说明:这两天无新课,主要是扩充知识面
注意:这两天的任务,需要回专贴。需要你们通过看这些东西总结成自己的心得。 不能照搬,必须要自己理解,能看多少就看多少,看不完也没有关系,但一定要去理解。
不停库不锁表在线主从配置 http://seanlook.com/2015/12/14/mysql-replicas/
mysql主从常见问题 http://www.10tiao.com/html/706/201603/403220961/1.html
mysql主从延迟 http://f.dataguru.cn/thread-461916-1-1.html
深入探究主从延迟 http://ningg.top/inside-mysql-master-slave-delay/
mysql主从不同步如何做 http://www.jb51.net/article/33052.htm
mysql 主主 http://www.cnblogs.com/ygqygq2/p/6045279.html
mysql-proxy 实现读写分离 http://my.oschina.net/barter/blog/93354
mycat实现读写分离 http://www.th7.cn/db/mysql/201708/250280.shtml
atlas相关 http://www.oschina.net/p/atlas
mysql一主多从 http://blog.sina.com.cn/s/blog_4c197d4201017qjs.html
mysql环形主从 http://ask.apelearn.com/question/11437
cobar实现分库分表 http://blog.csdn.net/huoyunshen88/article/details/37927553
mysql分库分表方案 http://my.oschina.net/ydsakyclguozi/blog/199498
mysql架构演变 http://www.aminglinux.com/bbs/thread-8025-1-1.html
fMHA架构 http://www.dataguru.cn/thread-457284-1-1.html
比较复杂的mysql集群架构 http://ask.apelearn.com/question/17026
使用 Xtrabackup 在线对MySQL做主从复制
2.2版本 xtrabackup 能对InnoDB和XtraDB存储引擎的数据库非阻塞地备份,innobackupex通过perl封装了一层xtrabackup,对MyISAM的备份通过加表读锁的方式实现。2.3版本 xtrabackup 命令直接支持MyISAM引擎。
XtraBackup优势 :
- 无需停止数据库进行InnoDB热备
- 增量备份MySQL
- 流压缩到传输到其它服务器
- 能比较容易地创建主从同步
- 备份MySQL时不会增大服务器负载
为什么要做主从复制?
我想这是要在实施以前要想清楚的问题。是为了实现读写分离,减轻主库负载或数据分析? 为了数据安全,做备份恢复?主从切换做高可用?
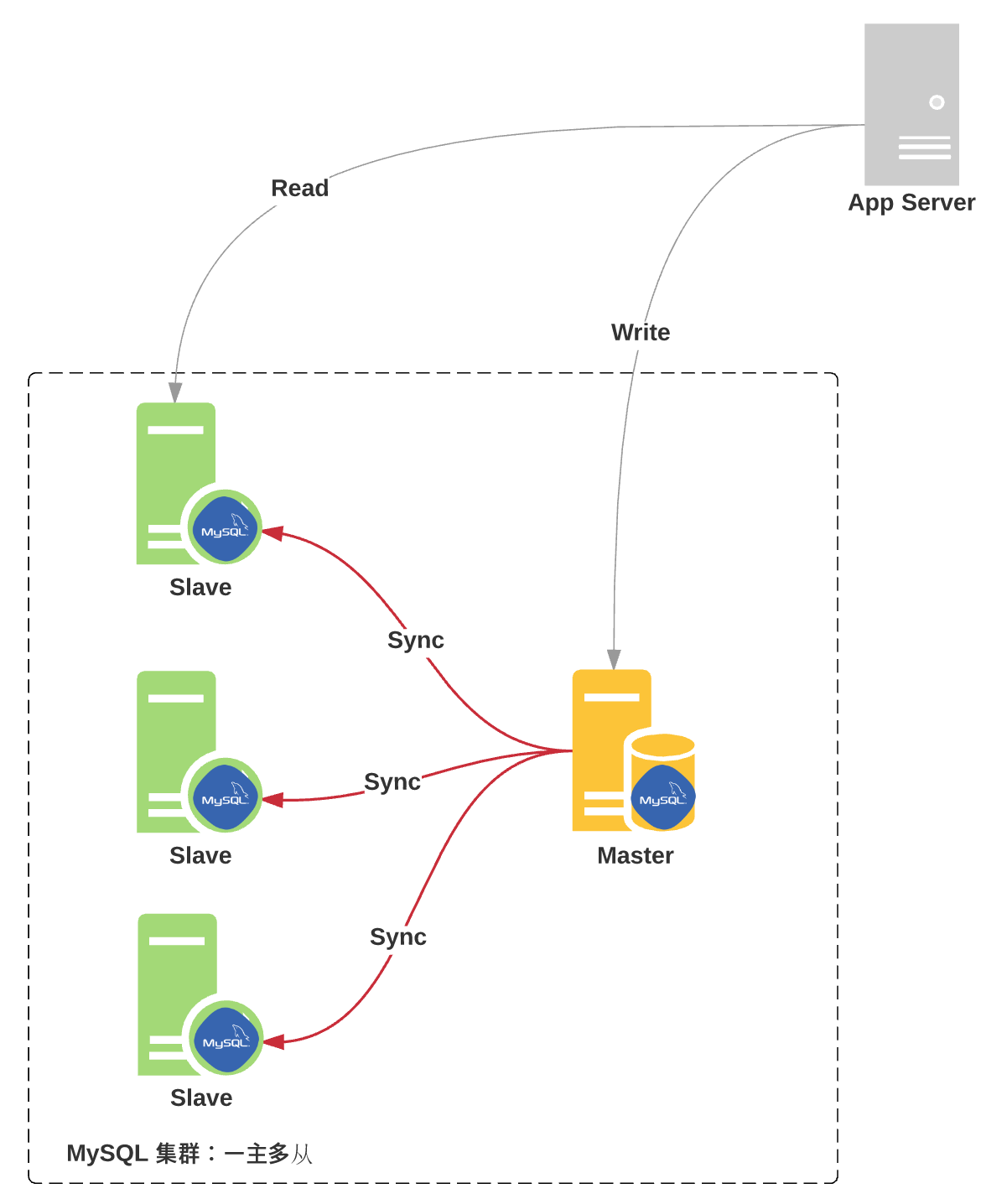
