# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
# 我们如果要模拟登陆,就必须要拿到cookie
# response里面有url,text等等,但遗憾的是不想requests,可以直接拿到cookie
# 但我们可以导入一个模块
from scrapy.http.cookies import CookieJar
class GetChoutiSpider(scrapy.Spider):
name = 'get_chouti'
allowed_domains = ['chouti.com']
start_urls = ['https://dig.chouti.com/']
cookies = None
def parse(self, response):
# 此时只是拿到了一个存储cookie的容器
cookie_obj = CookieJar()
# response表示请求的所有内容,response.request表示我们发的请求
# 接受我们上面说的两个参数
cookie_obj.extract_cookies(response, response.request)
# 那么此时的cookie_obj便保存了我们的cookie信息
print(cookie_obj._cookies)
'''
{'.chouti.com': {'/': {'gpsd': Cookie(version=0, name='gpsd', value='1c61978d6bb94989674386b29f2fd15d', port=None, port_specified=False, domain='.chouti
.com', domain_specified=True, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=1533183431, discard=False, comment=None, co
mment_url=None, rest={}, rfc2109=False)}}, 'dig.chouti.com': {'/': {'JSESSIONID': Cookie(version=0, name='JSESSIONID', value='aaaouDhGaca3Ugddzblrw', po
rt=None, port_specified=False, domain='dig.chouti.com', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, e
xpires=None, discard=True, comment=None, comment_url=None, rest={}, rfc2109=False)}}}
'''
# 上面便是我们获取的cookie信息
# 将cookie保存起来
self.cookies = cookie_obj._cookies
# 同理request也一样
'''
类似于requests
res = requests.get(xxxxx)
res.cookies._cookies便是返回的cookie信息
'''
# 然后就要模拟登陆了,带上用户名和密码和cookie
yield Request(
url='https://dig.chouti.com/login',
method='POST',
headers={'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'},
