【中文】【吴恩达课后编程作业】Course 4 - 卷积神经网络 - 第四周作业 - 人脸识别与神经风格转换
资料下载
- 本文所使用的资料已上传到百度网盘【点击下载(555.65MB)】,请在开始之前下载好所需资料,底部不提供代码。
【博主使用的python版本:3.6.2】
第一部分 - 人脸识别
给之前的“欢乐家”添加人脸识别系统
这是第4周的编程作业,在这里你将构建一个人脸识别系统。这里的许多想法来自FaceNet。在课堂中,吴恩达老师也讨论了 DeepFace。
人脸识别系统通常被分为两大类:
人脸验证:“这是不是本人呢?”,比如说,在某些机场你能够让系统扫描您的面部并验证您是否为本人从而使得您免人工检票通过海关,又或者某些手机能够使用人脸解锁功能。这些都是1:1匹配问题。
人脸识别:“这个人是谁?”,比如说,在视频中的百度员工进入办公室时的脸部识别视频的介绍,无需使用另外的ID卡。这个是1:K的匹配问题。
FaceNet可以将人脸图像编码为一个128位数字的向量从而进行学习,通过比较两个这样的向量,那么我们就可以确定这两张图片是否是属于同一个人。
在本节中,你将学到:
实现三元组损失函数。
使用一个已经训练好了的模型来将人脸图像映射到一个128位数字的的向量。
使用这些编码来执行人脸验证和人脸识别。
在此次练习中,我们使用一个训练好了的模型,该模型使用了“通道优先”的约定来代表卷积网络的激活,而不是在视频中和以前的编程作业中使用的“通道最后”的约定。换句话说,数据的维度是 而不是 ,这两种约定在开源实现中都有一定的吸引力,但是在深度学习的社区中还没有统一的标准。
我们先来导入需要的包:
from keras.models import Sequential
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
from keras.layers.merge import Concatenate
from keras.layers.core import Lambda, Flatten, Dense
from keras.initializers import glorot_uniform
from keras.engine.topology import Layer
from keras import backend as K
#------------用于绘制模型细节,可选--------------#
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
#------------------------------------------------#
K.set_image_data_format('channels_first')
import time
import cv2
import os
import numpy as np
from numpy import genfromtxt
import pandas as pd
import tensorflow as tf
import fr_utils
from inception_blocks_v2 import *
%matplotlib inline
%load_ext autoreload
%autoreload 2
np.set_printoptions(threshold=np.nan)0 - 简单的人脸验证
在人脸验证中,你需要给出两张照片并想知道是否是同一个人,最简单的方法是逐像素地比较这两幅图像,如果图片之间的误差小于选择的阈值,那么则可能是同一个人。

当然,如果你真的这么做的话效果一定会很差,因为像素值的变化在很大程度上是由于光照、人脸的朝向、甚至头部的位置的微小变化等等。接下来与使用原始图像不同的是我们可以让系统学习构建一个编码 ,对该编码的元素进行比较,可以更准确地判断两幅图像是否属于同一个人。
1 - 将人脸图像编码为128位的向量
1.1 - 使用卷积网络来进行编码
FaceNet模型需要大量的数据和长时间的训练,因为,遵循在应用深度学习设置中常见的实践,我们要加载其他人已经训练过的权值。在网络的架构上我们遵循Szegedy et al.等人的初始模型。这里我们提供了初始模型的实现方法,你可以打开inception_blocks.py文件来查看是如何实现的。
关键信息如下:
该网络使用了 的RGB图像作为输入数据,图像数量为 ,输入的数据维度为 .
输出为 的已经编码的 个 位的向量。
我们可以运行下面的代码来创建一个人脸识别的模型。
#获取模型
FRmodel = faceRecoModel(input_shape=(3,96,96))
#打印模型的总参数数量
print("参数数量:" + str(FRmodel.count_params()))执行结果:
参数数量:3743280我们可以绘制出模型细节(可选):
#------------用于绘制模型细节,可选--------------#
%matplotlib inline
plot_model(FRmodel, to_file='FRmodel.png')
SVG(model_to_dot(FRmodel).create(prog='dot', format='svg'))
#------------------------------------------------#执行结果: 结果请详见文章最底部或者资料中的“FRmodel.png”
通过使用128神经元全连接层作为最后一层,该模型确保输出是大小为128的编码向量,然后使用比较两个人脸图像的编码如下:

通过计算两个编码和阈值之间的误差,可以确定这两幅图是否代表同一个人。
因此,如果满足下面两个条件的话,编码是一个比较好的方法:
同一个人的两个图像的编码非常相似。
两个不同人物的图像的编码非常不同。
三元组损失函数将上面的形式实现,它会试图将同一个人的两个图像(对于给定的图和正例)的编码“拉近”,同时将两个不同的人的图像(对于给定的图和负例)进一步“分离”。

在下一部分中,我们将从左到右调用图片: Anchor (A), Positive (P), Negative (N)
1.3 - 三元组损失函数
对于给定的图像
,其编码为
,其中
为神经网络的计算函数。

我们将使用三元组图像 进行训练:
是“Anchor”,是一个人的图像。
是“Positive”,是相对于“Anchor”的同一个人的另外一张图像。
是“Negative”,是相对于“Anchor”的不同的人的另外一张图像。
这些三元组来自训练集,我们使用 来表示第 个训练样本。我们要保证图像 与图像 的差值至少比与图像 的差值相差 :
我们希望让三元组损失变为最小:
- 在这里,我们使用“ ”来表示函数
需要注意的是:
公式(2)是给定三元组 与正例 之间的距离的平方,我们要让它变小。
公式(3)是给定三元组 与负例 之间的距离的平方,我们要让它变大,经公式(1)变换后前面偶一个负号。
是间距,这个需要我们来手动选择,这里我们使用
大多数实现将编码归一化为范数等于1的向量,即( =1),这里你没必要操心这个。现在我们要实现公式(4),由以下4步构成:
计算”anchor” 与 “positive”之间编码的距离:
计算”anchor” 与 “negative”之间编码的距离:
根据公式计算每个样本的值:
通过取带零的最大值和对训练样本的求和来计算整个公式:
一些会用到的函数:tf.reduce_sum(), tf.square(), tf.subtract(), tf.add(), tf.maximum(),对于步骤1与步骤2,需要对
、
的其中的项进行求和,对于步骤4,你需要对整个训练集进行求和。
def triplet_loss(y_true, y_pred, alpha = 0.2):
"""
根据公式(4)实现三元组损失函数
参数:
y_true -- true标签,当你在Keras里定义了一个损失函数的时候需要它,但是这里不需要。
