爬取的页面为https://book.qidian.com/info/1010734492#Catalog
爬取的小说为凡人修仙之仙界篇,这边小说很不错。
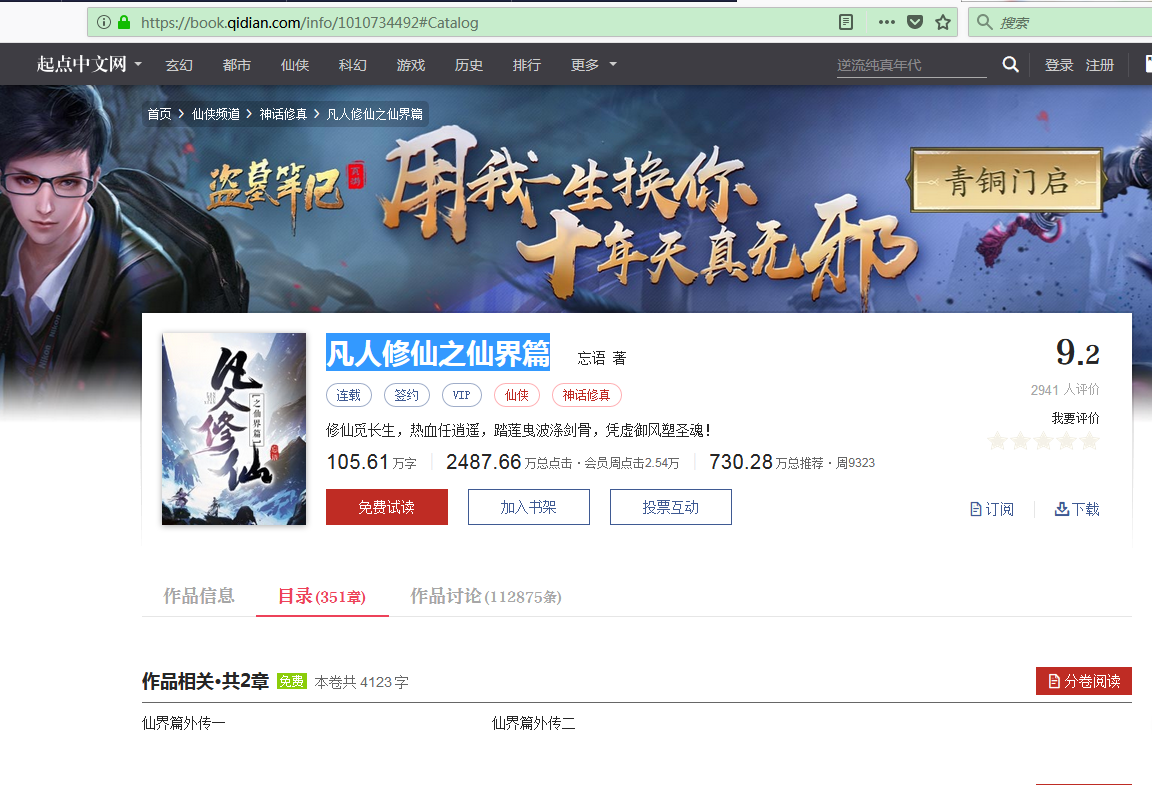
正文的章节如下图所示
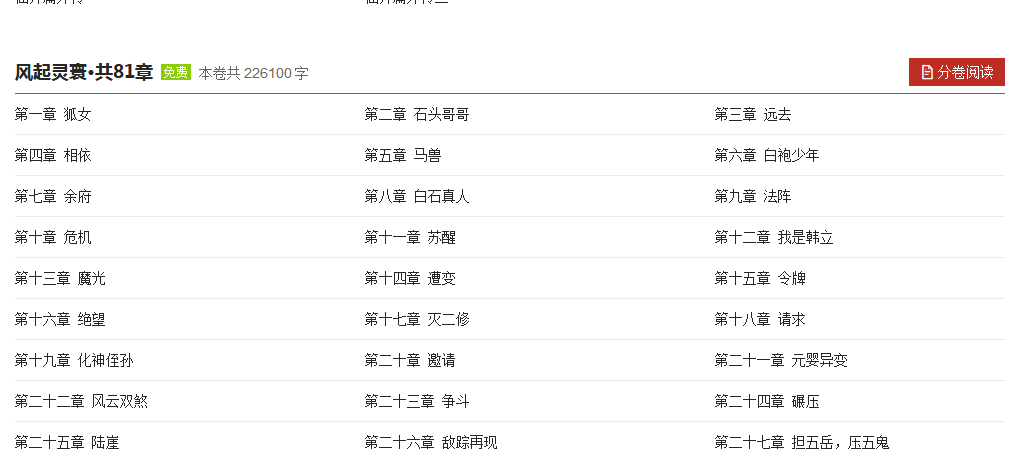
其中下面的章节为加密部分,现在暂时无法破解加密的部分。ε=(´ο`*)))唉..

下面直接上最核心的代码(位于spiders中的核心代码)
# -*- coding: utf-8 -*- import scrapy from qidian.items import QidianItem import enum class Qidian1Spider(scrapy.Spider): name = 'qidian1' allowed_domains = ['qidian.com'] start_urls = ['https://book.qidian.com/info/1010734492#Catalog'] def parse(self, response): #div[@class="volume"][1或者2或者3或者4]中的数值,这些数值自定义一个变量替代,目前一共是4个部分,随着后续章节的增加,会出现第五部分或者第六部分 依次累加 ###div[@class="volume"]["num"] ,num是自定义的变量,你可以换成自己想要的abc或者bb等变量,把这些变量放进去,就能得到所有章节的title??(不知道为什么) for aa in response.xpath( '//div[@class="volume-wrap"]/div[@class="volume"]["' '这里填啥都行,不填就报错,或者去掉class=volume后面的这个中括号就得不到a标签中的标题,我也不知道什么原因!!!"]' '/ul[@class="cf"]/li'): title=aa.xpath("a/text()").extract() link=aa.xpath("a/@href").extract() ###得到一个list集合 for new_link in link: new_links="https:"+str(new_link) #print(new_links) # yield scrapy.request(new_link,callback=self.parse_content) yield scrapy.Request(new_links, callback=self.parse_content) def parse_content(self,response): for bb in response.xpath('//div[@class="main-text-wrap"]'): title=bb.xpath('//div[@class="text-head"]/h3[@class="j_chapterName"]/text()').extract() content = bb.xpath('//div[@class="read-content j_readContent"]/p/text()').extract() #print(title) ###切分list,得到空格的位置 kong_list=list(''.join(title)) #print(type(kong_li item=QidianItem() item['title']=title ######sort(reverse = False) ###reverse = False 升序(默认)。sorted(n,key=lambda x:CN[x]) item['content']=content yield item