大部分场景下,以上三个问号一主一从都能够解决,而且任何生产环境都建议你至少要有一个从库,假如你的读操作压力特别大,甚至要做一主多从,还可以不同的slave扮演不同的角色,例如使用不同的索引,或者不同的存储引擎,或使用一个小内存server做slave只用于备份。(当然slave太多也会对master的负载和网络带宽造成压力,此时可以考虑级联复制,即 A->B->C )
还有需要考虑的是,一主一从,一旦做了主从切换,不通过其它HA手段干预的话,业务访问的还是原IP,而且原主库很容易就作废了。于是 主-主 复制就产生了,凭借各自不同的 server-id ,可以避免 “A的变化同步到B,B应用变化又同步到A” 这样循环复制的问题。但建议是,主主复制,其中一个主库强制设置为只读,主从切换后架构依然是可用的。
复制过程是slave主动向master拉取,而不是master去推的,所以理想情况下做搭建主从时不需要master做出任何改变甚至停服,slave失败也不影响主库。
- 原理
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。

- 该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二进制日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
- 下一步将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,请求从指定日志文件的指定位置之后的日志内容,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
-
SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
补充:
- mysql 5.7开始加入了多源复制,这个特性对同时有很多个mysql实例是很有用的,阿里云RDS(迁移)实现了类似的方式。
- 从MySQL 5.6.2开始,mysql binlog支持checksum校验,并且5.6.6默认启用(CRC32),这对自己模拟实现mysql复制的场景有影响。
下面开始配置主从:
主从版本一致—>主库授权复制帐号—>确保开启binlog及主从server_id唯一—>xtrabackup恢复到从库—>记录xtrabackup_binlog_info中binlog名称及偏移量—>从库change master to —>slave start—>检查两个yes
主从复制概述
主从复制是Mysql内建的复制功能,它是构建高性能应用程序的基础,技术成熟,应用也很广泛。其原理就是通过将Mysql主库的sql语句复制到从库上,并重新执行一遍来实现的。复制过程中主库将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从库的更新。每次从库连接主库时,它会通知主库最后一次成功更新的位置。从库接收从那时起发生的任何更新。在进行主从复制时,所有命令都必须在主库上进行,从库不做操作。否则,会引起主从库之间的数据不同步,复制会中断。
1. 背景
用户画像功能上线后,线上 MySQL 监控显示
主从延迟现象严重:平均 6s 左右,需要剖析一下原因,找到改进的措施。
当前 blog 要解决的问题:
- 监控:MySQL 的主从延迟?
