数据缓存池类
游戏中AI必不可少,为了营造更加真实的AI需要赋予AI更加真实的数据, 其中最为瞩目的就是名字和匹配时的头像, 解决的办法有随机和名称库。显然这些数据不如采用真实的玩家数据。
使用真实的玩家数据可以从数据库进行随机筛选也可以采用缓冲的方式, 在匹配进程上对前来匹配的玩家的数据进行缓存。由于数据库操作会带来一定的风险, 因此采用玩家信息缓存的方式。对于数据的缓存存在两个问题, 一个是存, 一个是取。缓存池的大小必须是有限的,然而游戏中每秒需要创建的AI可能是比较多,这就需要刷新缓存池中的数据,以便每次取出的玩家信息都是变化的,而不是打几场就发现老是这几个人。而取数据又是另外一个问题,显然对于缓存的名字一局游戏中是不应该相同的,这就是数纯随机的抽取会不做互斥判定还是可能重名的,多次从缓冲池中抽取数据又是比较费时费力的。基于以上分析, 在实际的解决中采用如下存储、刷新、获取策略:
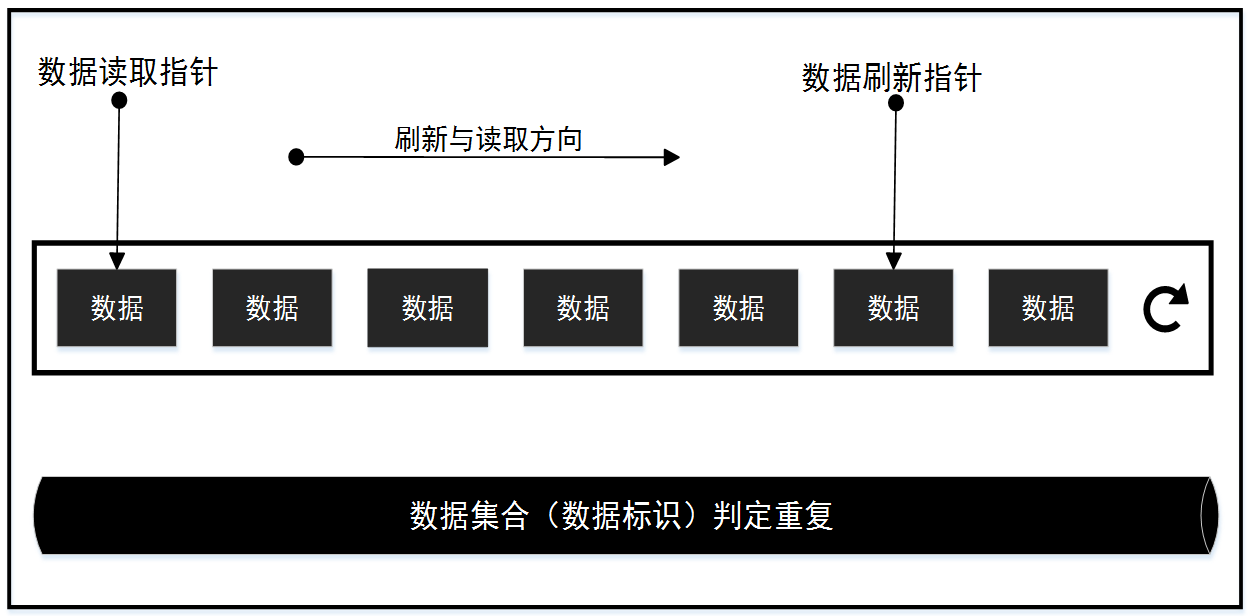
图 1 数据缓冲池结构图
数据缓冲池策略:
1) 数据刷新: 不断向缓冲池列表内加入需要缓存的数据,缓冲池满后回到头部进行覆盖刷新。 如果需要数据不同的限制, 在数据加入缓存池前进行重复判定,为提高效率减少内存可在数据可加入缓冲池时抽取数据唯一标识,添加到数据集合中。值得注意的是如果采用了数据集合进行数据互斥, 那么需要在数据被覆盖的时候将数据标识从数据集合中删除, 避免数据集合无限增大,吃掉所有内存。
2) 数据读取: 数据读取独立于数据刷新,顺序的从缓存池中读取, 当读取的数据为空表示数据刷新不及时,此时读取指针从头在进行数据的读取。
3) 数据监控: 数据监控的原因是如果采用了数据集合进行数据互斥,那么就需要对数据集合的大小进行监控。避免异常发生时集合中产生死数据累积的情况,监控的策略是监控集合大小, 超过缓冲队列大小一定数值后, 重置数据集合。
代码
class MatchDataCache(object):
"""
数据缓存类
"""
def __init__(self, max_size, is_unique, get_default_data):
"""
@ max_size: 缓存池的大小
@ is_unique: 缓存的数据是否各不相同
@ get_default_data: 缓存数据不足时提供默认数据的函数
"""
super(MatchDataCache, self).__init__()
# 参数记录
self._max_size = max(max_size, 10)
self._is_unique = is_unique
self._get_default_data = get_default_data
# 创建缓冲池
self._cache_data_set = set()
self._cache_data_list = [None for i in xrange(self._max_size)]
self._update_index = 0
self._read_index = 0
def update_cache_data(self, data_list):
"""
更新缓冲的数据, 向缓冲池注入数据
"""
self.check_cache_size()
for data in data_list:
if self._is_unique:
if data not in self._cache_data_set:
# 索引循环
if self._update_index >= self._max_size:
self._update_index = 0
# 删除被覆盖的数据
old_data = self._cache_data_list[self._update_index]
if old_data in self._cache_data_set:
self._cache_data_set.remove(old_data)
# 加入新的数据
self._cache_data_list[self._update_index] = data
self._cache_data_set.add(data)
# 索引递增
self._update_index += 1
else:
# 索引循环
if self._update_index >= self._max_size:
self._update_index = 0
# 覆盖数据
self._cache_data_list[self._update_index] = data
# 索引递增
self._update_index += 1
def get_cache_data(self):
"""
获取缓存池中的数据
"""
# 索引循环
if self._read_index >= self._max_size:
self._read_index = 0
# 顺序读取缓存池中的数据
cache_data = self._cache_data_list[self._read_index]
if cache_data is None:
cache_data = self._cache_data_list[0]
if cache_data is None:
cache_data = self._get_default_data()
self._read_index = 1
return cache_data
else:
self._read_index += 1
return cache_data
def check_cache_size(self):
"""
检测缓存大小, 避免异常时缓存泄露
"""
if len(self._cache_data_set) > 2 * self._max_size:
self._cache_data_set = set(self._cache_data_list)
def destory(self):
"""
清空缓冲数据
"""
self._update_index = 0
self._read_index = 0
self._cache_data_list = []
self._cache_data_set.clear()