y_pred -- 列表类型,包含了如下参数:
anchor -- 给定的“anchor”图像的编码,维度为(None,128)
positive -- “positive”图像的编码,维度为(None,128)
negative -- “negative”图像的编码,维度为(None,128)
alpha -- 超参数,阈值
返回:
loss -- 实数,损失的值
"""
#获取anchor, positive, negative的图像编码
anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]
#第一步:计算"anchor" 与 "positive"之间编码的距离,这里需要使用axis=-1
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,positive)),axis=-1)
#第二步:计算"anchor" 与 "negative"之间编码的距离,这里需要使用axis=-1
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,negative)),axis=-1)
#第三步:减去之前的两个距离,然后加上alpha
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist),alpha)
#通过取带零的最大值和对训练样本的求和来计算整个公式
loss = tf.reduce_sum(tf.maximum(basic_loss,0))
return loss我们来测试一下:
with tf.Session() as test:
tf.set_random_seed(1)
y_true = (None, None, None)
y_pred = (tf.random_normal([3, 128], mean=6, stddev=0.1, seed = 1),
tf.random_normal([3, 128], mean=1, stddev=1, seed = 1),
tf.random_normal([3, 128], mean=3, stddev=4, seed = 1))
loss = triplet_loss(y_true, y_pred)
print("loss = " + str(loss.eval()))测试结果:
loss = 528.1432 - 加载训练好了的模型
FaceNet是通过最小化三元组损失来训练的,但是由于训练需要大量的数据和时间,所以我们不会从头训练,相反,我们会加载一个已经训练好了的模型,运行下列代码来加载模型,可能会需要几分钟的时间。
#开始时间
start_time = time.clock()
#编译模型
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
#加载权值
fr_utils.load_weights_from_FaceNet(FRmodel)
#结束时间
end_time = time.clock()
#计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")执行结果:
执行了:1分48秒这里有一些3个人之间的编码距离的例子:

三个人的编码之间的距离的输出示例
现在我们使用这个模型进行人脸验证和人脸识别。
3 - 模型的应用
之前我们对“欢乐家”添加了笑脸识别,现在我们要构建一个面部验证系统,以便只允许来自指定列表的人员进入。为了通过门禁,每个人都必须在门口刷身份证以表明自己的身份,然后人脸识别系统将检查他们到底是谁。
3.1 - 人脸验证
我们构建一个数据库,里面包含了允许进入的人员的编码向量,我们使用fr_uitls.img_to_encoding(image_path, model)函数来生成编码,它会根据图像来进行模型的前向传播。
我们这里的数据库使用的是一个字典来表示,这个字典将每个人的名字映射到他们面部的128维编码上。
database = {}
database["danielle"] = fr_utils.img_to_encoding("images/danielle.png", FRmodel)
database["younes"] = fr_utils.img_to_encoding("images/younes.jpg", FRmodel)
database["tian"] = fr_utils.img_to_encoding("images/tian.jpg", FRmodel)
database["andrew"] = fr_utils.img_to_encoding("images/andrew.jpg", FRmodel)
database["kian"] = fr_utils.img_to_encoding("images/kian.jpg", FRmodel)
database["dan"] = fr_utils.img_to_encoding("images/dan.jpg", FRmodel)
database["sebastiano"] = fr_utils.img_to_encoding("images/sebastiano.jpg", FRmodel)
database["bertrand"] = fr_utils.img_to_encoding("images/bertrand.jpg", FRmodel)
database["kevin"] = fr_utils.img_to_encoding("images/kevin.jpg", FRmodel)
database["felix"] = fr_utils.img_to_encoding("images/felix.jpg", FRmodel)
database["benoit"] = fr_utils.img_to_encoding("images/benoit.jpg", FRmodel)
database["arnaud"] = fr_utils.img_to_encoding("images/arnaud.jpg", FRmodel)现在,当有人出现在你的门前刷他们的身份证的时候,你可以在数据库中查找他们的编码,用它来检查站在门前的人是否与身份证上的名字匹配。
现在我们要实现 verify() 函数来验证摄像头的照片(image_path)是否与身份证上的名称匹配,这个部分可由以下步骤构成:
根据
image_path来计算编码。计算与存储在数据库中的身份图像的编码的差距。
如果差距小于0.7,那么就打开门,否则就不开门。
如上所述,我们使用L2(np.linalg.norm)来计算差距。(注意:在本实现中,将L2的误差(而不是L2误差的平方)与阈值0.7进行比较。)
def verify(image_path, identity, database, model):
"""
对“identity”与“image_path”的编码进行验证。
参数:
image_path -- 摄像头的图片。
identity -- 字符类型,想要验证的人的名字。
database -- 字典类型,包含了成员的名字信息与对应的编码。
model -- 在Keras的模型的实例。
返回:
dist -- 摄像头的图片与数据库中的图片的编码的差距。
is_open_door -- boolean,是否该开门。
"""
#第一步:计算图像的编码,使用fr_utils.img_to_encoding()来计算。
encoding = fr_utils.img_to_encoding(image_path, model)
#第二步:计算与数据库中保存的编码的差距
dist = np.linalg.norm(encoding - database[identity])
#第三步:判断是否打开门
if dist < 0.7:
print("欢迎 " + str(identity) + "回家!")