- 影响:
- MySQL 主从延迟的影响?
- 多少的延迟,可以接受?
- 原因:MySQL 主从延迟的产生原因?
2. MySQL 主从复制
2.1. 作用
原点之问:MySQL 主从集群的作用,要解决什么问题?
场景:
高并发情况下,单台 MySQL 数据库承载的连接数多、读写压力大,MySQL系统瓶颈凸显- 大部分互联网场景,数据模型「
一写多读」- 读次数(
read_num) 一般是写次数(write_num)的 10 倍以上 - 补充:数据分析、商业智能等场景,
read_num和write_num基本相当,同一量级
- 读次数(
MySQL 集群方式,能够分散单个节点的访问压力。
MySQL 集群,常见方式:主从集群
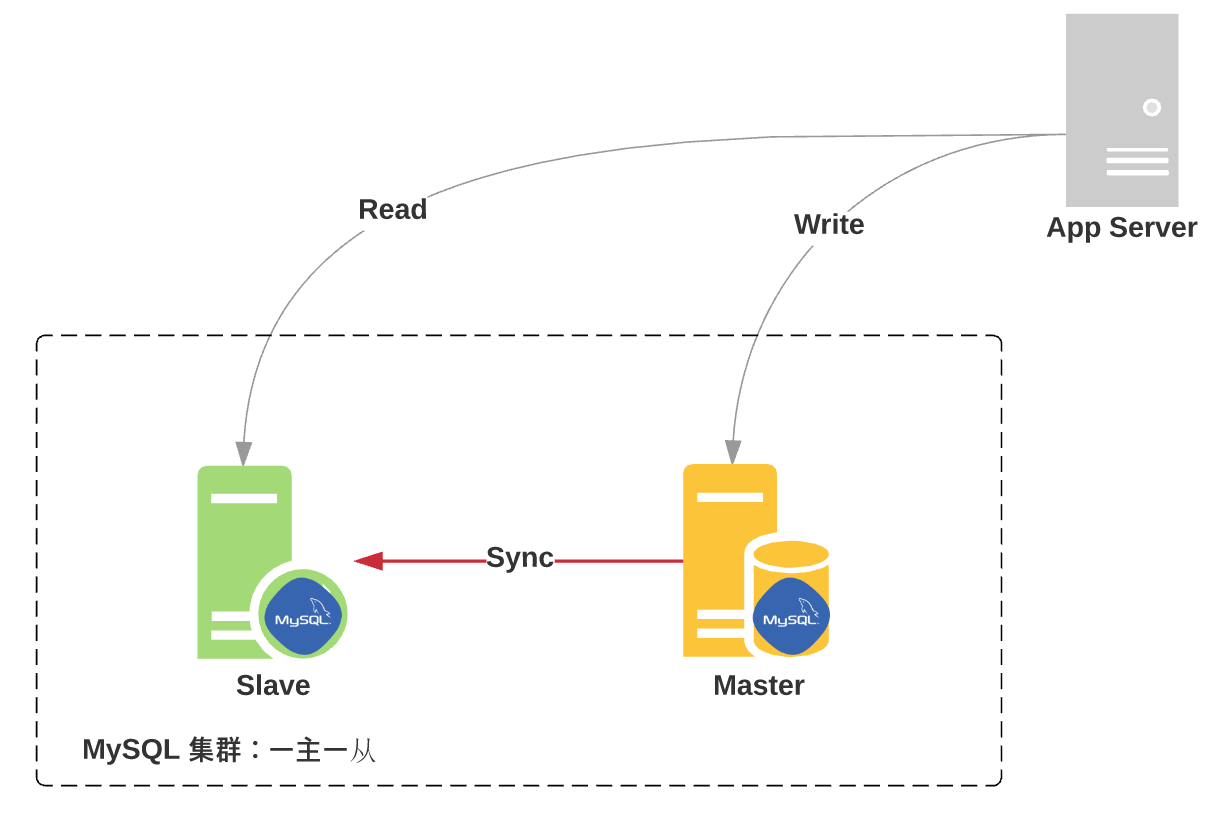
- Master 节点,负责所有的「写请求」
- Slave 节点,负责大部分的「读请求」
MySQL 主从集群的作用:
MySQL 主从集群,分散访问压力,提升整个系统的可用性,降低大访问量引发的故障率。
常见的主从架构:
- 一主一从:一个 Master,一个 Slave
- 一主多从:一个 Master,多个 Slave
具体,参考下图:
2.2. 实现细节
MySQL 在主从同步时,其底层实现细节又是什么?为此后分析主从延迟原因以及优化方案,做好理论准备。
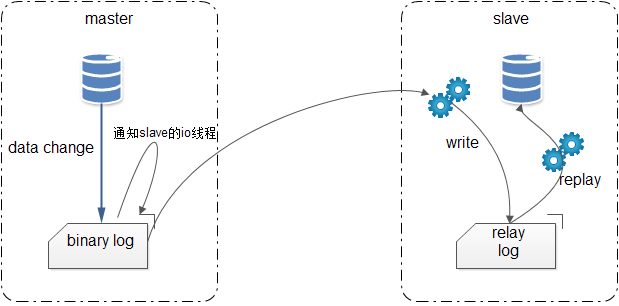
总结来说,MySQL 的主从复制:异步单线程。
Master上 1 个IO线程,负责向Slave传输binary log(binlog)Slave上 2 个线程:IO 线程和执行SQL的线程,其中:IO线程:将获取的日志信息,追加到relay log上;执行SQL的线程:检测到relay log中内容有更新,则在Slave上执行sql;
特别说明:MySQL 5.6.3 开始支持「
多线程的主从复制」,一个数据库一个线程,多个数据库可多个线程。
