1、Zookeeper的作用
1.管理大量主机的协同服务。
2.分布式应用,实现分布式读写技术。
3.zk提供的服务:
Naming service //按名称区分集群中的节点.
Configuration management //对加入节点的最新化处理。
Cluster management //实时感知集群中节点的增减.
Leader election //leader选举
Locking and synchronization service //修改时锁定数据,实现容灾.
Highly reliable data registry //节点宕机数据也是可用的。2、zk安装(单机版,s201)
1.jdk
2.下载zookeeper-3.4.9.tar.gz
3.tar开
4.符号连接环境变量
$>ln -s zookeeper-3.4.9 zk5.配置zk,复制zoo.cfg.sample–>zoo.cfg
[zk/conf/zoo.conf]
# The number of milliseconds of each tick
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/centos/zookeeper
clientPort=21816.启动zk服务器
$>bin/zkServer.sh start7.验证zk
$>netstat -anop | grep 21818.启动客户端连接到服务器
$>zkCli.sh -server s201:2181 //进入zk命令行
$zk]help //查看帮助
$zk]quit //退出
$zk]create /a tom //
$zk]get /a //查看数据
$zk]ls / //列出节点
$zk]set /a tom //设置数据
$zk]delete /a //删除一个节点
$zk]rmr /a //递归删除所有节点。9.通过api访问zk
添加依赖pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.it18zhang</groupId>
<artifactId>ZooKeeperDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.9</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
</project>API访问操作zk
package cn.ctgu.zktest;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
public class TestZK {
@Test
public void ls() throws Exception {
ZooKeeper zk=new ZooKeeper("172.25.11.200:2181",5000,null);
List<String> list=zk.getChildren("/",null);
for(String s:list){
System.out.println(s);
}
}
//递归输出zk系统目录
@Test
public void lsAll() throws Exception {
ls("/");
}
public void ls(String path) throws Exception {
System.out.println(path);
ZooKeeper zk=new ZooKeeper("172.25.11.200:2181",5000,null);
List<String> list=zk.getChildren(path,null);
if(list==null||list.isEmpty()){
return;
}
for(String s:list){
//先输出孩子
if(path.equals("/")){
ls(path+s);
}else{
ls(path+"/"+s);
}
}
}
/*
*
* 设置数据
*
* */
@Test
public void setData() throws Exception {
ZooKeeper zk=new ZooKeeper("172.25.11.200:2181",5000,null);
//当版本号对应不上的时候则不能设置,即为之前的版本号
zk.setData("/a","tomaslee".getBytes(),0);
}
/*
*
* 创建临时节点
*
* */
@Test
public void reateEmphoral() throws Exception {
ZooKeeper zk=new ZooKeeper("172.25.11.200:2181",5000,null);
zk.create("/b/b3","tom".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("hello");
}
/*
*
* 使用观察者对象
*
* */
@Test
public void testWatch() throws Exception {
final ZooKeeper zk=new ZooKeeper("172.25.11.200:2181",5000,null);
Stat st=new Stat();
Watcher w=null;
w=new Watcher(){
//回调匿名函数
public void process(WatchedEvent event){
try {
System.out.println("数据改了!");
zk.getData("/a",this,null);//获取数据,注册观察者,当回调匿名函数的过程中数据再次改变了则又重新调用回调函数
}catch (Exception e){
e.printStackTrace();
}
}
};
byte[]data=zk.getData("/a",w,st);//获取数据,同时注册一个观察者,当数据改变了立刻调用匿名函数
System.out.println(new String(data));
while(true){
Thread.sleep(1000);
}
}
}3、Zookeeper架构
3.1.Client
从server获取信息,周期性发送数据给server,表示自己还活着。
client连接时,server回传ack信息。
如果client没有收到reponse,自动重定向到另一个server.
3.2.Server
zk集群中的一员,向client提供所有service,回传ack信息给client,表示自己还活着。
3.3.ensemble
一组服务器,最小节点数是3,即zookeeper也是一个集群,通过这个集群实现协同服务。
3.4.Leader
如果连接的节点失败,自动恢复,zk服务启动时,完成leader选举。
3.5.Follower
追寻leader指令的节点。
3.5 znode
zk中的节点,维护了stat,即状态信息,由Version number, Action control list (ACL), Timestamp,Data length.构成.
data version //数据写入的过程变化
ACL //action control list,
节点类型
1.持久节点
client结束,还存在。
2.临时节点
在client活动时有效,断开自动删除。临时节点不能有子节点。
leader推选时使用。
3.序列节点
在节点名之后附加10个数字,主要用于同步和锁.