is_door_open = True
else:
print("经验证,您与" + str(identity) + "不符!")
is_door_open = False
return dist, is_door_open 现在younes在门外,相机已经拍下了照片并存放在了(“images/camera_0.jpg”),现在我们来验证一下~

verify("images/camera_0.jpg","younes",database,FRmodel)执行结果:
欢迎 younes回家!
(0.65939206, True) Benoit已经被禁止进入,也从数据库中删除了自己的信息,他偷了Kian的身份证并试图通过门禁,我们来看看他能不能进入呢?

verify("images/camera_2.jpg", "kian", database, FRmodel)执行结果:
经验证,您与kian不符!
(0.86224037, False)3.2 - 人脸识别
面部验证系统基本运行良好,但是自从Kian的身份证被偷后,那天晚上他回到房子那里就不能进去了!为了减少这种恶作剧,你想把你的面部验证系统升级成面部识别系统。这样就不用再带身份证了,一个被授权的人只要走到房子前面,前门就会自动为他们打开!
我们将实现一个人脸识别系统,该系统将图像作为输入,并确定它是否是授权人员之一(如果是,是谁),与之前的人脸验证系统不同,我们不再将一个人的名字作为输入的一部分。
现在我们要实现who_is_it()函数,实现它需要有以下步骤:
根据image_path计算图像的编码。
从数据库中找出与目标编码具有最小差距的编码。
- 初始化
min_dist变量为足够大的数字(100),它将找到与输入的编码最接近的编码。 - 遍历数据库中的名字与编码,可以使用
for (name, db_enc) in database.items()语句。
- 计算目标编码与当前数据库编码之间的L2差距。
- 如果差距小于min_dist,那么就更新名字与编码到identity与min_dist中。
- 初始化
def who_is_it(image_path, database,model):
"""
根据指定的图片来进行人脸识别
参数:
images_path -- 图像地址
database -- 包含了名字与编码的字典
model -- 在Keras中的模型的实例。
返回:
min_dist -- 在数据库中与指定图像最相近的编码。
identity -- 字符串类型,与min_dist编码相对应的名字。
"""
#步骤1:计算指定图像的编码,使用fr_utils.img_to_encoding()来计算。
encoding = fr_utils.img_to_encoding(image_path, model)
#步骤2 :找到最相近的编码
## 初始化min_dist变量为足够大的数字,这里设置为100
min_dist = 100
## 遍历数据库找到最相近的编码
for (name,db_enc) in database.items():
### 计算目标编码与当前数据库编码之间的L2差距。
dist = np.linalg.norm(encoding - db_enc)
### 如果差距小于min_dist,那么就更新名字与编码到identity与min_dist中。
if dist < min_dist:
min_dist = dist
identity = name
# 判断是否在数据库中
if min_dist > 0.7:
print("抱歉,您的信息不在数据库中。")
else:
print("姓名" + str(identity) + " 差距:" + str(min_dist))
return min_dist, identityYounes站在前门,相机给他拍了张照片(“images/camera_0.jpg”)。让我们看看who_it_is()算法是否识别Younes。
who_is_it("images/camera_0.jpg", database, FRmodel)执行结果:
姓名younes 差距:0.659392
(0.65939206, 'younes')请记住:
人脸验证解决了更容易的1:1匹配问题,人脸识别解决了更难的1∶k匹配问题。
三重损失是训练神经网络学习人脸图像编码的一种有效的损失函数。
相同的编码可用于验证和识别。测量两个图像编码之间的距离可以确定它们是否是同一个人的图片。
第二部分 - 神经风格转换
深度学习在艺术上的应用:神经风格转换
这是本周的第二个编程作业,在这里我们将学习到如何进行神经风格转换,这个算法是Gatys创立的(2015,https://arxiv.org/abs/1508.06576 )。
在这里,我们将:
实现神经风格转换算法
用算法生成新的艺术图像
在之前的学习中我们都是优化了一个成本函数来获得一组参数值,在这里我们将优化成本函数以获取像素值,我们先来导入包:
import time
import os
import sys
import scipy.io
import scipy.misc
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from PIL import Image
import nst_utils
import numpy as np
import tensorflow as tf
%matplotlib inline1 - 问题描述
神经风格转换(Neural Style Transfer,NST)是深学习中最有趣的技术之一。如下图所示,它合并两个图像,即“内容”图像( ontent)和“风格”图像( tyle),以创建“生成的”图像( enerated)。生成的图像G将图像C的“内容”与图像S的“风格”相结合。
