一、概述
本节我们先来了解一下什么是决策树,以及决策树中的一些术语,方便我们来进行后面的学习,假如现在有了一棵决策树,它是如何完成分类功能的呢?让我们来看下面的例子,如图所示:
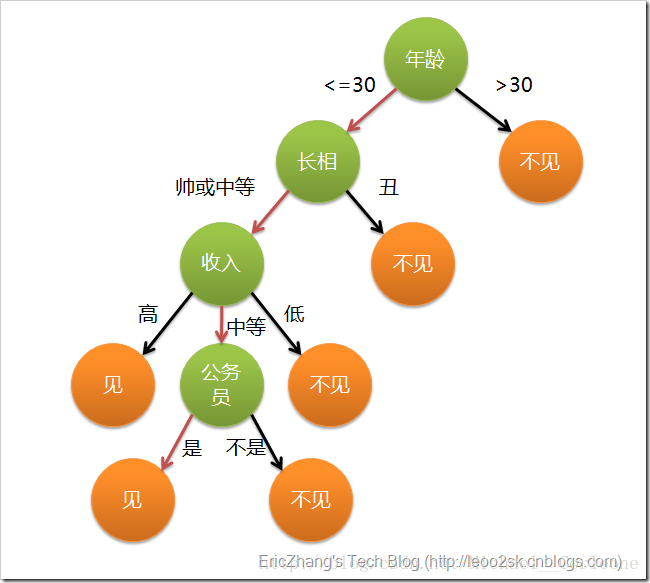
杨杨是个大美女,但是从小热爱学习的她,一直读到了研究生都么有考虑个人问题,现在到了婚嫁的年龄,家里开始催促,于是她想为自己找个如意郎君,家里人就告诉她,你要看男孩家是不是有车,是不是房,薪资怎么样等等一系列的要求,于是在家人的极力帮助下,为杨杨找来了几位单身男士,杨杨又不知如何抉择,我作为杨杨的好朋友,当然是将如图所示的结婚与否的结构图赠与她啦,并告诉她,这图可是我经过吴恩达教授的机器学习,然后根据很多已有的样本学出来的很是精确的预测模型哦,它一定可以帮到你的。于是杨杨就带着我的模型去见了那些单身男士,
上图就是一棵决策树,既然称之为树,当然他就具有树的特点(节点和有向边),节点又分为内部节点和叶子节点,图中绿色圆圈就代表了内部节点(表示了一个特征或属性),橙色的圆圈代表了叶子节点(最终的类别),有向边代表了在某个特征下可能的取值。
经过上面的分析想必大家已经懂得了给定一棵树之后如何分类的了,但是如何生成那颗树呢,这才是我们需要知道的重点,接下来就让我们真正的开始吧。。。。。。
二、树的生成
树的生成分为三步:特征选择阶段,树的生成阶段,树的剪枝阶段。具体是个怎么回事呢,我们可以先看下下面的例子:
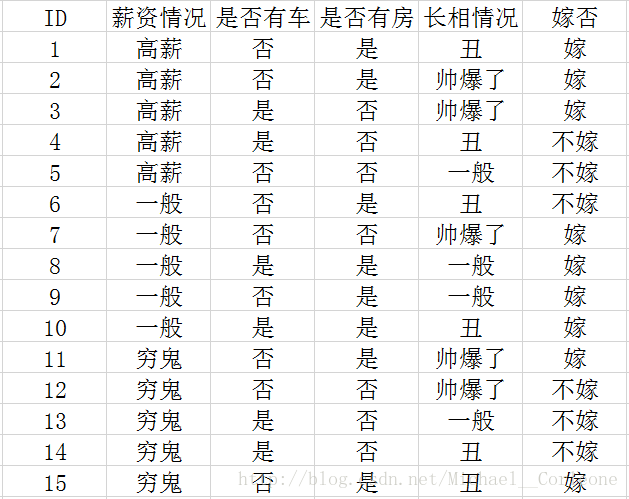
现有15个男士的结婚数据,他们的个人情况如上图所示,数据中包含了男士的4个特征:1薪资情况,有三个可能的取值;2是否有车,有两个可能取值;3是否有房,有两个可能取值;4长相情况,有三种可能的取值;最优一列是一个女生是否嫁给他的情况,也就是最终的类别,可以看出这是一个二分类的问题。我们的目的呢,就是根据已有的数据来学习到一个决策树,这样我们就可以帮助杨杨来选择一个不错的如意郎君啦!