3.6 Session
Session中的请求以FIFO执行,一旦client连接到server,session就建立了。sessionid分配client。
client以固定间隔向server发送心跳,表示session是valid的,zk集群如果在超时时候,没有收到心跳,判定为client挂了,与此同时,临时节点被删除。
3.7 Watches
观察。
client能够通过watch机制在数据发生变化时收到通知。
client可以在read节点时设置观察者。watch机制会发送通知给注册的客户端。观察模式只触发一次。session过期,watch机制删除了。
4、zk工作流程
zk集群启动后,client连接到其中的一个节点,这个节点可以leader,也可以follower。
连通后,node分配一个id给client,发送ack信息给client。
如果客户端没有收到ack,连接到另一个节点。
client周期性发送心跳信息给节点保证连接不会丢失。
如果client读取数据,发送请求给node,node读取自己数据库,返回节点数据给client.
如果client存储数据,将路径和数据发送给server,server转发给leader。
leader再补发请求给所有follower。只有大多数(超过半数)节点成功响应,则写操作成功。
5、leader推选过程(最小号选举法)
1.所有节点在同一目录下创建临时序列节点。
2.节点下会生成/xxx/xx000000001等节点。
3.序号最小的节点就是leader,其余就是follower.
4.每个节点会观察小于自己节点的主机,例如000000002节点观察000000001节点。(通过注册观察者机制)
5.如果leader挂了,对应znode删除了。
6.观察者收到通知。
6、配置完全分布式zk集群
6.1 没有使用Zookeeper的HA配置
HA(high availability)高可用配置
两个名称节点,一个active(激活态),一个是standby(slave待命),slave节点维护足够多状态以便于容灾。和客户端交互的节点为active节点,standby不交互.两个节点都和JN守护进程构成组进行通信。
数据节点配置两个名称节点,分别向两个名称节点报告各自的信息。同一时刻只能有一个激活态名称节点。
脑裂:两个节点都是激活态。
为防止脑裂,JNs只允许同一时刻只有一个节点向其写数据。容灾发生时,成为active节点的namenode接管向jn的写入工作。
硬件资源
名称节点: 硬件配置相同。
JN节点:轻量级进程,至少3个节点,允许挂掉的节点数 (n - 1) / 2,不需要再运行辅助名称节点(即secondarynamenode)。
配置细节
0.s201和s206具有完全一致的配置,尤其是ssh.
1.配置nameservice
[hdfs-site.xml]
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>2.dfs.ha.namenodes.[nameservice ID]
[hdfs-site.xml]
<!-- myucluster下的名称节点两个id -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>3.dfs.namenode.rpc-address.[nameservice ID].[name node ID]
[hdfs-site.xml]
配置每个nn的rpc地址。
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>s201:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>s206:8020</value>
</property>4.dfs.namenode.http-address.[nameservice ID].[name node ID]
配置webui端口
[hdfs-site.xml]
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>s201:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>s206:50070</value>
</property>5.dfs.namenode.shared.edits.dir
名称节点共享编辑目录.
[hdfs-site.xml]
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://s202:8485;s203:8485;s204:8485/mycluster</value>
</property>6.dfs.client.failover.proxy.provider.[nameservice ID]
java类,client使用它判断哪个节点是激活态。
[hdfs-site.xml]
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>7.dfs.ha.fencing.methods
脚本列表或者java类,在容灾保护激活态的nn,即只维护一个nn,避免脑裂。
[hdfs-site.xml]
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/centos/.ssh/id_rsa</value>
</property>8.fs.defaultFS
配置hdfs文件系统名称服务。
[core-site.xml]
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>9.dfs.journalnode.edits.dir
配置JN存放edit的本地路径。
[hdfs-site.xml]
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/centos/hadoop/journal</value>
</property>部署细节
1.在jn节点分别启动jn进程(s202,s203,s204)
$>hadoop-daemon.sh start journalnode2.启动jn之后,在两个NN之间进行disk元数据同步
a)如果是全新集群,先format文件系统,只需要在一个nn上执行。
[s201]
$>hadoop namenode -formatb)如果将非HA集群转换成HA集群,复制原NN的metadata到另一个nn.
1.步骤一
[s201]
$>scp -r /home/centos/hadoop/dfs centos@s206:/home/centos/hadoop/2.步骤二
在新的nn(未格式化的nn)上运行一下命令,实现待命状态引导。
[s206]
$>hdfs namenode -bootstrapStandby //需要s201为启动状态,提示是否格式化,选择N.3)在一个NN上执行以下命令,完成edit日志到jn节点的传输。
$>hdfs namenode -initializeSharedEdits
#查看s202,s203是否有edit数据.4)启动所有节点.
[s201]
$>hadoop-daemon.sh start namenode //启动名称节点
$>hadoop-daemons.sh start datanode //启动所有数据节点
[s206]
$>hadoop-daemon.sh start namenode //启动名称节点HA管理
$>hdfs haadmin -transitionToActive nn1 //切成激活态
$>hdfs haadmin -transitionToStandby nn1 //切成待命态
$>hdfs haadmin -transitionToActive --forceactive nn2//强行激活
$>hdfs haadmin -failover nn1 nn2 //模拟容灾演示,从nn1切换到nn2,只能手动容灾,不能自动容灾6.2 使用zk配置完全分布式集群,自动容灾
节点安排
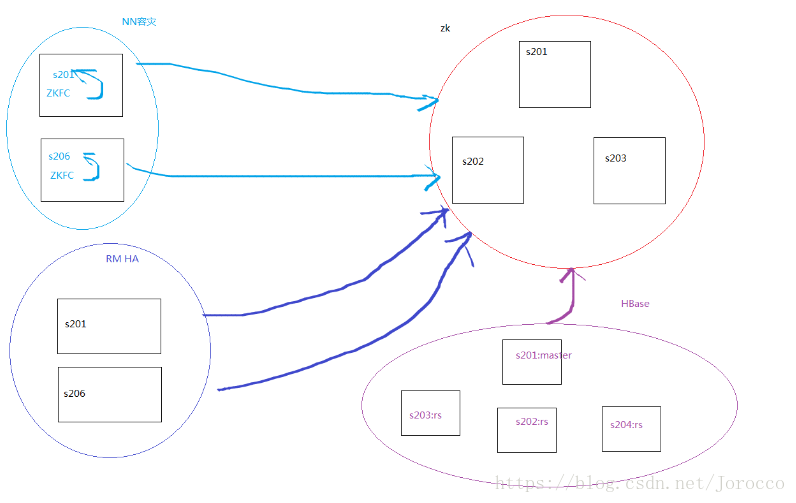
1.挑选3台主机
s201 ~ s203
2.每台机器都安装zk
tar
环境变量
3.配置zk配置文件
s201 ~ s203
[/soft/zk/conf/zoo.cfg]
...
dataDir=/home/centos/zookeeper
server.1=s201:2888:3888
server.2=s202:2888:3888
server.3=s203:2888:38884.在每台主机的/home/centos/zookeeper中添加myid,内容分别是1,2,3
[s201]
$>echo 1 > /home/centos/zookeeper/myid
[s202]
$>echo 2 > /home/centos/zookeeper/myid
[s203]
$>echo 3 > /home/centos/zookeeper/myid5.启动服务器集群
$>zkServer.sh start
...6.查看每台服务器的状态
$>zkServer.sh status7.修改zk的log目录
部署细节
在配置了上面的HA的前提下进行如下配置使得zk实现自动容灾:
1.停掉hadoop的所有进程
2.删除所有节点的日志和本地数据.
3.改换hadoop符号连接为ha,即切换到上面的HA模式下
4.登录每台JN节点主机,启动JN进程.
[s202-s204]
$>hadoop-daemon.sh start journalnode5.登录其中一个NN,格式化文件系统(s201)
$>hadoop namenode -format6.复制201目录的下nn的元数据到s206
$>scp -r ~/hadoop/* centos@s206:/home/centos/hadoop7.在未格式化的NN(s206)节点上做standby引导.
7.1)需要保证201的NN启动
$>hadoop-daemon.sh start namenode7.2)登录到s206节点,做standby引导.
$>hdfs namenode -bootstrapStandby7.3)登录201,将s201的edit日志初始化到JN节点。
$>hdfs namenode -initializeSharedEdits8.启动所有数据节点.
$>hadoop-daemons.sh start datanode9.登录到206,启动NN
$>hadoop-daemon.sh start namenode10.查看webui
http://s201:50070/
http://s206:50070/11.自动容灾
11.1)介绍
自动容灾引入两个组件,zk quarum + zk容灾控制器(ZKFC)。
运行NN的主机还要运行ZKFC进程,主要负责:
a.健康监控
b.session管理
c.选举
11.2)部署容灾
a.停止所有进程
$>stop-all.shb.配置hdfs-site.xml,启用自动容灾.
[hdfs-site.xml]
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>c.配置core-site.xml,指定zk的连接地址.
<property>
<name>ha.zookeeper.quorum</name>
<value>s201:2181,s202:2181,s203:2181</value>
</property>d.分发以上两个文件到所有节点。
12.登录其中的一台NN(s201),在ZK中初始化HA状态
$>hdfs zkfc -formatZK13.启动hdfs进程.
$>start-dfs.sh14.测试自动容在(206是活跃节点)
$>kill -96.3 配置RM的HA自动容灾
1.配置yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>s201</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>s206</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>s201:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>s206:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>s201:2181,s202:2181,s203:2181</value>
</property>2.使用管理命令
//查看状态
$>yarn rmadmin -getServiceState rm1
//切换状态到standby
$>yarn rmadmin -transitionToStandby rm13.启动yarn集群
$>start-yarn.sh4.hadoop配置了HA默认没有启动两个resourcemanager,需要手动启动另外一个
$>yarn-daemon.sh start resourcemanager5.查看webui
6.做容灾模拟.
kill -9