Docker内核知识
-
namespace资源隔离
namespace的6项隔离
NameSpace 系统调用参数 隔离内容
UTS CLONE_NEWUTS 主机名与域名
IPC CLONE_NEWIPC 信号量,消息队列,共享内存
PID CLONE_NEWPID 进程编号
Network CLONE_NEWNET 网络设备,网络栈,端口路由等
Mount CLONE_NEWNS 文件系统
User CLONE_NEWUSER 用户和用户组(权限等)
Linux内核实现namespace的一个主要目的是为了实现轻量级的虚拟化(容器)服务
NetWork网络隔离:
一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable规则等都与其他的Network Namespace隔离。一个Docker容器“通常”会分配一个独立的NetworkNamespace。
经典做法就是,创建一个veth pair,他是成对出现的,一个放在新建的namespace中,通常命名为eth0(容器的网卡),一个放在原来的namespace中(宿主机,以veth开头),连接物理设备的网卡(docker0网桥),在通过多个设备接入网桥或者路由转发实现通信目的
namespace API操作的4种方式
- 通过clone()在创建新进程的同时创建namespace
使用clone()命令来创建一个独立的namespace进程
- 通过查看/proc/[pid]/ns文件,可以查看到指向不同namespace号的文件
[root@bogon ~]# ll /proc/11700/ns total 0 lrwxrwxrwx 1 elasticsearch elasticsearch 0 Jul 2 11:03 ipc -> ipc:[4026531839] lrwxrwxrwx 1 elasticsearch elasticsearch 0 Jul 2 11:03 mnt -> mnt:[4026531840] lrwxrwxrwx 1 elasticsearch elasticsearch 0 Jul 2 11:03 net -> net:[4026531956] lrwxrwxrwx 1 elasticsearch elasticsearch 0 Jul 2 11:03 pid -> pid:[4026531836] lrwxrwxrwx 1 elasticsearch elasticsearch 0 Jul 2 11:03 user -> user:[4026531837] lrwxrwxrwx 1 elasticsearch elasticsearch 0 Jul 2 11:03 uts -> uts:[4026531838]
- 通过setns()加入一个已经存在的namespace
- 通过unshare()在原先进程上进行namespae隔离
unshare运行在一个新的进程上,不需要启动一个新进程,
调用unshare的主要作用就是不启动新进程就可以起到隔离的效果,相当于跳出原来的namespace进行操作
-
cgroups资源限制分配
cgroups是Linux内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分割)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架,所有资源管理的功能都以子系统的方式实现,接口统一
本质上来说,cgroups是内核附加在程序上的一系列钩子(hook),通过程序运行时对资源的调度触发相应的钩子达到资源追踪和限制的目的
cgroups可以限制、记录任务组所使用的物理资源(cpu,memory,io等),主要作用:
- 资源限制:对任务使用的资源总额进行限制
- 优先级分配:控制任务运行的优先级
- 资源统计:统计系统资源的使用量
- 任务控制:对任务执行挂起、恢复等操作
子系统:cgroups的资源控制系统(资源调度控制器),每种子系统单独的控制一种资源(比如CPU子系统可以控制CPU时间分配,内存子系统可以控制cgroup的内存使用量)
cgroup:控制组,cgroup表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统,一个任务(系统的一个进程或线程)可以加入某个cgroup,也可以迁移到另外一个cgroup,linux中cgroup的表现形式为文件系统,因此需要mount这个文件系统才能使用
在docker实现中,docker daemon会在单独挂载了每一个子系统的控制组目录(比如/sys/fs/cgroup/{cpu,cpuacct,cpuacct,memory})创建一个名为docker的控制组,然后在docker控制组里,再为每个容器创建一个以容器ID为名称的控制组,这个容器里所有进程的进程号都会写到该控制组tasks中,并且在控制文件中写入预设的限制参数值
示例(一个cgroup)
[root@bogon docker]# pwd /sys/fs/cgroup/cpu/docker [root@bogon docker]# ll total 0 -rw-r--r-- 1 root root 0 Feb 6 10:15 cgroup.clone_children --w--w--w- 1 root root 0 Feb 6 10:15 cgroup.event_control -rw-r--r-- 1 root root 0 Feb 6 10:15 cgroup.procs -r--r--r-- 1 root root 0 Feb 6 10:15 cpuacct.stat -rw-r--r-- 1 root root 0 Feb 6 10:15 cpuacct.usage -r--r--r-- 1 root root 0 Feb 6 10:15 cpuacct.usage_percpu -rw-r--r-- 1 root root 0 Feb 6 10:15 cpu.cfs_period_us -rw-r--r-- 1 root root 0 Feb 6 10:15 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 Feb 6 10:15 cpu.rt_period_us -rw-r--r-- 1 root root 0 Feb 6 10:15 cpu.rt_runtime_us -rw-r--r-- 1 root root 0 Feb 6 10:15 cpu.shares -r--r--r-- 1 root root 0 Feb 6 10:15 cpu.stat drwxr-xr-x 2 root root 0 Jul 2 14:31 ff5681b9a060af6b939c7696c8d8990d88cd4290c1593134bd6bc781f4576d1f #容器id -rw-r--r-- 1 root root 0 Feb 6 10:15 notify_on_release -rw-r--r-- 1 root root 0 Feb 6 10:15 tasks
容器控制组
[root@bogon docker]# cd ff5681b9a060af6b939c7696c8d8990d88cd4290c1593134bd6bc781f4576d1f/ [root@bogon ff5681b9a060af6b939c7696c8d8990d88cd4290c1593134bd6bc781f4576d1f]# ls cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
一个cgroup创建完成,不管绑定了那种子系统,其目录都会生成以下文件(全部文件看上面):
tasks:列出了所有在该cgroup的任务tid,即所有进程或线程的id
cgroups.procs:列出线程组id,即线程组中第一个进程的pid
notify_on_release: 0或1,默认为0,表示不运行,表示是否在cgroup中最后一个任务退出时通知运行release agent
release_agent:执行 release agent执行脚本的文件路径
Docker架构概览
docker使用传统的c/s架构,用户通过docker-client与docker daemon建立通信
docker通过driver实现对Docker容器执行环境的创建和管理,libcontainer是对cgroups和namespace的二次封装,execdriver是通过libcontainer来实现对容器的具体管理,包括 namespace资源隔离和cgroups实现对容器的资源限制
docker命令执行流程
- client执行模式
docker对应的命令源文件为docker.go,使用方式如下
docker [options] command [arg...]
options参数称为flag,任何时候执行一个docker命令,都要先解析flag,步骤如下
①、解析flag Debug:对应 -D和--debug参数,用于显示日志为debug模式,用于启动调试模式 LogLevel:对应-l和--log-level参数,默认级别为info,即输出普通的操作信息 Hosts:对应-H和--host-[]参数,对于client模式,指本次操作所需要连接的Docker daemon位置,对于daemon模式,则提供所要监听的地址, protoAddrParts:与docker daemon建立通信协议方式与socket地址 ②、创建client示例 调用 api/cli.go ③、执行具体命令 交给cli.go执行,
- daemon执行模式
docker命令创建一个运行在宿主机的daemon进程(docker/daemon.go),其余自命令执行client模式


daemon创建对象与初始化流程
docker容器配置信息 检测系统支持及用户权限 配置daemon工作路径 配置docker容器所需的文件环境 创建容器配置文件目录 配置graphdriver目录(用于完成docker容器镜像管理所需的底层存储驱动层) 配置镜像目录 创建volume工作目录(调用/volume/local/local.go) 准备可信镜像工作目录 持久化在docker根目录中的镜像 执行镜像迁移 创建docker daemon网络 初始化execdriver(用来管理docker容器的驱动) daemon对象诞生 恢复已有的docker容器