cookies=self.cookies,
callback=self.check_login,
# 这里的body类似于requests的data,但是形式不一样,body不能够以字典的形式提交
# 账号密码输入的对的,这里隐藏了
body='phone=8618xxxxx2459&password=zxxxxxhyyxx&oneMonth=1'
)
# 回调函数,用于检测请求是否发送成功。
# 注意回调函数不能是self.parse,否则回调执行的时候又把请求发过去了
# 里面自动封装了response,就是我们执行成功之后的响应结果
def check_login(self, response):
print(response.text)
'''
{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_53059370687"}}}
'''
# 登陆成功
# 接下来进行点赞。
# 登陆页面不需要cookie
# 依旧yield
yield Request(
url='https://dig.chouti.com/',
callback=self.like, # 定义一个用于点赞的回调函数
)
def like(self, response):
# 此时的response则是整个页面
id_list = response.xpath('//div[@share-linkid]/@share-linkid').extract()
for nid in id_list:
url = 'https://dig.chouti.com/link/vote?linksId=%s' % nid
yield Request(
url=url,
method='POST',
cookies=self.cookies,
headers={'referer': 'https://dig.chouti.com/'},
# 再加一个回调函数,查看是否点赞成功
callback=self.show_like
)
def show_like(self, response):
print(response.text)
执行成功response.text就会返回该结果
{"result":{"code":"9999", "message":"推荐成功", "data":{"jid":"cdu_53059370687","likedTime":"1530598017650000","lvCount":"24","nick":"古明地盆","uvCount
":"2921","voteTime":"小于1分钟前"}}}
{"result":{"code":"9999", "message":"推荐成功", "data":{"jid":"cdu_53059370687","likedTime":"1530598017657000","lvCount":"34","nick":"古明地盆","uvCount
":"2921","voteTime":"小于1分钟前"}}}
如果点赞成功之后继续执行,就会有如下提示
{"result":{"code":"30010", "message":"你已经推荐过了", "data":""}}

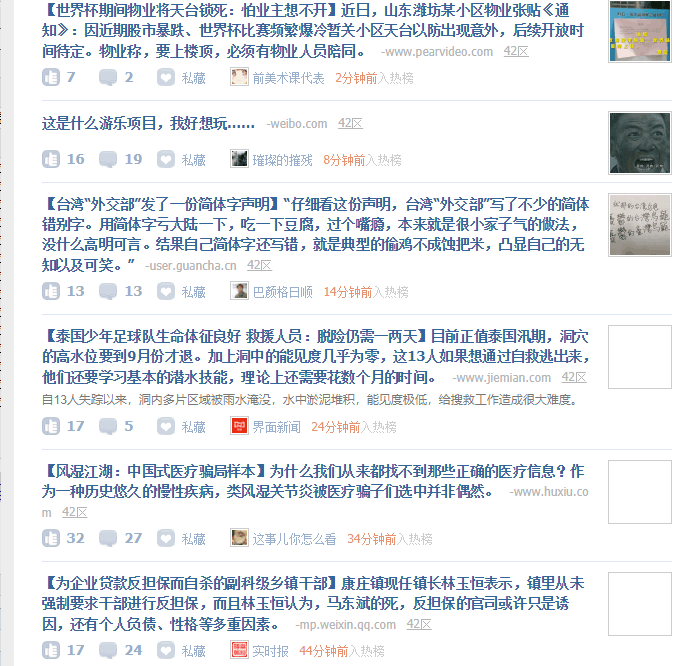
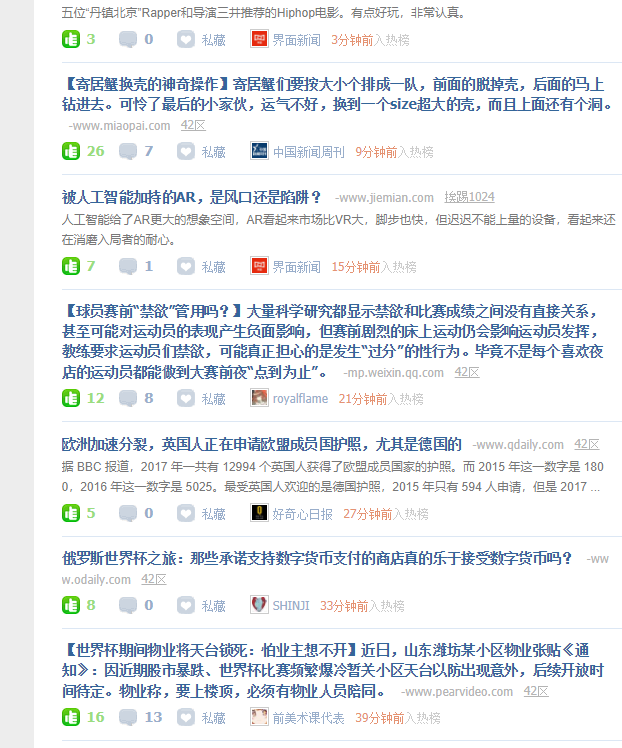
会发现,我只给当前页进行了点赞,如果我想给好多页进行点赞呢?
