经过前面复杂的操作,训练出来对于某一个人的识别模型。本文将利用该模型对于打开的视频或者摄像头实时的识别该人。
读取视频 ==> 识别人脸 ==> 绘制标志
代码如下:
#-*- coding:UTF-8 -*-
import tensorflow as tf
import numpy as np
import sys
import gc
from face_train import Model
import cv2
def IdentifyFace(window_name):
cv2.namedWindow(window_name)
model = Model()
model.load_model(file_path = 'face.model.h5')
cap = cv2.VideoCapture("test.wmv") #获取视频数据
classifier=cv2.CascadeClassifier('/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_alt2.xml')
color=(0,255,0)
num = 0
while cap.isOpened():
ok,frame = cap.read() #ok表示返回的状态 frame存储着图像数据矩阵 mat类型的
if not ok:
break
#图像灰度化
grey=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#加载分类器 opencv自带
faceRects = classifier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0 :
for faceRect in faceRects:
x,y,w,h = faceRect
image = frame[y-10:y+h+10,x-10:x+w+10]
faceID = model.face_predict(image)
#如果是“我”
if faceID == 0:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
#文字提示是谁
cv2.putText(frame,'ME',
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
1, #字号
(255,0,255), #颜色
2) #字的线宽
else:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
#文字提示是谁
cv2.putText(frame,'others',
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
1, #字号
(255,0,255), #颜色
2)
cv2.imshow(window_name,frame) #将捕获的数据显示出来
c = cv2.waitKey(30)
if c & 0xff == ord('q'): #按q退出
break
cap.release()
cv2.destroyWindow(window_name)
#主程序调用方法运行
if __name__ == '__main__':
IdentifyFace('IdentifyFace')通过加载opencv自带的分类器 classifier.detectMultiScale 来识别出人脸
通过model.face_predict(image)来判断该人脸是否是我们寻找的目标
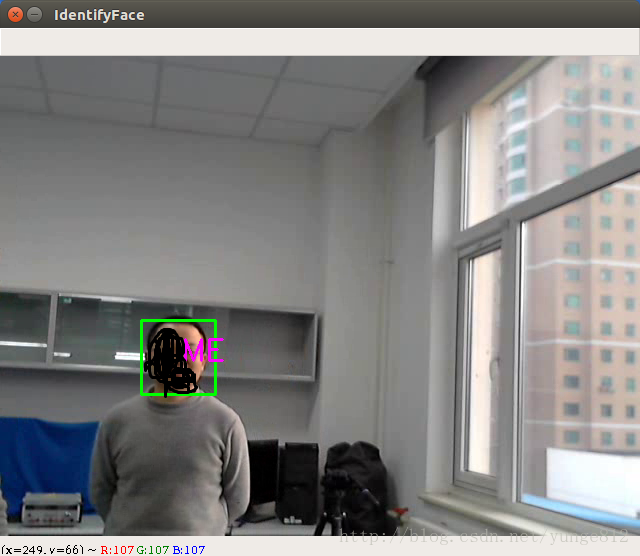
效果如图所示:
整个完整工程的源码下载地址:
http://download.csdn.net/download/yunge812/10270064