背景
论文地址:Aggregated Residual Transformations for Deep Neural Networks
代码地址:GitHub
这篇文章在 arxiv 上的时间差不多是今年 cvpr 截稿日,我们就先理解为是投的 cvpr 2017 吧,作者包括熟悉的 rbg 和何凯明,转战 Facebook 之后代码都放在 Facebook 的主页里面了,代码也从 ResNet 时的 caffe 改成了 torch :)
贡献
- 网络结构简明,模块化
- 需要手动调节的超参少
- 与 ResNet 相比,相同的参数个数,结果更好:一个 101 层的 ResNeXt 网络,和 200 层的 ResNet 准确度差不多,但是计算量只有后者的一半
方法
提出来 cardinality 的概念,在上图左右有相同的参数个数,其中左边是 ResNet 的一个区块,右边的 ResNeXt 中每个分支一模一样,分支的个数就是 cardinality。此处借鉴了 GoogLeNet 的 split-transform-merge,和 VGG/ResNets 的 repeat layer。
所谓 split-transform-merge 是指通过在大卷积核层两侧加入 1x1 的网络层,控制核个数,减少参数个数的方式。借鉴 fei-fei li 的 cs231n 课件1:
而 repeat layer 则是指重复相同的几层,前提条件是这几层的输出输出具有相同的维度,一般在不同的 repeat layers 之间使用 strip=2 降维,同时核函数的个数乘 2。
