5.1print和import的更多特性。
5.1.1使用逗号输出
print可以通过逗号输出多个表达式。

5.1.2把某件事作为另一件事导入
四种import的方式:
1.import module
2.from module import function1
3.from module import function1, function2...
4 from module import *:import module中的所有function
假如import两个module有名字相同的函数,那么可以直接用第一种方法区分。用法是module1.function()和module2.function()
也可以通过as为整个模块或者函数提供别名:
1.为模块提供别名
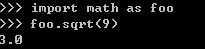
2.为函数提供别名

5.2赋值
5.2.1并行赋值:序列解包(sequence unpacking)
一般的赋值都是一个值赋值给一个变量,例如a=1。并行赋值则是多个不同的值赋值给多个变量。它的过程相当于把左边的所有变量和右边所有的值当成序列(等号右边可以是序列),把右边的序列解开,再把其中的值赋值到左边的每个变量上。这个过程也被称为序列解包。因为它是将左边变量和右边的值一一对应的过程,所以左右两边的变量数和值的数量必须相等(没有‘*’号时,下面会具体讲),否则会报错。

当然也可以在右边的值两旁添加'[ ]'直接转为序列:
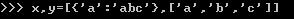
当函数返回序列是,序列解包很容易快速获得序列中想要的数据。
另外,在序列解包中有时可以运用‘*‘号。例子如下:

没有星号的,根据他们的相对位置会被赋一个值(a是第一个,赋值1,c是最后一个,赋值4,剩下的全赋值给b),剩下的值都将以列表的形式赋值给有星号的变量。每一次并行赋值中最多只能有一个有星号的变量。
5.2.2链式赋值(chained assignment)
链式赋值就是一个值赋值给多个变量。变量间用等号连接。
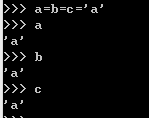
和
c='a' b=c a=b
效果一样。
5.2.3增量赋值
简单来说,就是讲x=x+1这种式子用x+=1来表达。可以让代码显得更加简练和紧凑,但实质上并无差别。
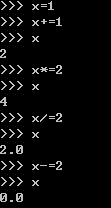
有意思的是'*=’。经过前几章的学习,我们知道序列可以通过*来制造一个重复多次的序列。例如:

因为a*2是产生一个新的列表,所以重新赋值给a会改变a的地址。但是如果a*=2的话,虽然得出来的值一样,但是是会在原对象的基础上改变,所以地址没变。
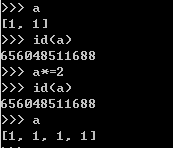
但是如果序列是immutable(不可变的),像元组,是不能在原对象的基础上进行任何改变的,所以一定会创建新的元组,因此地址会改变。

5.3语句块
语句块是在条件为真(条件语句)时执行和执行多次(循环语句)的一组语句,需要在在代码前放置空格(python为四个)来缩进语句。
tab和空格的区别:tab和空格键都可以缩进。以python为例,在ide中设置tab缩进为四个空格长度后,两者表现是一样的,但是在其他人的ide中,如果设置tab为其他数量(例如x)的空格,那么tab键表现出来的缩进则是x格空格,而不再是4个。所以标准推荐方法是直接用空格而不是tab,那么在任何情况下缩进都会是4个空格。
另外,python对于缩进的要求很严格。像在java和c语言中,缩进更多的是为了程序的易读性,对程序的运行并不会有任何的影响,而在python中,错误的缩进会直接导致错误的运行,甚至报错。
在python中,是用冒号(:)用来标识语句块的开始。更多的语句块的例子可以在下面的条件语句和循环语句中找到。
5.4条件和条件语句
5.4.1布尔变量(boolean)
布尔变量有两个标准值,“True”和“False”(真和假),True==1, False==0。。下列的式子,作为布尔表达式时,会被解释器当成假:
False, None, 0, "", (), {}
除了这几个以外,其他的都会被解释器当成真。
请注意,有些函数返回值为0并不一定代表是返回False。例如Java中的String的compareTo函数,返回值的正负值代表比较的两个变量的大小关系,只有当返回值为0是才代表两个变量相等。
5.4.2条件执行和if语句
如果之前有其他语言的编程基础的话就很容易理解下面的部分。if后面的括号内就是条件,如果条件结果为True,就运行下面代码块的内容。如果结果为False,则直接跳过这一部分。
a=1 b=1 if (a==b): print('a equals to b')
结果:
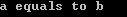
可以添加else字句。如果if后面的条件结果为False,就运行else后面的代码块:
a=1 b=2 if (a==b): print('a equals to b') else: print('a does not equal to b')
结果为:

如果需要检查多个条件,则可以添加elif(相当于其他语言的else if)字句:
a=1 b=2 if (a>1): print('a is greater than 1') elif (b>1): print('b is greater than 1') elif (a<b): print('a is smaller than 1') else: print('None of the conditions has been met')
结果为:

代码的运行顺序是从第一个condition开始检查,因为(a<1)返回False(a等于一而不是小于1),所以跳过代码块直接检查第二个条件。因为b=2,所以(b>1)返回True,运行后面的代码块。运行完之后将直接跳过if-block后面的代码。所以,虽然第三个条件(a<b)返回True,但因为第二个条件已经已经满足了,后面的代码就不会被运行了,'a is smaller than 1'就不会被打印出来。
5.4.3if的嵌套
if的嵌套就是在if语句里面再加上新的if语句,并不难理解。主要是注意下在新的if语句中,需要再一次的缩进。避免犯出下面的错误。
a=2 b=1 if (a>1): print('a is greater than 1') if (b==2): print('Both conditions are met. Position 1') print('Both conditions are met. Position 2')
很明显,代码的本意是满足(a>1)的条件,打印'a is greater than 1‘,两个条件都满足时,打印'both conditions are met'。最后两句输出语句的区别在于一个缩进4个空格,一个缩进8个空格。既满足a>1又满足b==2会打印Position 1(缩进8格)的语句,而不是Position 2(缩进4格)。结果是:

因为b==2返回False,不应该打印出‘Both conditions are met’。所以Position2并不在嵌套里的if里面,而是在最外层的if中。正确的代码应该是:
a=2 b=1 if (a>1): print('a is greater than 1') if (b==2): print('Both conditions are met.')
结果就只有:

5.4.4更复杂的条件
各类运算符:

1.比较运算符:
简单来说,就是比较x,y的大小关系。只有当x,y类型一样或者接近时,比较才有意义。比较1000和‘zyx’的大小是毫无意义的。
2.相等运算符(==):
比较两个变量的值是否相等。
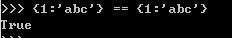
3.同一性运算符(is, is not):
判断x,y是否是指向同一个物体。例如:
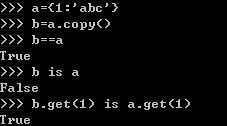
(对于每项比较返回的布尔值的解释可以参考上一章字典的软复制(soft copy)部分。)
4.成员资格运算符(in, not in):
检查元素是否存在于某个变量中。例子可以参考上一章字典的key in dict。
5.字符串和序列比较
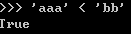
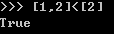
像上面的例子,一般来说,字符串和序列的比较是从第一个元素开始比较,相等的话再开始比较下一个元素,一直到其中一个字符串或序列结束或者两个元素不一样。需要注意的是在字符串的比较中,要注意下大小写的问题。一般来收都是先处理成都是大写或者小写再比较。而在序列的比较中,每个位置的元素类型最好一样。比如:

这个序列的比较看似是没有问题的,没有报错,而且能返回一个True。但是可以看到左边的序列第二个元素是int,而右边的序列第二个元素是一个序列[1,1]。如果需要比较到第二个元素的话,就会报错。