docker与容器间的通信方式
发送信号通知(single)
对内轮询访问(poll memory)
socket 通信(sockets)
文件和文件描述符(管道)
容器是一个与宿主机系统共享内核但与系统中的其他进程资源相隔离的执行环境,Docker通过对namespace、cgroups、capabilities以及文件系统的管理和分配来隔离出一个执行环境
docker镜像
Docker镜像只是一个可读Docker容器模板,含有启动Docker容器所需的文件系统结构及其内容
一、rootfs
rootfs是docker容器启动时内部进程可见的文件系统,即docker容器的根目录,rootfs通常包含一个操作系统运行所需要的文件系统(/dev/、/proc 、/etc、/bin、/lib、/usr ..)等
二、主要特点
分层
docker‘镜像采用分层方式构建,每个镜像由一系列镜像层组成,分层结构是镜像如此轻量的重要原因,修改镜像内的某个文件时,支队处于最上方的读写层进行变动,不修改原有的文件系统,只是将原有的版本隐藏,通过commit后才会成为一个新的镜像时,修改的才会保存
写时复制
写时复制策略,在多个容器间共享镜像,每个容器启动的时候并不需要单独复制一份镜像文件,而是将所有镜像层以只读的方式挂载到一个挂载点,再在上面覆盖一个可读写的容器层,只有在docker容器运行中文件系统发生改变时,才会吧镜像的文件内容写到读写层,并隐藏只读层的老版本文件
内容寻址
根据文件内容来索引镜像和镜像层,该机制提高了镜像的安全性,并在 push、pull、load和save后检测数据的完整性
联合挂载
可以在一个挂载点同事挂载多个文件系统,将挂载的目录与挂载内容进行整合
docker镜像构建操作
commit镜像
①、根据用户输入pause参数的设置确定是否暂停该docker容器的运行
②、将容器的可读写层导出打包,该读写层代表了容器的原始文件系统和现在文件系统的差异
③、在层存储中注册可读写层差异包
④、更新镜像历史信息和rootfs,并据此在镜像存储中创建一个新的镜像
⑤、如果制定了 repository信息,在给镜像添加tag信息
注:regsirty是repository的集合,repository是image的集合,repository包含了一个镜像的众多版本
docker网络基础
docker daemon 通过调用libnetwork对外提供的API完成网络的创建和管理等功能。libnetwork则使用了CNM(container network model)完成网络功能的提供
CNM三种核心组件
- 沙盒:sandbox 包含了容器网络栈的信息,可以对容器的接口路由和dns设置进行管理
- 端点:endpoint 端点可以加入沙盒的网络,端点的实现可以是 veth pair,open vswitch内部端口或相似设备
- 网络:network 网络的实现可以是 linux bridge vlan
libnetwork 5中内置驱动
bridge驱动: 默认的内置驱动,libnetwork将创建的容器连接到docker网桥,外界通信使用NAT,
host驱动: 使用host默认不会创建网络协议栈,docker容器中的进程处于宿主机的网络环境中,相当于docker容器和宿主机共用一个
network namespace,但是容器其他方面是隔离的
overlay驱动: 采用标准的vxlan方式,被普遍认为是最适合云计算虚拟化环境的sdn controller模式
remote驱动
null驱动: 使用这种驱动,docker有自己的network namespace,但是并不为docker容器进行任何网络设置,即除了自带的loopback网卡,没有其余的任何网卡
libnetwork 搭建示例,验证容器连通性
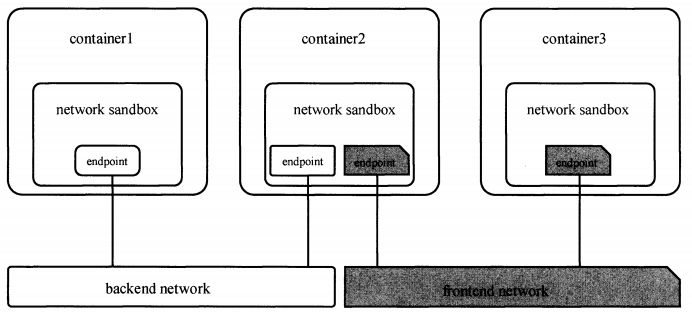
创建两个网络
[root@bogon ~]# docker network create backend 1b95e147087b21dad43054223a19e315ee961abd32078b180abf09b05c60f42a
[root@bogon ~]# docker network create frontend b694f497378b72e07416f5245d58d279826b2957405917bcb0db40c1cde10c07
[root@bogon ~]# docker network ls NETWORK ID NAME DRIVER SCOPE 1b95e147087b backend bridge local 5b39784857a0 bridge bridge local b694f497378b frontend bridge local 3382ad8a0f31 harbor_harbor bridge local 271c8285e986 host host local 2aa41f414565 none null local