可是现在有四个特征,我们该拿哪个作为第一个内部节点呢?这里就需要我们进行树的生成的第一步:特征选择。
2.1特征选择阶段
首先让我们来了解下信息论中的几个概念:熵,条件熵,互信息,信息增益。
熵:表示随机变量的不确定性的程度。定义公式为:
其中
代表了Y时间中第i个可能发生的概率,n代表了事件Y有n中可能。总之记住一句话,熵越大,这个事件的发成的不确定性就越大。假如:抛掷一枚硬币,当质地均匀时,出现正反的概率一样,我们很难猜出抛出的是正面还是反面,这时的熵就很大;但是当正面渡了一层铅时,由于重力原因,我们可以知道基本上每次都会出现反面,这种更加确定的情况熵就很小。
条件熵:定义如下图所示
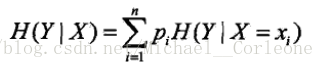
其中
,X,Y代表了两个事件,而它们之间有时有联系的(也就是联合概率分布),条件熵
代表了在一直随机变量X的情况下,Y的不确定性的大小。
互信息:熵
和条件熵
的差称之为互信息。定义如下:
在决策树中,类与特征的互信息也称之为信息增益:表示在已知特征X的信息而使得类Y的信息的不确定性减少的程度。很拗口?是的,官方定义一般都是这样。总结一下就是这样的,在已知特征X的信息情况下,信息增益越大,类Y的不确定性就越小。所以,我们以信息增益大的特征作为我们的首要内部节点。
介绍完比较拗口又乏味的理论,下面我们就来用上述例子来具体算一下所谓的信息增益,这样你就不会烦躁于这些概念了。上述例子中嫁否就是类Y,薪资情况,是否有车,是否有房,长相情况分别是特征
,
,
,
。
首先我们来计算特征
对训练数据集Y的信息增益:我们就要用到公式
1、从公式可以看出我们需要先计算出
,Y有两种取值嫁(
),不嫁(
),总共15个样本,嫁有9个,不嫁有6个,所以
,
,代入到公式
,得到H(Y)=0.971
2、接下来我们算条件熵
,
取值有三种,高薪(
),一般(
),穷鬼(
)。条件熵公式
,总共15个样本,高薪有5个,所以
,同理
,
,接下来我们算
,即已知高薪情况下Y的熵,我们只需提取1-5这5个都是样本的情况下算H(Y),步骤同1,
,同理再计算出
,
,最后在带入到条件熵公式,计算出条件熵公式
3、得到最终的信息增益:
2.2树的生成阶段
树的生成算法有ID3算法,C4.5算法,CART算法。
我们先来了解下ID3算法,它主要的思想就是比较各个特征的信息增益值,将信息增益大的作为最有特征,也就是内部节点,还是刚刚的例子,我们接下来就算出特征
,
,
的信息增益:
现在我们算完了四个特征的信息增益,通过比较,显而易见
(是否有车)的信息增益最大,所以特征
就被选作了最优特征,作为第一个内部节点。所以目前生成的树,如下图所示: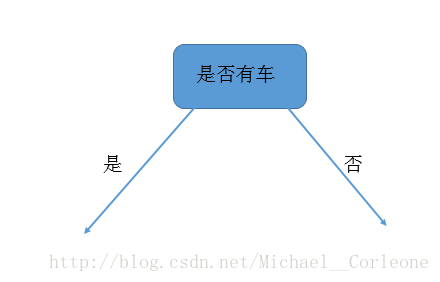
接下来又该怎么办呢,我还是不知道该做什么了,别着急,接下来就和上面没什么区别了。我们选择把
特征已经提取了,它有两个选择,每个选择下的内部节点又该是什么呢?我们将上诉样本在这个基础上分成两部分,“是”的部分包括(3、4、8、10、13、14)6个样本,“否”的部分包含剩下的9个样本。我们就在各自的样本下计算剩余三个特征的信息增益,比较出信息增益最大的特征作为下一内部节点,直到所有的样本指向同一类为止!
有车情况下的内部节点,先将样本提取出来:
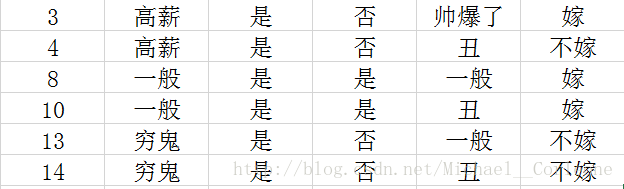
通过比较以上信息增益,那么就选择出
特征作为有车情况下的下一个内部节点。
接下来看无车的情况:
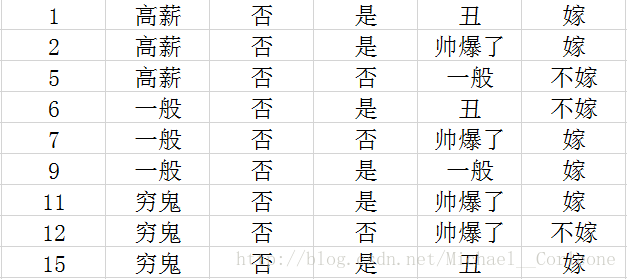
通过比较以上信息增益,那么就选择出
特征作为无车情况下的下一个内部节点。
所以现在的树的构建情况如下图所示:
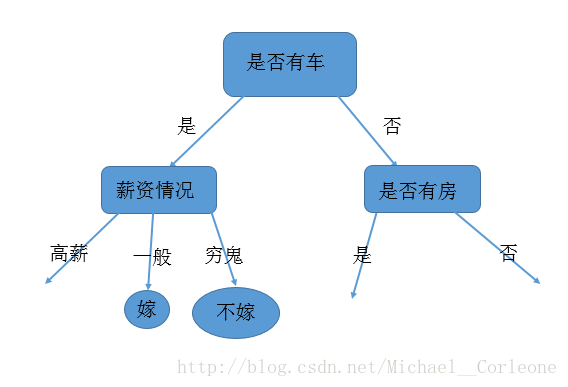
以此类推相信大家也知道了如何去构建一棵完整的决策树了吧,但是到最后大家可能会发现,用了所有的特征,但是还有有些样本没有完全分类(没能到达叶子结点),这就说明我们的特征选取不好,以上只是我自己编造的数据,所以存在一写不合理的地方,