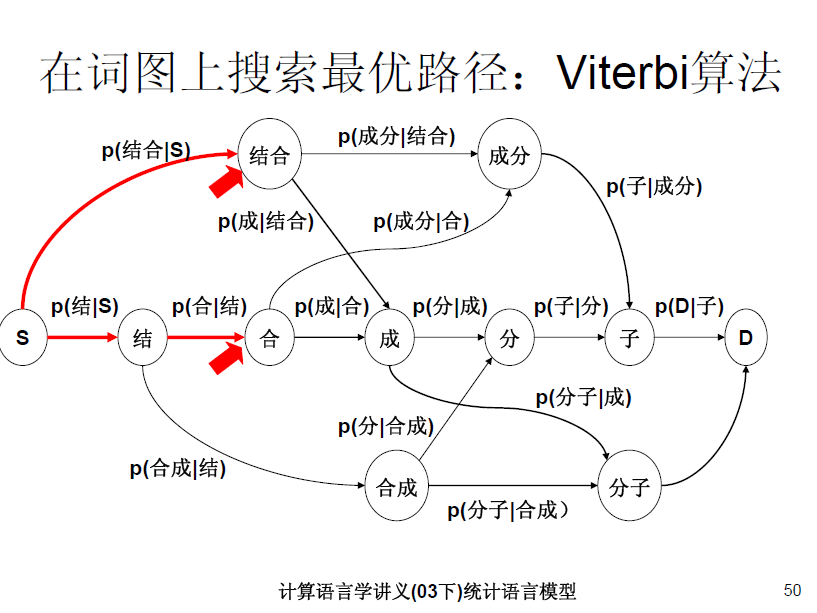
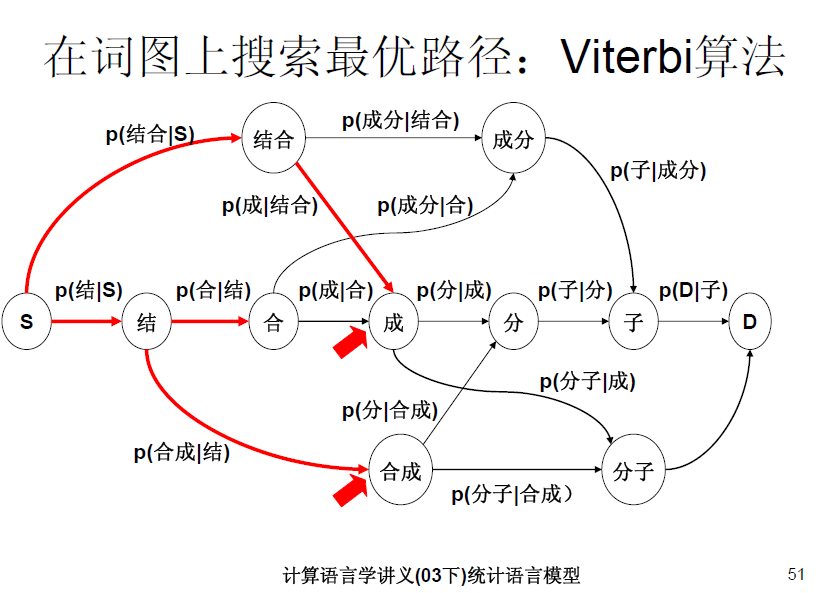
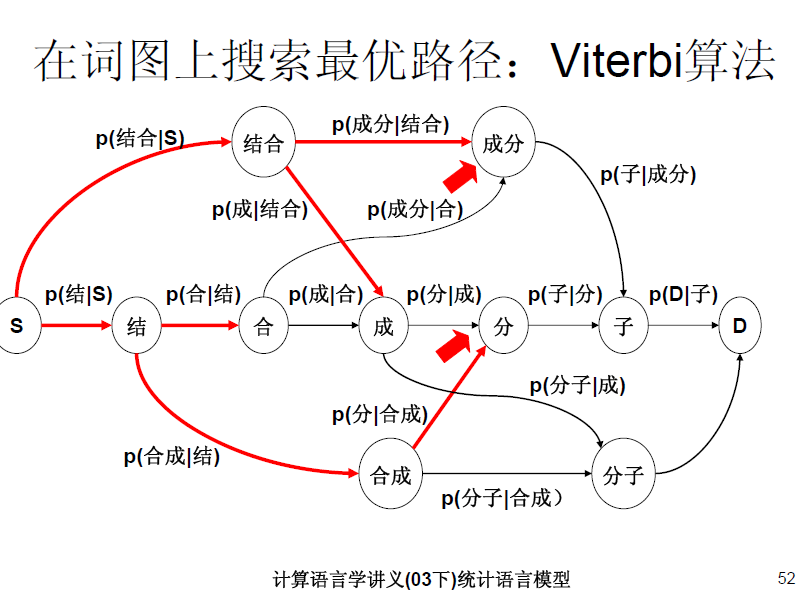
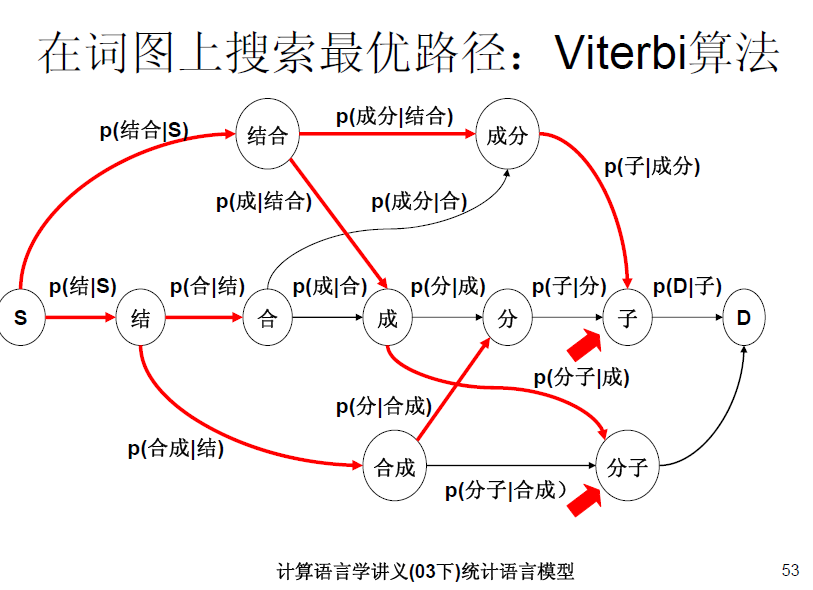
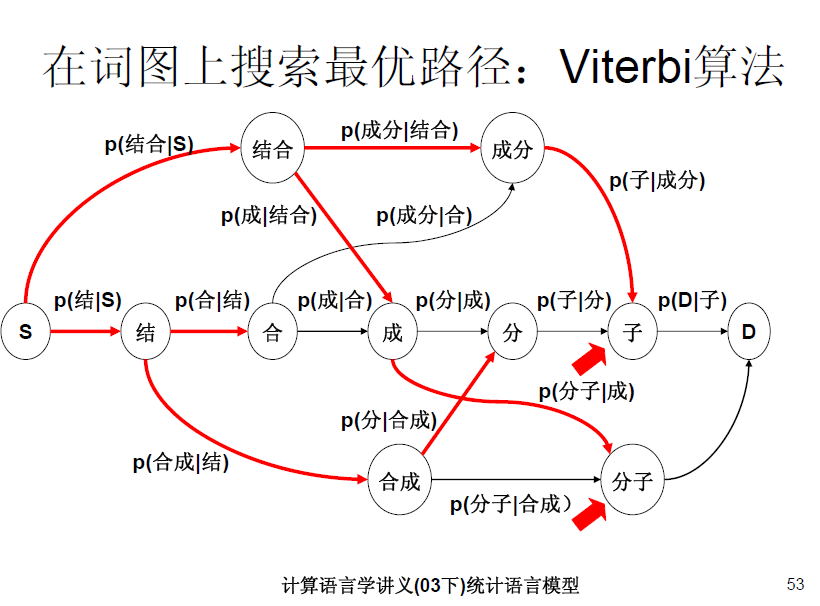
二元语法模型也就是一阶马尔科夫链,更通俗的说法是:一个词出现与否,仅有它前面一个词有关。举个例子
:P(成|结合)*P(结合)>P(合成|结) *P(结)表示 “结合成”分词为 “结合 成”的概率要大于分词为“结 合成”的概率。这也是和一元语法模型的不同之处。对于一元语法模型“结合成”的分词结合要看 P(结)*P(合)*P(成), P(结合)*P(成),P(结)*P(合成)谁大。对比一元语法模型和二元语法模型,我们能够看出,二元语法模型优于一元语法模型,因为它考虑了上下文相关性,同理,三元语法模型优于二元语法模型。
2. 什么是Viterbi算法。Veterbi算法是动态规划算法中的一种,常用在隐式马尔科夫模型求最优路径中。
我们首先要阐明动态规划算法的结构:
子结构最优,子问题交叠。也就是说一:1个问题的最优解是由最优的子问题的最优解构成;2求解此问题最优解的方法过程,对于求解子问题也适用,也就是可递归性。