完整的 Master & Slave 之间主从复制过程:
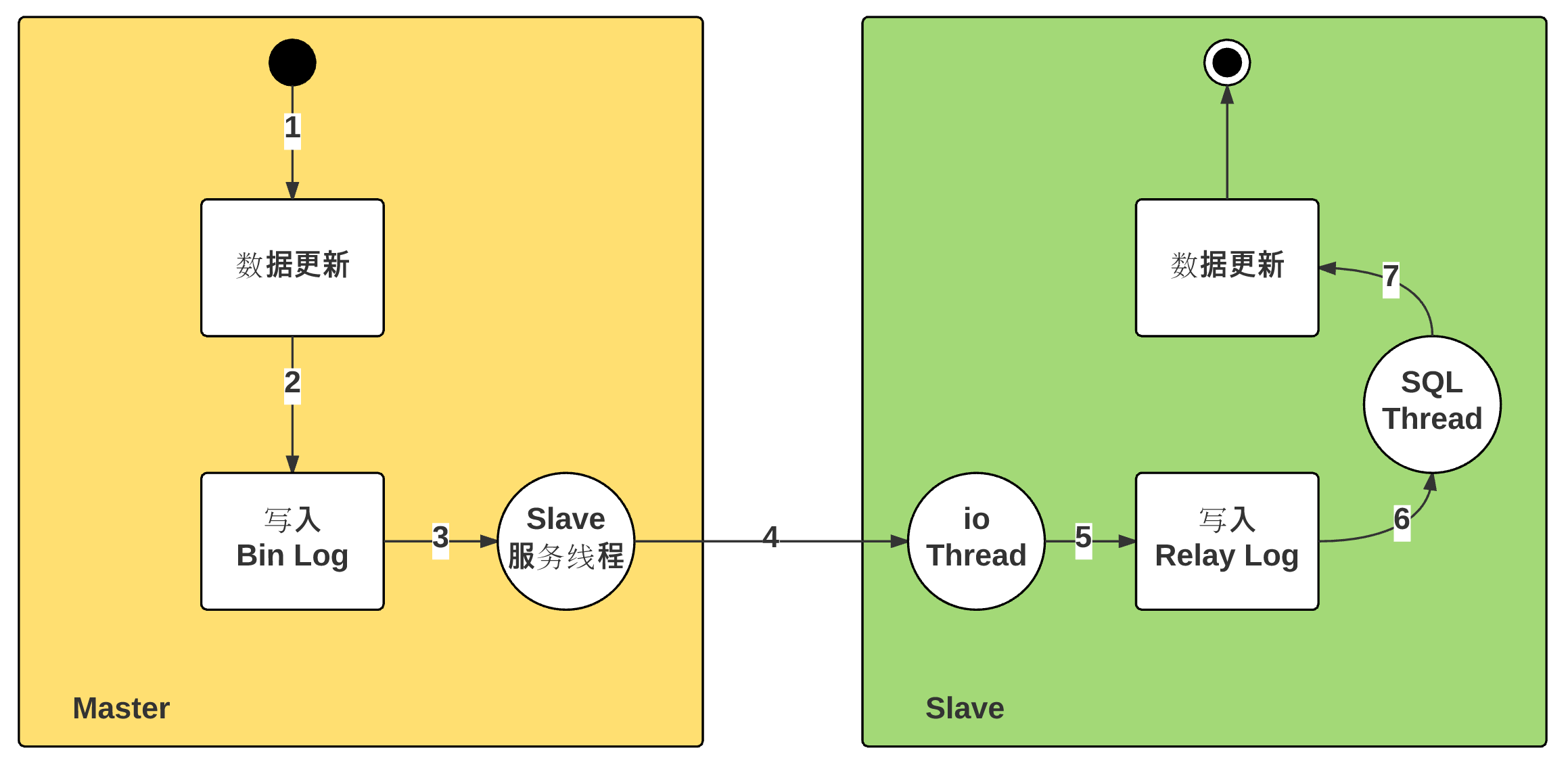
主从延时时间:Master 执行成功,到 Slave 执行成功,时间差。
上述过程:
- 主从延迟:「步骤2」开始,到「步骤7」执行结束。
- 步骤 2:存储引擎处理,时间极短
- 步骤 3:文件更新通知,磁盘读取延迟
- 步骤 4:Bin Log 文件更新的传输延迟,单线程
- 步骤 5:磁盘写入延迟
- 步骤 6:文件更新通知,磁盘读取延迟
- 步骤 7:SQL 执行时长
通过上面分析,MySQL 主从复制是典型的生产者-消费者模型:整体耗时,分为几类
- 磁盘的读写耗时:步骤 3、步骤 5、步骤6
- 网络传输耗时:步骤 4
- SQL 执行耗时:步骤 7 (地点:Slave 上 relay log 执行过程)
- 排队耗时:步骤 3(地点:Master 上 bin log 中排队,生产者-消费者)