在这个例子中,你将生成一个巴黎卢浮宫博物馆(内容图像C)与一个领袖印象派运动克劳德·莫奈的画(风格图像S)混合起来的绘画。

我们来看看到底该怎样做~
2 - 迁移学习
神经风格转换(NST)使用先前训练好了的卷积网络,并在此基础之上进行构建。使用在不同任务上训练的网络并将其应用于新任务的想法称为迁移学习。
根据原始的NST论文(https://arxiv.org/abs/1508.06576 ),我们将使用VGG网络,具体地说,我们将使用VGG-19,这是VGG网络的19层版本。这个模型已经在非常大的ImageNet数据库上进行了训练,因此学会了识别各种低级特征(浅层)和高级特征(深层)。
运行以下代码从VGG模型加载参数。这可能需要几秒钟的时间。
model = nst_utils.load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
print(model)执行结果:
{'input': <tf.Variable 'Variable:0' shape=(1, 300, 400, 3) dtype=float32_ref>, 'conv1_1': <tf.Tensor 'Relu:0' shape=(1, 300, 400, 64) dtype=float32>, 'conv1_2': <tf.Tensor 'Relu_1:0' shape=(1, 300, 400, 64) dtype=float32>, 'avgpool1': <tf.Tensor 'AvgPool:0' shape=(1, 150, 200, 64) dtype=float32>, 'conv2_1': <tf.Tensor 'Relu_2:0' shape=(1, 150, 200, 128) dtype=float32>, 'conv2_2': <tf.Tensor 'Relu_3:0' shape=(1, 150, 200, 128) dtype=float32>, 'avgpool2': <tf.Tensor 'AvgPool_1:0' shape=(1, 75, 100, 128) dtype=float32>, 'conv3_1': <tf.Tensor 'Relu_4:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_2': <tf.Tensor 'Relu_5:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_3': <tf.Tensor 'Relu_6:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_4': <tf.Tensor 'Relu_7:0' shape=(1, 75, 100, 256) dtype=float32>, 'avgpool3': <tf.Tensor 'AvgPool_2:0' shape=(1, 38, 50, 256) dtype=float32>, 'conv4_1': <tf.Tensor 'Relu_8:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_2': <tf.Tensor 'Relu_9:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_3': <tf.Tensor 'Relu_10:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_4': <tf.Tensor 'Relu_11:0' shape=(1, 38, 50, 512) dtype=float32>, 'avgpool4': <tf.Tensor 'AvgPool_3:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_1': <tf.Tensor 'Relu_12:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_2': <tf.Tensor 'Relu_13:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_3': <tf.Tensor 'Relu_14:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_4': <tf.Tensor 'Relu_15:0' shape=(1, 19, 25, 512) dtype=float32>, 'avgpool5': <tf.Tensor 'AvgPool_4:0' shape=(1, 10, 13, 512) dtype=float32>}该模型存储在一个python字典中,其中每个变量名都是键,相应的值是一个包含该变量值的张量,要通过此网络运行图像,只需将图像提供给模型。 在TensorFlow中,你可以使用tf.assign函数来做到这一点:
#tf.assign函数用法
model["input"].assign(image) 这将图像作为输入给模型,在此之后,如果想要访问某个特定层的激活,比如4_2,请这样做:
#访问 4_2 层的激活
sess.run(model["conv4_2"])3 - 神经风格转换
我们可以使用下面3个步骤来构建神经风格转换(Neural Style Transfer,NST)算法:
构建内容损失函数
构建风格损失函数
把它放在一起得到 .
3.1 - 计算内容损失
在我们的运行的例子中,内容图像C是巴黎卢浮宫博物馆的图片,运行下面的代码来看看卢浮宫的图片:
content_image = scipy.misc.imread("images/louvre.jpg")