启动三个容器并连接到相应的网络(看上图)
[root@bogon ~]# docker run -it -d --name container1 --net backend tomcat aa5cf430fc50b46b8098c0d18b1d3c2f00cd33bc26165950583b6e926a8e632f
[root@bogon ~]# docker run -it -d --name container2 --net backend tomcat b3ec85f7051c20063fe4c0174c35d91d77aae290d0dad41e7b35ac9ab0b3d660
[root@bogon ~]# docker run -it -d --name container3 --net frontend tomcat 3b7ef4fd7de1c23c242aecb8b688da5540d7b35bfdcded1b8c13528992ed0269
[root@bogon ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3b7ef4fd7de1 tomcat "catalina.sh run" 7 seconds ago Up 6 seconds 8080/tcp container3 b3ec85f7051c tomcat "catalina.sh run" 16 seconds ago Up 14 seconds 8080/tcp container2 aa5cf430fc50 tomcat "catalina.sh run" 37 seconds ago Up 35 seconds 8080/tcp container1
登录container1和container3 测试与container2的连通性,发现1和2 通,2和3不通
[root@bogon ~]# docker exec -it aa5cf430fc50 /bin/bash
将container2 加入到 frontend网络中
[root@bogon ~]# docker network connect frontend container2
ip addr 发现container2 容器有两张网卡了,再次ping测试
[root@bogon ~]# docker exec -it b3ec85f7051c /bin/bash root@b3ec85f7051c:/usr/local/tomcat# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 1603: eth0@if1604: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:14:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.20.0.3/16 scope global eth0 valid_lft forever preferred_lft forever 1609: eth1@if1610: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:15:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.21.0.3/16 scope global eth1 valid_lft forever preferred_lft forever
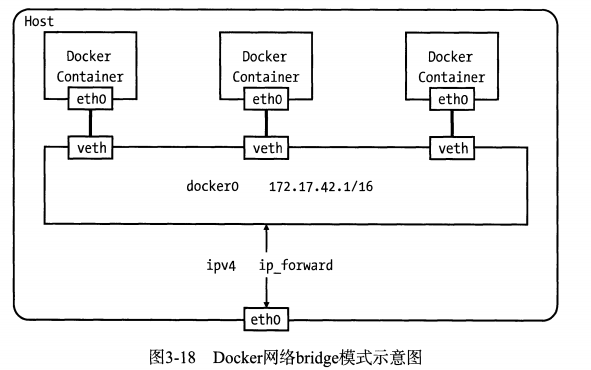
bridge驱动实现机制
- docker0网桥
- route -n 可查看路由信息(宿主机和容器的路由信息均指向docker0网桥,通过veth pair来连接两个network namespace)
- brctl show 可查看网桥信息
- 添加一个自定义网桥,并配置ip
- brctl addbr br0
- ifconfig br0 192.168.10.1
- 启动docker daemon的时候 使用 --bridge=br0即可,此参数与--bip参数同时使用会冲突
- iptables规则
- docker安装完成后,默认会在宿主机上增加一些iptables规则,以用于dokcer容器和容器之间以及和外界的通信,使用iptables-save查看
- docker与外界通讯,需要linux内核开启数据转发功能(ip_forward=1)
- docker容器的dns和主机名
- -h HOSTNAME or --hostname=HOSTNAME 设定容器的主机名,它会被写到/etc/hostname,/etc/hosts文件中,也会在容器的bash提示符中看到,但是在外部无法查看
- --dns=IP_ADDRESS 添加dns服务器到容器的/etc/resolv.conf中,让容器用这ip地址来解析所有不在/etc/hosts中的主 机名。
未完。。