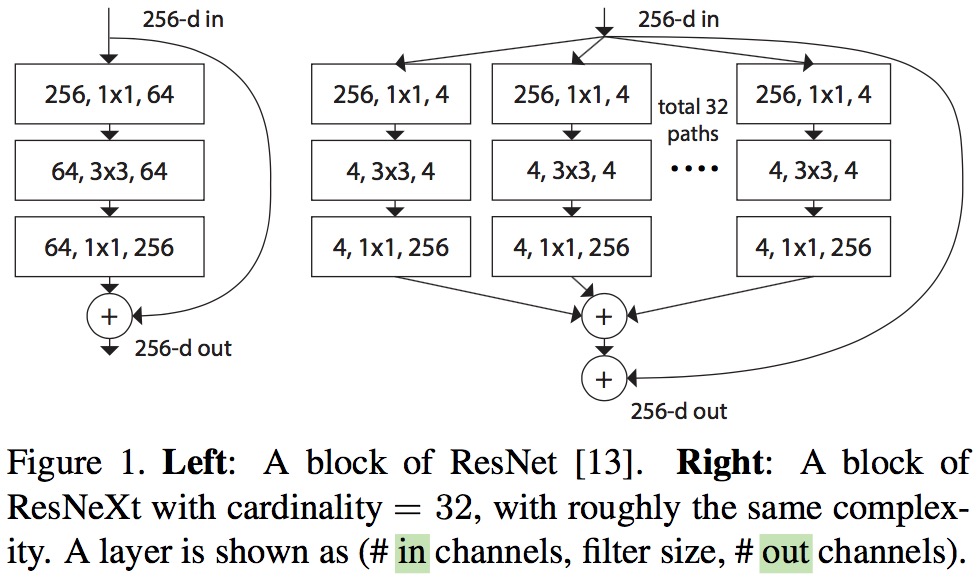

本文网络参数
以上图为例,中括号内就是 split-transform-merge,通过 cardinality(C) 的值控制 repeat layer。
output 在上下相邻的格子不断减半,中括号内的逗号后面卷积核的个数不断翻倍。
等价模式
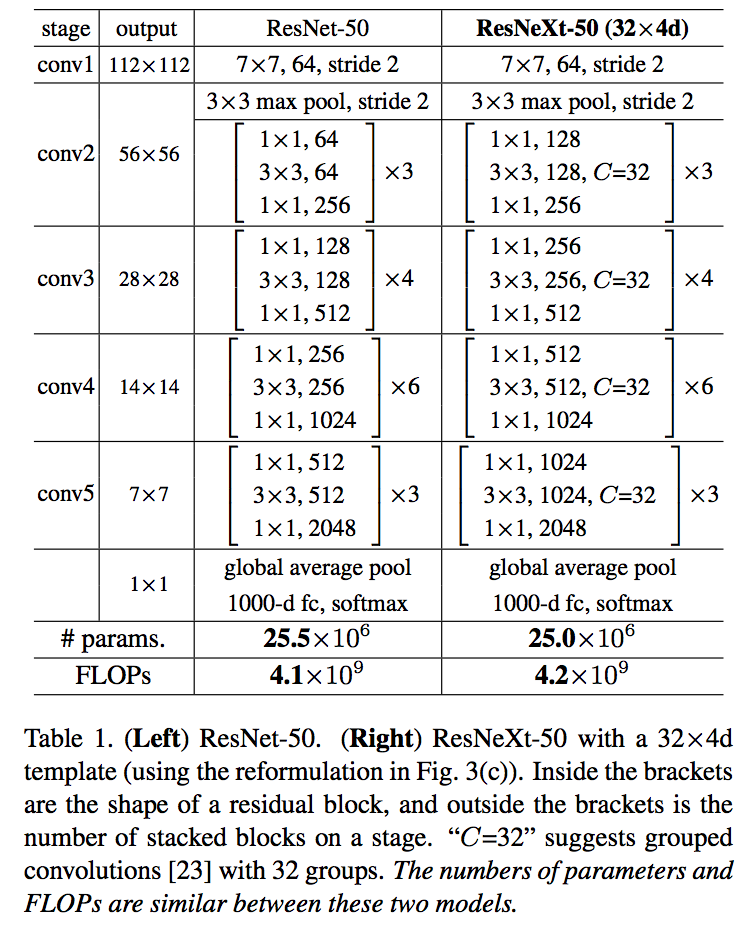
图一右侧的模型有两个等价的模型,最右侧是 AlexNet 中提出的分组卷积,相同层的 width 分组卷积,最终作者使用的是下图最右边的模型,更加简洁并且训练更快。
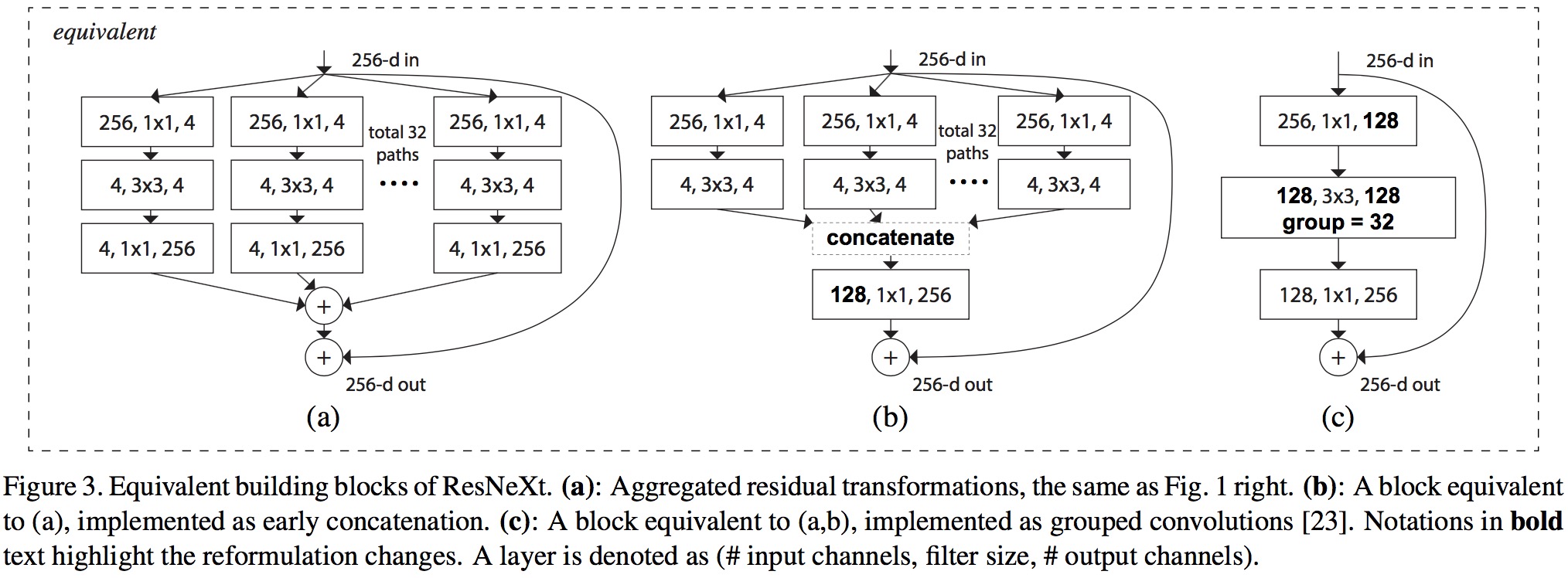
模型参数