imshow(content_image)
内容图片(C)显示了卢浮宫的金字塔被旧的巴黎建筑包围,图片上还有阳光灿烂的天空和一些云彩。
3.1.1 - 如何确保生成的图像G与图像C的内容匹配?
正如我们在视频中看到的,浅层的一个卷积网络往往检测到较低层次的特征,如边缘和简单的纹理,更深层往往检测更高层次的特征,如更复杂的纹理以及对象分类等。
我们希望“生成的”图像G具有与输入图像C相似的内容。假设我们选择了一些层的激活来表示图像的内容,在实践中,如果你在网络中间选择一个层——既不太浅也不太深,你会得到最好的的视觉结果。(当你完成了这个练习后,你可以用不同的图层进行实验,看看结果是如何变化的。)
假设你选择了一个特殊的隐藏层,现在,将图像C作为已经训练好的VGG网络的输入,然后进行前向传播。让 成为你选择的层中的隐藏层激活(在视频中吴恩达老师写作 ,但在这里我们将去掉上标 以简化符号),激活值为 的张量。然后用图像G重复这个过程:将G设置为输入数据,并进行前向传播,让 成为相应的隐层激活,我们将把内容成本函数定义为:
博主注: 的出处请详见视频4.9内容代价函数视频,于2:24处,吴恩达老师提及到“也可以在前面加上归一化或者不加,比如 或者其他的,都影响不大”。
这里 分别代表了你选择的隐藏层的高度、宽度、通道数,并出现在成本的归一化项中,为了使得方便理解,需要注意的是 与 是与隐藏层激活相对应的卷积值,为了计算成本 ,可以方便地将这些3D卷积展开为2D矩阵,如下所示。(从技术上讲,不需要这个展开步骤来计算 ,但是当您以后需要执行类似的操作来计算 时,这将是一个很好的实践。)
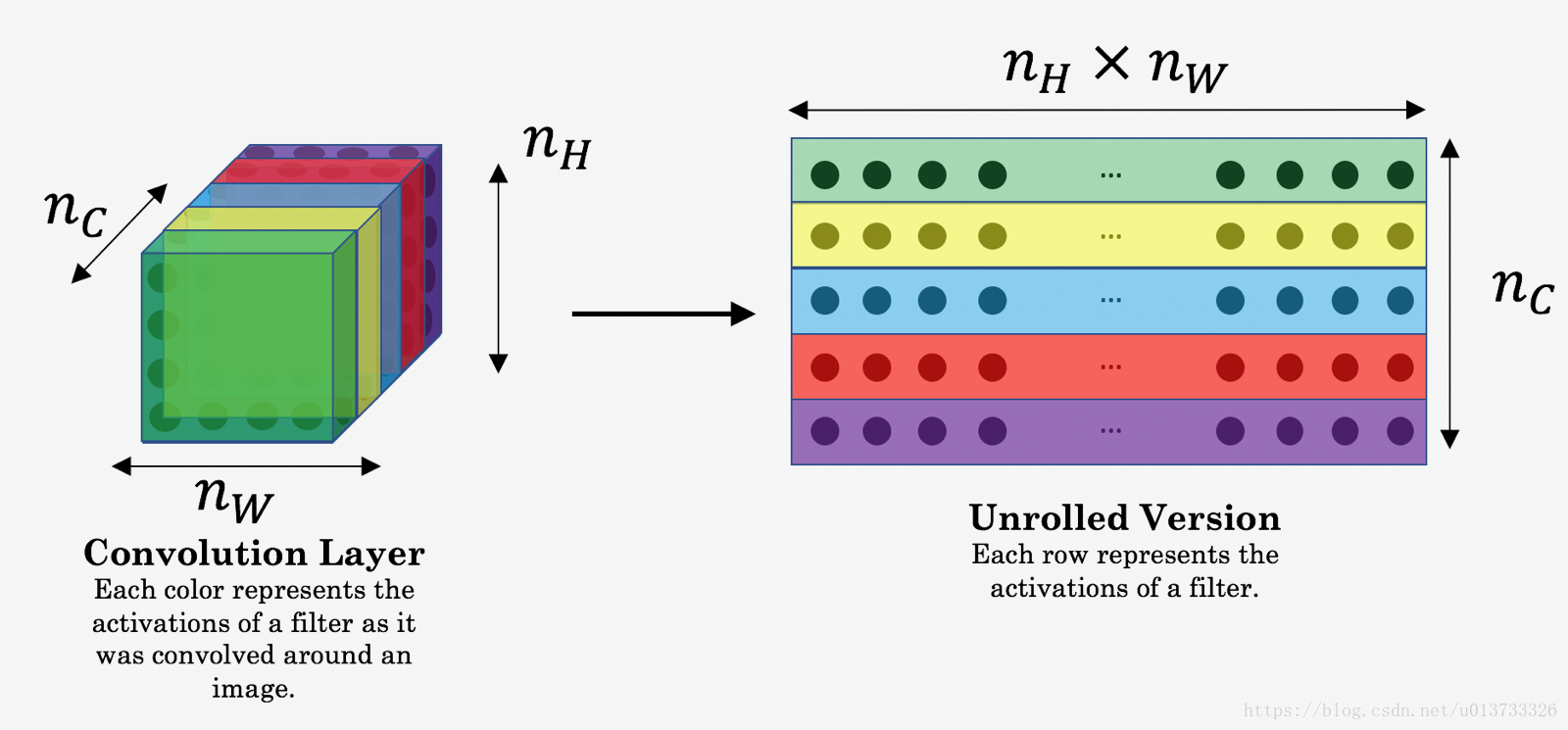
现在我们要使用tensorflow来实现内容代价函数,它由以下3步构成:
从a_G中获取维度信息:
- 从张量X中获取维度信息,可以使用:
X.get_shape().as_list()
- 从张量X中获取维度信息,可以使用:
将a_C与a_G如上图一样降维:
- 如果你在这里遇到了问题,请戳我(transpose),戳我(reshape)【需自备梯子】
计算内容代价:
- 如果你在这里遇到了问题,请戳我(reduce_sum),戳我(square), 戳我(subtract)【【需自备梯子】
def compute_content_cost(a_C, a_G):
"""
计算内容代价的函数
参数:
a_C -- tensor类型,维度为(1, n_H, n_W, n_C),表示隐藏层中图像C的内容的激活值。
a_G -- tensor类型,维度为(1, n_H, n_W, n_C),表示隐藏层中图像G的内容的激活值。
返回:
J_content -- 实数,用上面的公式1计算的值。
"""
#获取a_G的维度信息
m, n_H, n_W, n_C = a_G.get_shape().as_list()
#对a_C与a_G从3维降到2维
a_C_unrolled = tf.transpose(tf.reshape(a_C, [n_H * n_W, n_C]))
a_G_unrolled = tf.transpose(tf.reshape(a_G, [n_H * n_W, n_C]))
#计算内容代价
#J_content = (1 / (4 * n_H * n_W * n_C)) * tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled, a_G_unrolled)))
J_content = 1/(4*n_H*n_W*n_C)*tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled, a_G_unrolled)))
return J_content我们来测试一下:
tf.reset_default_graph()
with tf.Session() as test:
tf.set_random_seed(1)
a_C = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
a_G = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
J_content = compute_content_cost(a_C, a_G)
print("J_content = " + str(J_content.eval()))
test.close()测试结果:
J_content = 6.76559需要记住的是:
内容成本采用神经网络的隐层激活,并测量 与 的区别。
当我们以后最小化内容成本时,这将有助于确保 的内容与 相似。
3.2 - 计算风格损失
我们先来看一下下面的风格图片:
style_image = scipy.misc.imread("images/monet_800600.jpg")
imshow(style_image)执行结果:

这幅画是印象派的风格,我们来看一下如何定义“风格”函数
3.2.1 - 风格矩阵
风格矩阵又名“格拉姆矩阵”,在线性代数中,一组向量
的格拉姆矩阵G是点乘的矩阵,计算细节是
,换句话说,
比较了
与
的相似之处,如果他们非常相似,那么它们的点积就会很大,所以
就很大。
请注意,这里的变量名是有冲突的,我们遵循论文中的术语,但是
表示风格矩阵(或Gram matrix)的同时也表示了生成的图像
,我们将尽量确保我们所说的
在上下文中指向清晰。
在神经风格转换中,可以通过将降维了的过滤器矩阵与其转置相乘来计算风格矩阵:
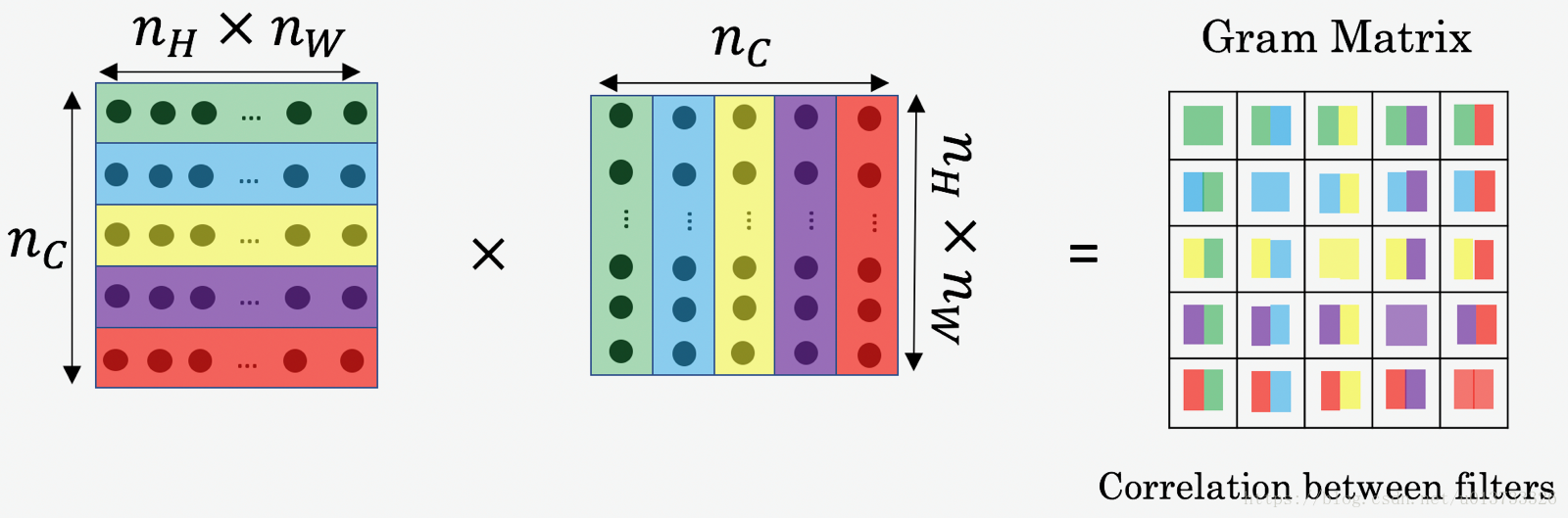
计算后的结果是维度为 的矩阵,其中 是过滤器的数量, 测量了过滤器 的激活与过滤器 的激活具有多大的相似度。
