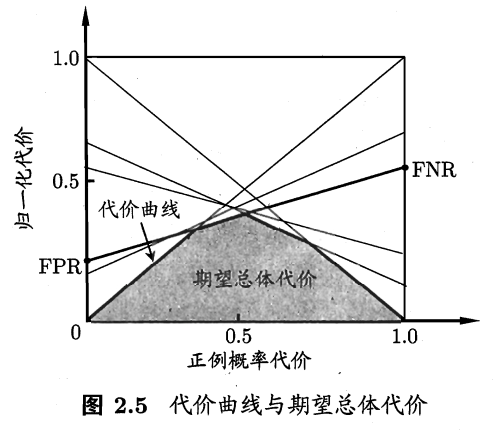
代价曲线的横轴是正例概率代价,其定义式:
P(+)cost=p×cost01p×cost01+(1−p)×cost10
假设样本集
D
的样本数目为
N
,将正例概率代价上下同时乘以
N
,则得到
P(+)cost=N×p×cost01N×p×cost01+N×(1−p)×cost10
。
其中分母
N×p×cost01+N×(1−p)×cost10
表示样本集中所有正例都被认为是反例的代价与所有反例都被划分成正例的代价之和,也就是样本划分的最大代价。分子表示所有正例都被认为是反例的代价。这个比率,就是正例划分错误的代价在最大总体代价下的比例。当
P(+)cost=0
时,即
p=0
,说明样本中没有正例。当
P(+)cost=1
时,即
p=1
,说明样本中没有反例。
图中归一化代价的定义:
costnorm=FNR×p×cost01+FPR×(1−p)×cost10p×cost01+(1−p)×cost10
将之也上下同时乘以样本数量
N
,则
N×FNR×p×cost01=N×p×FNR×cost01
,
N×p
是正样例的数目,
FNR
是正样例中被误判为反例的数目。所以分子的第一部分是在某一阈值
p
下,将正例判别为反例的代价。同理第二部分可以看成是在阈值
p
下,将反例判为正例的代价。因此,分子部分的和表示算法
f
在某一阈值
p
下的总代价。
当
p=0
时,P(+)cost=0,
costnorm=FPR
;同理,当
p=1
时,P(+)cost=1,
costnorm=FNR
;
看到这里,感觉样本集
D
中,正例比例
p
对预测算法
f
的好坏并没有太大影响。
FPR与FNR的连线上的任一点,其横坐标对应某一正概率代价
P(+)cost∗
,纵坐标就是在该正概率代价、FPR、FNR下的预期损失。
图中的阴影部分,也就是期望总体代价那一部分,可以说是在任一正例概率
p
下,无论FPR和FNR如何变化,算法都必须付出的代价。
期望泛化误差=偏差+方差+噪声
这里只对公式的推导进行下梳理,定义参照书上。

式(3)到式(4)最后一项的变化
2ED[(f(x;D)−f¯(x))(f¯(x)−yD)]=2ED[(f(x;D)−f¯(x))ED[(f¯(x)−yD)]
是由于噪声与
f
不相关(书上的话是“噪声不依赖于
f
”)。公式里应该是认为
f¯(x)
是一个常数,则
f¯(x)−yD
是一个只与
yD
有关都变量,可以认为其代表了噪声,而前面是于
f(x;D)
相关的数,两个无关,因此可以分开。
继续推导:
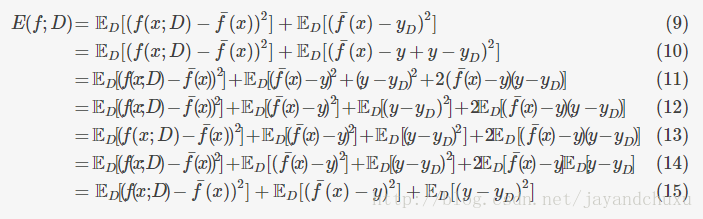
E(f;D)=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−yD)2]=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−y+y−yD)2]=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−y)2+(y−yD)2+2(f¯(x)−y)(y−yD)]=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−y)2]+ED[(y−yD)2]+2ED[(f¯(x)−y)(y−yD)]=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−y)2]+ED[(y−yD)2]+2ED[(f¯(x)−y)(y−yD)]=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−y)2]+ED[(y−yD)2]+2ED[f¯(x)−y]ED[y−yD]=ED[(f(x;D)−f¯(x))2]+ED[(f¯(x)−y)2]+ED[(y−yD)2](9)(10)(11)(12)(13)(14)(15)
这里有一点不太懂:
公式13到14的变化
2ED[(f¯(x)−y)(y−yD)]=2ED[f¯(x)−y]ED[y−yD]
,是因为
f¯(x)−y
是一个常数,还是说偏差与噪声无关?
因为噪声的期望是0,所以式14最后一项为0。
参考
wiki:ROC曲线
【西瓜书】周志华《机器学习》学习笔记与习题探讨(二)②:这个知乎专题的作者很用心,自己配了很多精美的插图。笔记基本是对书上内容的总结,也含有一部分扩充内容,两相对照,也是大有裨益的。
分类器性能指标之ROC曲线、AUC值:里面详细介绍了ROC曲线的画法。
- 是什么决定了你的学习算法泛化性能?偏差—方差分解(bias-variance decomposition):文章里对泛化误差分解进行了仔细推导,写的比西瓜书上的细致。