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
# 我们如果要模拟登陆,就必须要拿到cookie
# response里面有url,text等等,但遗憾的是不想requests,可以直接拿到cookie
# 但我们可以导入一个模块
from scrapy.http.cookies import CookieJar
class GetChoutiSpider(scrapy.Spider):
name = 'get_chouti'
allowed_domains = ['chouti.com']
start_urls = ['https://dig.chouti.com/']
cookies = None
def parse(self, response):
# 此时只是拿到了一个存储cookie的容器
cookie_obj = CookieJar()
# response表示请求的所有内容,response.request表示我们发的请求
# 接受我们上面说的两个参数
cookie_obj.extract_cookies(response, response.request)
# 那么此时的cookie_obj便保存了我们的cookie信息
print(cookie_obj._cookies)
'''
{'.chouti.com': {'/': {'gpsd': Cookie(version=0, name='gpsd', value='1c61978d6bb94989674386b29f2fd15d', port=None, port_specified=False, domain='.chouti
.com', domain_specified=True, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=1533183431, discard=False, comment=None, co
mment_url=None, rest={}, rfc2109=False)}}, 'dig.chouti.com': {'/': {'JSESSIONID': Cookie(version=0, name='JSESSIONID', value='aaaouDhGaca3Ugddzblrw', po
rt=None, port_specified=False, domain='dig.chouti.com', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, e
xpires=None, discard=True, comment=None, comment_url=None, rest={}, rfc2109=False)}}}
'''
# 上面便是我们获取的cookie信息
# 将cookie保存起来
self.cookies = cookie_obj._cookies
# 同理request也一样
'''
类似于requests
res = requests.get(xxxxx)
res.cookies._cookies便是返回的cookie信息
'''
# 然后就要模拟登陆了,带上用户名和密码和cookie
yield Request(
url='https://dig.chouti.com/login',
method='POST',
headers={'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'},