6.布尔运算值(and, or, not)
not就是negate,将True变成False,False变成True。
and(和):两边值都为True时,返回True,否则返回False。
or(或):只要有一边的值为True时,返回True,否则返回False。
可以用and,or来连接多个条件。not用来修饰条件。
需要注意的是,像and,是需要两边条件都为True时,才返回True,所以当计算第一个条件为False时,并不会再计算第二个条件,而是直接返回False。类似的对于or,如果第一个条件为True,那么将直接返回True,也不会再计算第二个条件。(short-circuit logic/ lazy evaluation)因此在条件中放入一些运算时需要多斟酌一下。
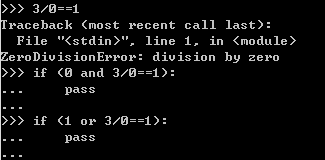
从上面的例子可以看到,由于是以0为除数,所以3/0的运行是会报错的。但是在and和or中,因为第一个条件是False和True,所以会跳过第二个条件,直接返回布尔值,3/0并不会报错。(因为根本没被运行,而3/0的错误是runtime error)
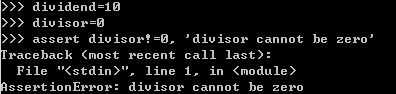
5.4.5断言
assert对于程序的测试是很有帮助的。他的功能是当assert的条件不被满足时,直接程序报错退出。很多时候是用来写test case。可以在assert的条件后面加‘,’再加string用来说明为什么出错。下面这个例子就是在除数为0时报错并说明理由。
5.5循环
循环就是一直重复某段代码直到某个条件不再被满足。
5.5.1while循环
用法(Pseudo-code):
while condition: do something
while循环中的代码块就会一直运行下去,直到condition不再被满足。
5.5.2for循环
在其他很多语言中,for的用法是类似于下面:
for (int a=0; a<10; a++)
这样代码块会运行十次。
而在python中,for是搭配in一起用。如果是遍历序列或者字典的话,可以直接用for变量in序列/字典。
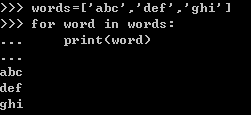
序列:
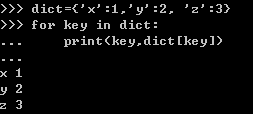
字典:
如果要像其他语言一样迭代某范围的数字,可以用内建函数range:
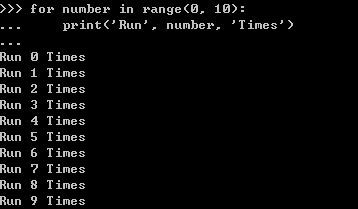
range函数的两个参数代表着初始(包括)和结束(不包括)的index。上面的例子相当于其他语言的:
for (int a=0; a<10; a++){ print('Run' + a + 'Times') }
5.5.3一些迭代工具
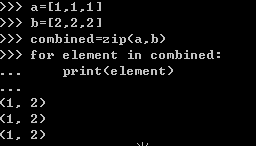
1.并行迭代(zip)
zip的功能就是将两个序列压缩成一个列表,然后返回那个列表的迭代器(zip object,python 3)。由于返回的是迭代器,所以并不能用index来获取element。迭代器可以理解为遍历一个容器(字典,序列等)的一个接口,更多的解释和例子会在第九章中提到。
例子如下:
2.编号迭代(enumerate)
enumerate在迭代式会同时返回索引和数据。

3.翻转(reversed)和排序迭代(sorted)
功能同列表中的reverse和sort类似,但是是作用于可迭代对象上,而不是原地修改对象。
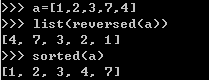
需要注意的是sorted是直接返回一个列表,但是reversed是返回一个迭代器。
5.5.4跳出循环
break和continue:在迭代时,有时并不一定循环到结尾。例如,检查一个数组中是否含有数字1,从第一个元素开始检查,如果检测到了1,就可以直接退出迭代,而不用继续检查其他元素。像这种情况,则需要利用break或者continue来跳出循环。
break和continue区别:break是跳出循环,而continue是跳过当前循环的剩下部分,直接开始下一循环。在其他语言中的switch-case语句中经常用到。
需要注意的时,如果在循环里面嵌套循环,即使break是在里循环中,一旦运行到break,仍然是会跳出外循环。
5.6列表推导式(list comprehension)--轻量级循环
简单来说,就是利用已有的列表创建新列表。像下面的例子,就是将range(10)这个列表的每个元素求平方,再存到另一个列表中。

可以和更多的for和if语句一起用
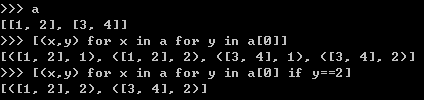
在上面的例子中,x和y的所有元素都会组合成一对,不满足if条件的会在结果中去除。
5.7pass,del和exec&eval
pass:pass就是一个什么都不运行的语句。因为在python中,空代码块是不被允许的,如果暂时不知道在if或者其他需要代码块的语句需要填什么的话,可以先填写pass。
del:我们都知道,变量实际是对对象的引用,在赋值给一个变量之后又赋其他值给同一个变量,只是让变量成为另一个对象的引用。del的功能则是完全删除变量对对象的引用,以及移除名字本身。例如del x之后,再次引用x则会显示undefined(未定义)。
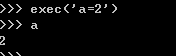
exec:执行字符串中的python语句,并不返回任何对象:
eval:计算python表达式,返回结果值:

从string或者code对象中执行代码也是python作为动态语言的一个特色。可以应用在服务器的热部署方面,除非大的版本更新,可以只重新部署改动的部分,而不是所有代码。exec和eval更多的实际操作可以等到有具体需求时再去了解。exec的原理可以参考下面的文章:
http://lucumr.pocoo.org/2011/2/1/exec-in-python/