风格矩阵 的一个重要的部分是对角线的元素,它测量了有效的过滤器 的多少。举个例子,假设过滤器 检测的是图像中的垂直的纹理,那么 测量的是图像整体中常见的垂直纹理,如果 很大,这意味着图像有很多垂直纹理。
通过捕捉不同类型的特征( )的多少,以及总共出现了多少不同的特征( ),那么风格矩阵 就测量的是整个图片的风格。
我们现在来使用tensorflow实现计算矩阵A的风格矩阵,计算公式是这样的: 。
def gram_matrix(A):
"""
计算矩阵A的风格矩阵
参数:
A -- 矩阵,维度为(n_C, n_H * n_W)
返回:
GA -- A的风格矩阵,维度为(n_C, n_C)
"""
GA = tf.matmul(A, A, transpose_b = True)
return GA我们来测试一下:
tf.reset_default_graph()
with tf.Session() as test:
tf.set_random_seed(1)
A = tf.random_normal([3, 2*1], mean=1, stddev=4)
GA = gram_matrix(A)
print("GA = " + str(GA.eval()))
test.close()测试结果:
GA = [[ 6.42230511 -4.42912197 -2.09668207]
[ -4.42912197 19.46583748 19.56387138]
[ -2.09668207 19.56387138 20.6864624 ]]3.2.2 - 风格损失
在生成了风格矩阵(Gram matrix / Style matrix)之后,我们的目标是最小化风格图像的 与生成的图像 之间的距离。现在我们只使用单个隐藏层 ,该层的相应的风格成本定义如下:
其中, 与 分别是风格图像与生成的图像的Gram矩阵,使用网络中特定隐藏层的激活来计算。
现在,我们要来计算单隐藏层的风格损失,它由以下4步构成:
从a_G中获取维度信息:
- 从张量X中获取维度信息,可以使用:
X.get_shape().as_list()
- 从张量X中获取维度信息,可以使用:
将a_S与a_G如上图一样降维:
- 如果你在这里遇到了问题,请戳我(transpose),戳我(reshape)【需自备梯子】
计算S与G的风格矩阵:
- 使用
gram_matrix函数。
- 使用
计算风格损失:
- 如果你在这里遇到了问题,请戳我(reduce_sum),戳我(square), 戳我(subtract)【【需自备梯子】
def compute_layer_style_cost(a_S, a_G):
"""
计算单隐藏层的风格损失
参数:
a_S -- tensor类型,维度为(1, n_H, n_W, n_C),表示隐藏层中图像S的风格的激活值。
a_G -- tensor类型,维度为(1, n_H, n_W, n_C),表示隐藏层中图像G的风格的激活值。
返回:
J_content -- 实数,用上面的公式2计算的值。
"""
#第1步:从a_G中获取维度信息
m, n_H, n_W, n_C = a_G.get_shape().as_list()
#第2步,将a_S与a_G的维度重构为(n_C, n_H * n_W)
a_S = tf.transpose(tf.reshape(a_S, [n_H * n_W, n_C]))
a_G = tf.transpose(tf.reshape(a_G, [n_H * n_W, n_C]))
#第3步,计算S与G的风格矩阵
GS = gram_matrix(a_S)
GG = gram_matrix(a_G)
#第4步:计算风格损失
#J_style_layer = (1/(4 * np.square(n_C) * np.square(n_H * n_W))) * (tf.reduce_sum(tf.square(tf.subtract(GS, GG))))
J_style_layer = 1/(4*n_C*n_C*n_H*n_H*n_W*n_W)*tf.reduce_sum(tf.square(tf.subtract(GS, GG)))
return J_style_layer我们来测试一下:
tf.reset_default_graph()
with tf.Session() as test:
tf.set_random_seed(1)
a_S = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
a_G = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
J_style_layer = compute_layer_style_cost(a_S, a_G)
print("J_style_layer = " + str(J_style_layer.eval()))
test.close()测试结果:
J_style_layer = 9.190283.2.3 风格权值
到目前为止,我们只从一个层使用了风格,如果我们从不同的层“合并”风格成本,我们会得到更好的结果。完成这个练习后,你可以回到这里,用不同的权重进行实验,看看它是如何改变生成的图像 的。
STYLE_LAYERS = [
('conv1_1', 0.2),
('conv2_1', 0.2),
('conv3_1', 0.2),
('conv4_1', 0.2),
('conv5_1', 0.2)]我们可以使用下面的公式来合并成本:
其中,
值来源于STYLE_LAYERS
我们实现了计算单隐藏层的风格损失的功能,我们可以简单地调用它几次,使用STYLE_LAYERS的值对结果进行加权,请仔细阅读下面的代码,要确保你明白它到底在干啥:
def compute_style_cost(model, STYLE_LAYERS):
"""
计算几个选定层的总体风格成本
参数:
model -- 加载了的tensorflow模型
STYLE_LAYERS -- 字典,包含了:
- 我们希望从中提取风格的层的名称
- 每一层的系数(coeff)
返回:
J_style - tensor类型,实数,由公式(2)定义的成本计算方式来计算的值。
"""
# 初始化所有的成本值
J_style = 0
for layer_name, coeff in STYLE_LAYERS:
#选择当前选定层的输出
out = model[layer_name]
#运行会话,将a_S设置为我们选择的隐藏层的激活值
a_S = sess.run(out)
# 将a_G设置为来自同一图层的隐藏层激活,这里a_G引用model[layer_name],并且还没有计算,
# 在后面的代码中,我们将图像G指定为模型输入,这样当我们运行会话时,
# 这将是以图像G作为输入,从隐藏层中获取的激活值。
a_G = out
#计算当前层的风格成本
J_style_layer = compute_layer_style_cost(a_S,a_G)
# 计算总风格成本,同时考虑到系数。
J_style += coeff * J_style_layer
return J_style需要注意的是:在上面for循环的内循环中,a_G是一个张量,还没有被计算。当我们在下面的model_nn()中运行TensorFlow图时,将在每次迭代中对其进行评估和更新。
需要记住的是:
图像的风格可以用隐藏层激活的Gram矩阵来表示,然而我们可以结合多个不同层的成本来获得更好的结果,这与内容表示相反,其通常只使用单个隐藏层就足够了。
最小化风格成本将导致图像 遵循图像 的样式。
3.3 - 定义总成本的优化公式
最后,我们创建一个最小化风格和内容成本的成本函数。公式是:
我们来实现总成本函数,包括内容成本和风格成本。
def total_cost(J_content, J_style, alpha = 10, beta = 40):
"""
计算总成本
参数:
J_content -- 内容成本函数的输出
J_style -- 风格成本函数的输出
alpha -- 超参数,内容成本的权值
beta -- 超参数,风格成本的权值
"""
J = alpha * J_content + beta * J_style
return J我们来测试一下:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(3)
J_content = np.random.randn()
J_style = np.random.randn()
J = total_cost(J_content, J_style)
print("J = " + str(J))
test.close()测试结果:
J = 35.34667875478276解决优化问题
最后,让我们一起来实现神经风格转换,它由以下几步构成:
- 创建交互会话
- 加载内容图像
- 加载风格图像
- 随机初始化生成的图像
- 加载VGG16模型
- 构建TensorFlow图:
- 使用VGG16模型来运行内容图并计算内容成本
- 使用VGG16模型来运行风格图并计算风格成本
- 计算总成本
- 定义优化器与学习速率
- 初始化TensorFlow图,进行多次迭代,每次迭代更新生成的图像。
让我们来一步步的走:
我们已经实现了总成本计算函数
,现在我们要设置TensorFlow来优化关于
的内容,为此,程序必须重置图表并使用交互式会话(”Interactive Session”),与常规会话不同,“交互式会话”将自身设置为默认会话来构建图表。这允许我们在不需要引用会话对象的情况下运行变量,从而简化了代码,现在我们来开始运行交互式会话:
#重设图
tf.reset_default_graph()
#第1步:创建交互会话
sess = tf.InteractiveSession()
#第2步:加载内容图像(卢浮宫博物馆图片),并归一化图像
content_image = scipy.misc.imread("images/louvre_small.jpg")
content_image = nst_utils.reshape_and_normalize_image(content_image)
#第3步:加载风格图像(印象派的风格),并归一化图像
style_image = scipy.misc.imread("images/monet.jpg")
style_image = nst_utils.reshape_and_normalize_image(style_image)
#第4步:随机初始化生成的图像,通过在内容图像中添加随机噪声来产生噪声图像
generated_image = nst_utils.generate_noise_image(content_image)
imshow(generated_image[0])
#第5步:加载VGG16模型
model = nst_utils.load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")执行结果:

为了让程序计算内容成本,现在我们将把a_C与a_G作为选定的隐藏层的激活值,我们将使用conv4_2 层来计算内容成本,下面的代码将做以下事:
将内容图像作为VGG模型的输入。
将a_C设置为“conv4_2”隐藏层的激活值。
将a_G设置为同一隐藏层的激活值。
使用 a_C与a_G计算内容成本
#第6步:构建TensorFlow图:
##将内容图像作为VGG模型的输入。
sess.run(model["input"].assign(content_image))
## 获取conv4_2层的输出
out = model["conv4_2"]
## 将a_C设置为“conv4_2”隐藏层的激活值。
a_C = sess.run(out)