如果大家想对一元语法模型,和veterbi算法,有更深入的了解,可以参考以下两篇博文:一元语法模型,Viterbi算法

基于二元语法模型分词的思想
下面是该程序的主要过程与思路:
1、针对语料库进行训练。
本程序使用的是北大提供的人民日报1998 年1 月的语料库,包含约110万词。由于采用二元语法模型,所以需要计算语料库中单个词的频率,以及每一个词后面出现另一个词的频率。
2、建立二元切分词图。
建立一个有向无环图,图中的结点为任意一个可能的候选词语,图中的边代表相邻两个词语的续接关系。二元切分词图的每一条边的权值表示二元词语转移概率P(Wi|Wi-1)。 任何一种切分的方式可以表示为二元切分词图上的一条起始结点到结束结点的路径。路径上所有边的概率之积就是该切分结果对应的二元语法模型概率。而我们要做的就是找出一条概率之积最大的路径。
3、对一个句子进行全切分。
在对句子进行切分时要按照词图的拓扑序,即从句首到句尾,每一个汉字表征一个hierarchy. 将词图中的词归类到各个hierarchy。 比如句子为“对一个句子进行全切分”。则词图中以“对”字结尾的词归到hierarchy0,以“一”字结尾的词归到hierarchy1……以此类推。