cookies=self.cookies,
callback=self.check_login,
# 这里的body类似于requests的data,但是形式不一样,body不能够以字典的形式提交
# 账号密码输入的对的,这里隐藏了
body='phone=8618xxxxx2459&password=zxxxxxhyyxx&oneMonth=1'
)
# 回调函数,用于检测请求是否发送成功。
# 注意回调函数不能是self.parse,否则回调执行的时候又把请求发过去了
# 里面自动封装了response,就是我们执行成功之后的响应结果
def check_login(self, response):
print(response.text)
'''
{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_53059370687"}}}
'''
# 登陆成功
# 接下来进行点赞。
# 登陆页面不需要cookie
# 依旧yield
yield Request(
url='https://dig.chouti.com/',
callback=self.like, # 定义一个用于点赞的回调函数
)
def like(self, response):
# 此时的response则是整个页面
id_list = response.xpath('//div[@share-linkid]/@share-linkid').extract()
for nid in id_list:
url = 'https://dig.chouti.com/link/vote?linksId=%s' % nid
yield Request(
url=url,
method='POST',
cookies=self.cookies,
headers={'referer': 'https://dig.chouti.com/'},
# 再加一个回调函数,查看是否点赞成功
callback=self.show_like
)
# 此时点赞只是当前页,点赞,如果我想给每一页都点赞
# 想给多页点赞,找到对应的页码
pages = response.xpath('//div[@id="dig_lcpage"]//a/@href').extract()
for page in pages:
page_url = 'https://dig.chouti.com%s' % page
yield Request(
url=page_url,
# 注意这里的callback,是函数本身
# 这里找到所有的页码,比如page_url此时处于第二页
# 那么再调用自己,就会给第二页点赞,点完赞之后,page_url就会变成第三页
# 那么再调用自己,就会给第三页点赞,以此往复
callback=self.like
# 抽屉貌似有一百二十多页,我们这里指定以下递归的深度,只爬取四个深度
)
def show_like(self, response):
print(response.text)
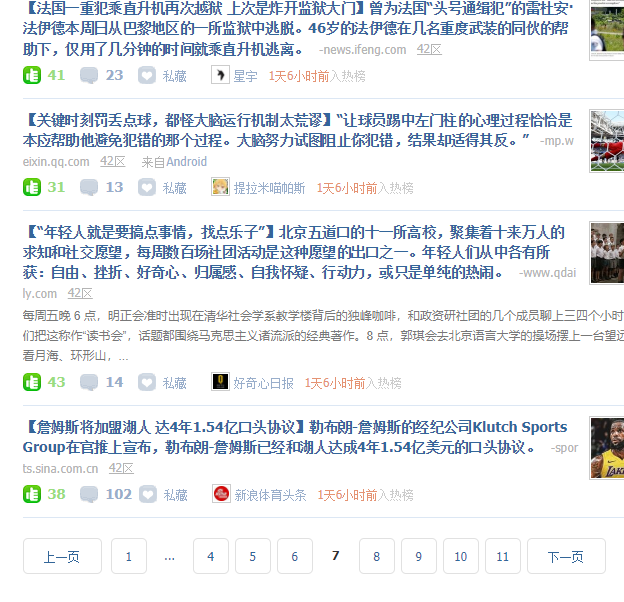
第七页也被点赞了
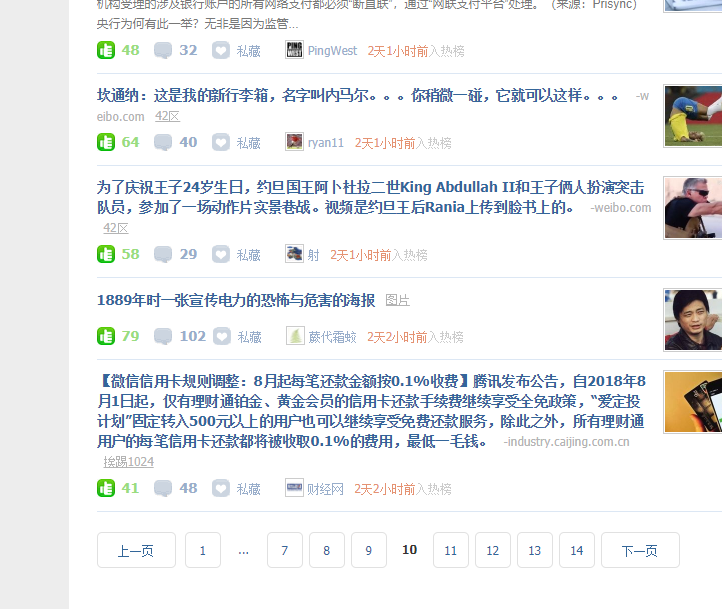
第十页也被点赞了
既然如此,就玩一个疯狂的,给所有页面都点赞
将settings里面的DEPTH_LIMIT=4改成DEPTH_LIMIT=0,等于零表示无限查找

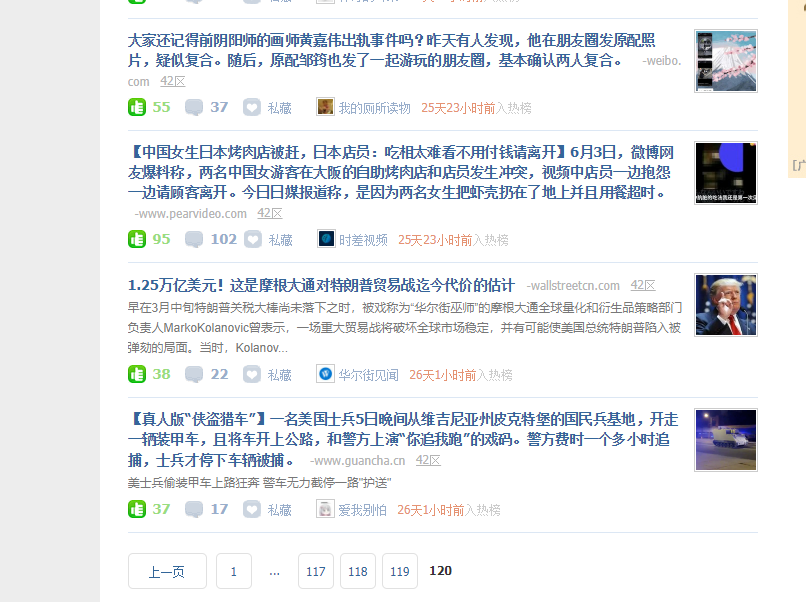
可以看到,一共120页,全点上了赞