## 将a_G设置为来自同一图层的隐藏层激活,这里a_G引用model["conv4_2"],并且还没有计算,
## 在后面的代码中,我们将图像G指定为模型输入,这样当我们运行会话时,
## 这将是以图像G作为输入,从隐藏层中获取的激活值。
a_G = out
## 计算内容成本
J_content = compute_content_cost(a_C, a_G)
## 将风格图像作为VGG模型的输入
sess.run(model["input"].assign(style_image))
## 计算风格成本
J_style = compute_style_cost(model, STYLE_LAYERS)
## 计算总成本
J = total_cost(J_content, J_style, alpha = 10, beta = 40)
## 定义优化器,设置学习率为2.0
optimizer = tf.train.AdamOptimizer(2.0)
## 定义学习目标:最小化成本
train_step = optimizer.minimize(J)实现用于初始化tensorflow变量的model_nn()函数,将输入图像(初始生成的图像)分配为VGG16模型的输入,并运行train_step以训练。
# 第7步:初始化TensorFlow图,进行多次迭代,每次迭代更新生成的图像。
def model_nn(sess, input_image, num_iterations = 200, is_print_info = True,
is_plot = True, is_save_process_image = True,
save_last_image_to = "output/generated_image.jpg"):
#初始化全局变量
sess.run(tf.global_variables_initializer())
#运行带噪声的输入图像
sess.run(model["input"].assign(input_image))
for i in range(num_iterations):
#运行最小化的目标:
sess.run(train_step)
#产生把数据输入模型后生成的图像
generated_image = sess.run(model["input"])
if is_print_info and i % 20 == 0:
Jt, Jc, Js = sess.run([J, J_content, J_style])
print("第 " + str(i) + "轮训练," +
" 总成本为:"+ str(Jt) +
" 内容成本为:" + str(Jc) +
" 风格成本为:" + str(Js))
if is_save_process_image:
nst_utils.save_image("output/" + str(i) + ".png", generated_image)
nst_utils.save_image(save_last_image_to, generated_image)
return generated_image我们开始来训练:
#开始时间
start_time = time.clock()
#非GPU版本,约25-30min
#generated_image = model_nn(sess, generated_image)
#使用GPU,约1-2min
with tf.device("/gpu:0"):
generated_image = model_nn(sess, generated_image)
#结束时间
end_time = time.clock()
#计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")
执行结果:
第 0轮训练, 总成本为:8.41023e+07 内容成本为:18662.5 风格成本为:2.09789e+06
第 20轮训练, 总成本为:8.06214e+07 内容成本为:18949.0 风格成本为:2.0108e+06
第 40轮训练, 总成本为:6.46119e+07 内容成本为:19035.6 风格成本为:1.61054e+06
第 60轮训练, 总成本为:5.51077e+07 内容成本为:19053.8 风格成本为:1.37293e+06
第 80轮训练, 总成本为:4.8397e+07 内容成本为:19129.9 风格成本为:1.20514e+06
第 100轮训练, 总成本为:4.27102e+07 内容成本为:19158.4 风格成本为:1.06297e+06
第 120轮训练, 总成本为:3.84562e+07 内容成本为:19230.4 风格成本为:956596.0
第 140轮训练, 总成本为:3.44763e+07 内容成本为:19286.8 风格成本为:857087.0
第 160轮训练, 总成本为:3.16614e+07 内容成本为:19375.6 风格成本为:786692.0
第 180轮训练, 总成本为:3.27803e+07 内容成本为:19432.9 风格成本为:814650.0
执行了:1分36秒这里有一些其他的合成效果图:
波斯波利斯古城(伊朗)的美丽遗迹与梵高风格(星夜)混合:
在帕萨加达的赛鲁士大帝的陵墓,与一个来自伊斯法罕的陶瓷喀什的风格相混合:
用一种抽象的蓝色流体绘画风格对湍流流体的科学研究成果相混合:



除此之外,你还可以换成你喜欢的图来进行操作:
content_image = scipy.misc.imread("images/my_content_image.jpg")
style_image = scipy.misc.imread("images/my_style_image.jpg")然后再来执行模型的训练,祝你好运~