调节 cardinality 时,如何保证和 ResNet 的参数个数一致呢?本文考虑的是调节 split-transform-merge 中间第二层卷积核的个数。
实验
基本和 ResNet 差不多,augmentation、以及各个参数
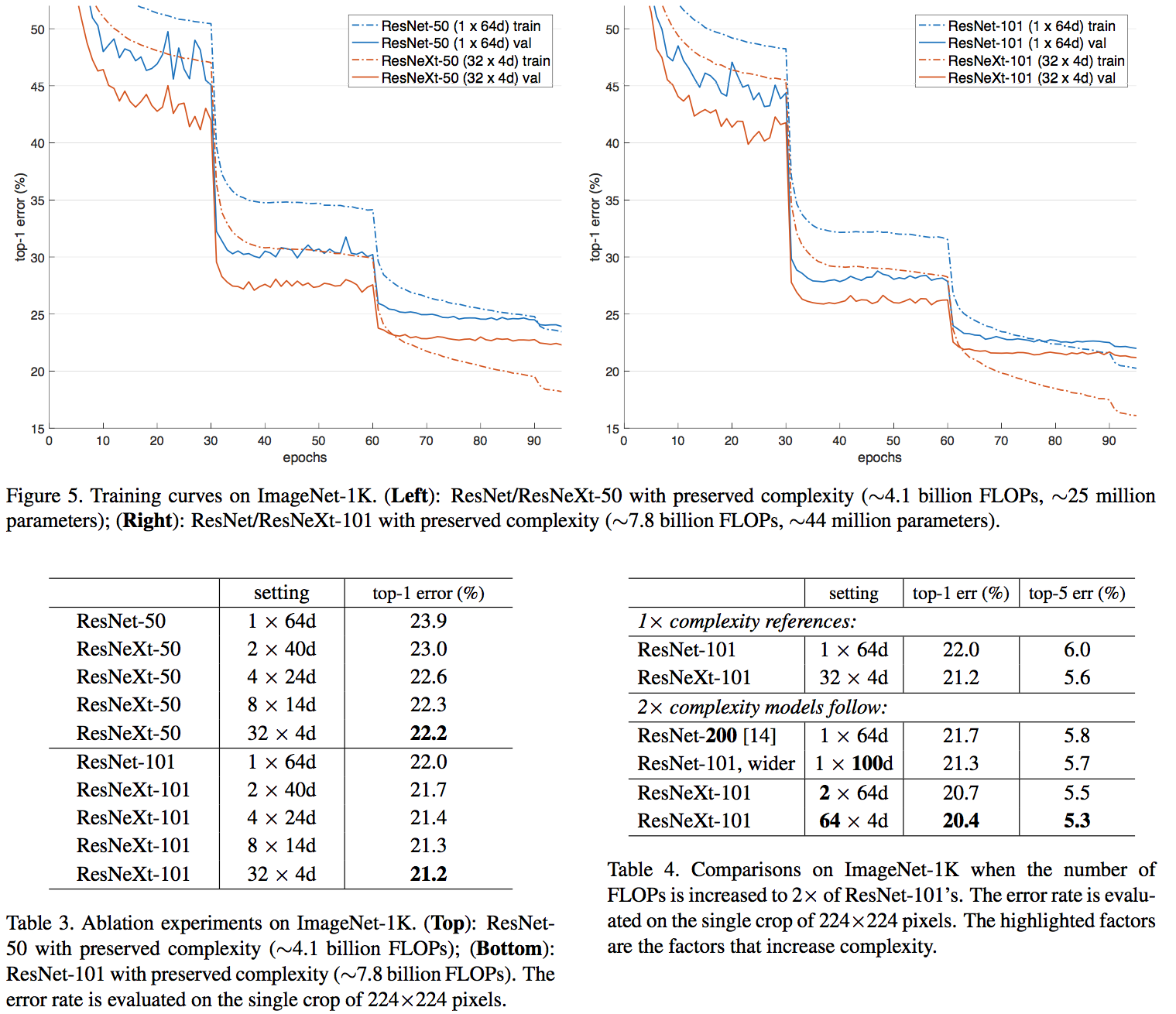
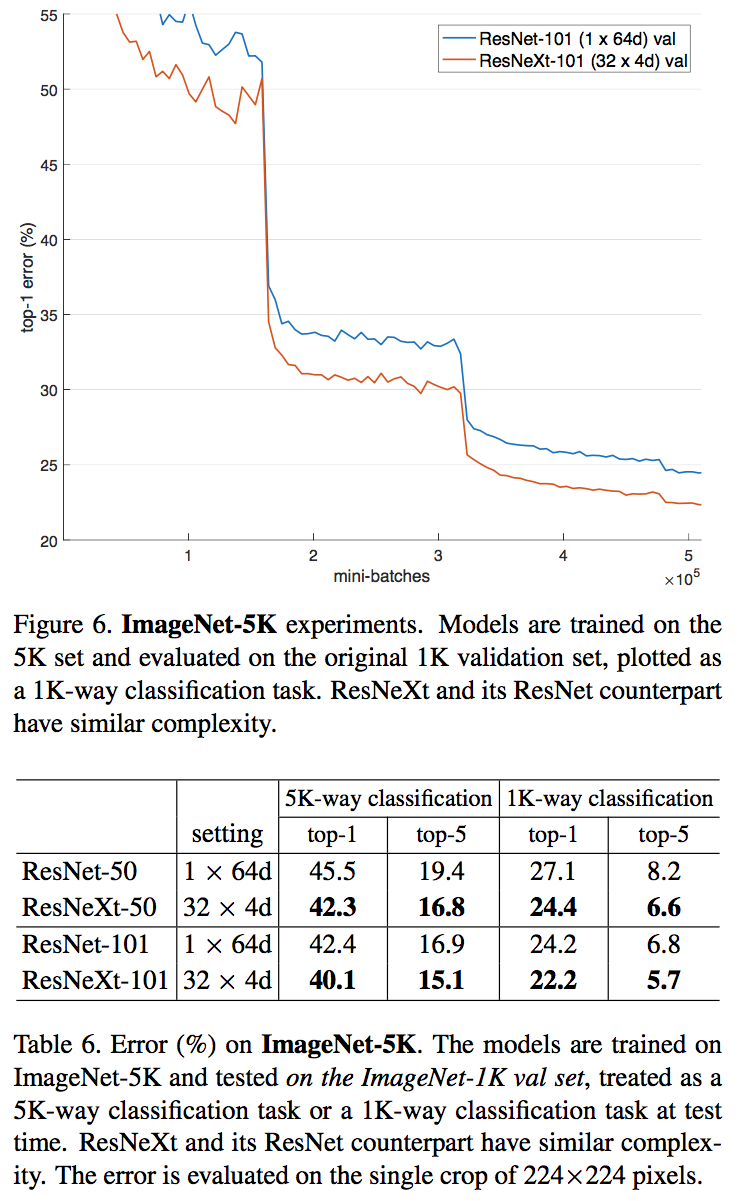
结论
- ResNeXt 与 ResNet 在相同参数个数情况下,训练时前者错误率更低,但下降速度差不多
- 相同参数情况下,增加 cardinality 比增加卷积个数更加有效
- 101 层的 ResNeXt 比 200 层的 ResNet 更好
- 几种 sota 的模型,ResNeXt 准确率最高