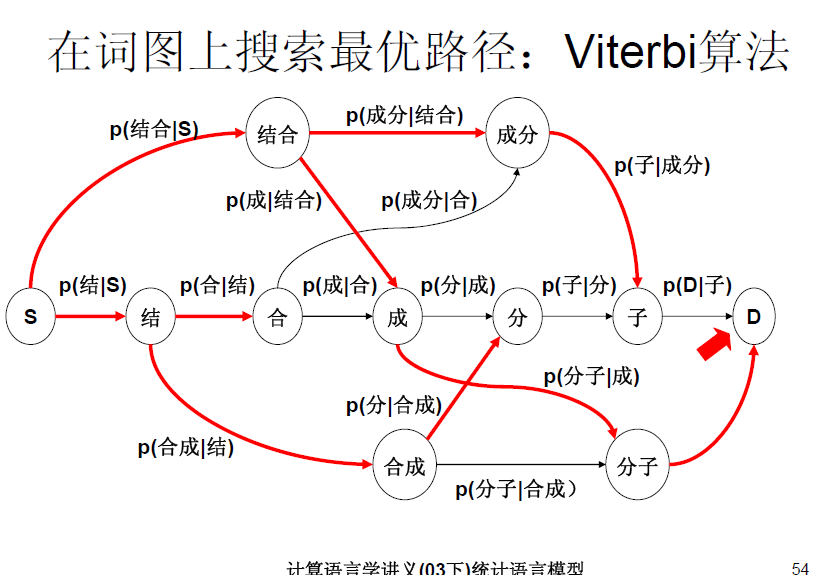
4、Viterbi算法求最优路径。
Viterbi算法是一种动态规划的算法。一个问题能够用动态规划来求解,它必须能够满足以下两个条件:最优子结构和重叠子问题。也就是说,一个问题的最优解是由子问题的最优解构成,而求解此问题最优解的方法过程,对于求解子问题也适用,也就是可递归性。
程序中,用变量optimalCandidates表示每个hierarchy上的最优解。
再用上面的句子举例。“对一个句子进行全切分”。对于“子”字,属于hierachy4,它的最优解可以由 optimalCandidates[0], optimalCandidates[1], optimalCandidates[2], optimalCandidates[3],中的解来生成。对属于每个hierarchy的词,按照它的长度,找到它的上一个hierarchy。例如上面例子中的“子”字所属的hierarchy中有一个词是“句子”。那么这个词就回溯到hierachy2,看看P(句子|optimalCandates[2])的概率值。假设 “子”字hierarchy还有一个词是“个句子”这个词可以回溯到hierachy1。
求得概率最大的最优值之后,再从最后一个hierarchy回溯遍历一遍,便能获得最优解,即一种概率最大的切分方式。
例子: