在hadoop中进行提交作业到yarn运行MapReduce运算wordcount
①首先保证yarn正常启动了
②切换到hadoop安装目录之下的share目录
zhangsf@hadoop1:/opt/hadoop-2.6.5/share/hadoop/mapreduce$ pwd
/opt/hadoop-2.6.5/share/hadoop/mapreduce找到examples的jar包
/opt/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar 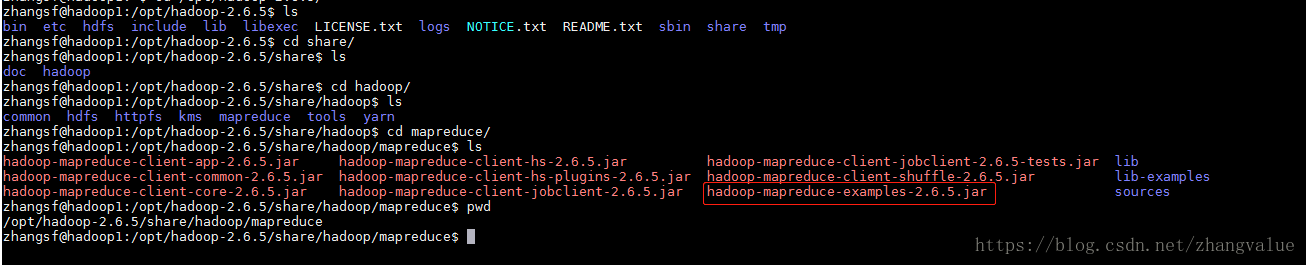
③切换到hadoop的bin目录之下输入
hadoop jar /opt/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input/aaa.txt /output/wc/其中的
/opt/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar 是example的路径
wordcount是自带执行wordcount的指令
/input/aaa.txt 是自己上传到hdfs系统的文件
/output/wc/是统计之后生成文件的路径
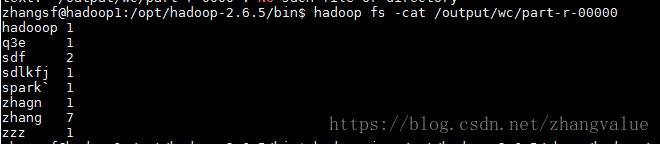
最终结果:

④查看最终的统计结果
可以去浏览器中查看生成的信息:

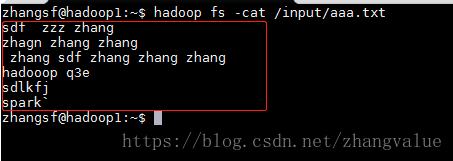
先看aaa.txt里面的信息
再看统计之后的信息