2.9 散列表
散列表是计算机科学里的一个伟大发明,它是由数组、表和一些数学方法相结合,构造起来的一种能够有效支持动态数据的存储和提取的结构。
散列表的一个典型应用是符号表,在一些值 (数据)与动态的字符串 (关键码)集合的成员间建立一种关联。你最喜欢用的编译系统十之八九是使用了散列表,用于管理你的程序里各个变量的信息。你的网络浏览器可能也很好地使用了一个散列表来维持最近使用的页面踪迹。你与Internet的连接可能也用到一个散列表,缓存最近使用的域名和它们的IP地址。
我们先回顾一下比较基本的定义:
项:在链表中,每一个链表中的“链”都被称为“项”。例如,这是一个拥有四个项的链表:

在散列表的思想中,我们把关键码送给一个散列函数(关键码先理解成访问标记吧),产生一个散列值,而产生的散列值被平均分布在一个适当的整数区间中。而产生的散列值被用作储存信息的表的下标。在C和C++中,我们的做法是为每一个散列值关联链表中的一个项(一般是首项的头地址),而这一个链表中的所有项则共享这个散列值。
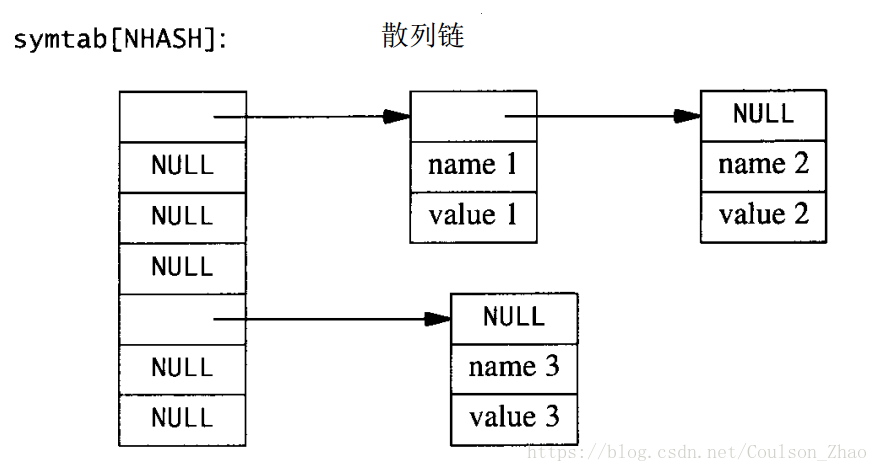
可以看到,散列值被间隔赋值(上图第一列)
每个散列值对应着一个链表,且通常是链表第一项的头地址(上图第二、三列)
在实践中,我们一般预先定义好散列函数,并且分配给其一个大小适当的数组。根据上面的定义,数组的元素应当是一堆链表,而链表中所有的项加在一起应当是散列值对应的所有的数据项。直观而说:
一个具有n个项的散列表是一个数组,其元素是平均长度为(n/数组大小)的链表。
对于一个散列表,它的基本元素和链表相同,都为:
typedef struct Nameval Nameval;
struct Nameval
{
char *name;
int value;
Nameval *next;
};而对于散列表,我们还应该加上一个
Nameval *symtab[NHASH];用来作为散列数组。
而对于这个散列数组到底应该取多大的问题,一般来讲它要足够大,从而使得每个链表最多有几个元素,以保证查询操作是O(1)时间消耗的。
现在,我们需要考虑散列函数hash需要计算出什么东西。对于这个函数来讲,我们要达到以下几个目的:
1.函数需要是确定性的
2.计算速度很快
3.要可以把数据均匀地散布到数组中
而对于字符串来讲,最常见的散列算法就是:逐个地把字节加到已经构造好的部分散列值的倍数上,而乘法能把新字节和已有的值散开,最后的结果将是输入字节的彻底混合。通常来说,乘法系数选择31或者37
unsigned int hash(char *str)
{
unsigned int h = 0;
unsigned char *p;
/* *p取值,p地址向前*/
for (p = (unsigned char *)str; *p != '\0'; p++)
{
h = MULTIPLIER * h + *p;
}
return h;
}对于散列数组究竟取多大这件事情,一般没有特别的定义,但是按照经验来讲,我们选择素数作为数组的长度,在这里就不解释其中的数学原理了。
而全部的代码是:
#include "stdafx.h"
#include "stdlib.h"
#include "string.h"
#include <iostream>
using namespace std;
/*一般来讲,散列数组都会特别大*/
const long long NHASH = 999999;
enum {MULTIPLIER = 31};
typedef struct Nameval Nameval;
struct Nameval
{
char *name;
int value;
Nameval *next;
};
Nameval *symtab[NHASH];
unsigned int hash_count(char *str);
Nameval *lookup(char *name, int create, int value);
int main()
{
lookup("zpb", 1, 0);
return 0;
}
/*计算散列值*/
unsigned int hash_count(char *str)
{
unsigned int h = 0;
unsigned char *p;
/* *p取值,p地址向前*/
for (p = (unsigned char *)str; *p != '\0'; p++)
{
h = MULTIPLIER * h + *p;
}
cout << str << "的散列值是" << h << endl;
return h;
}
/*结合查找与添加,减少计算量*/
Nameval *lookup(char *name, int create, int value)
{
unsigned int h = 0;
Nameval *sym;
h = hash_count(name);
/*symtab就是图形中的第一列,就是散列数组*/
/*sym就是用来寻找链表中项的寻找指针(Nameval型)*/
for (sym = symtab[h]; sym != NULL; sym = sym->next)
{
if (strcmp(name, sym->name) == 0)
{
return sym;
}
}
/*找不到的情况下,是否进行创建*/
if (create)
{
sym = (Nameval *)malloc(sizeof(Nameval));
sym->name = name;
sym->value = value;
/*将新生成的链表项(create出来的)当作数组中symtab[h]所对应的链表的第一项*/
sym->next = symtab[h];
symtab[h] = sym;
}
cout << symtab[h]->name << endl;
return sym;
}