第一步,准备工作
包括安装Git,CMake以及下载cppan命令工具、从git上获取tesseract源码
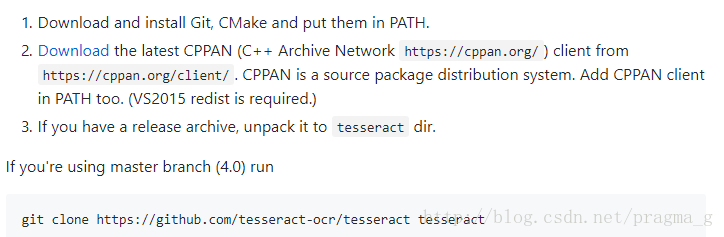
第二步,生成MSVC解决方案
本文为64位编译器(32直接cmake ..即可),编译完成后,在build目录下出现tesseract.sln,即解决方案文件
VS2017为15 2017
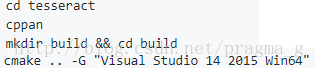
第三步,MSVC中编译源码
对解决方案执行生成解决方案过程中,会遇到以下问题
1、C2001、C2059、C1057、C2146之类的错误,提示位于项目cppan中,此类错误为对应文件的编码格式问题,这些文件中存在字符值(字符,字符串)参数,由于中文系统的编码方式与英文不一样,所以导致错误。打开对应的文件,设置 ”高级保存选项“为Unicode(UTF-8带签名)格式即可,有个文件例外,即tesseract\ccmain\equationdetect.cpp,需要保存为简体中文(GB2312-80)
注:一般是这几个文件:gbookmarkfile.c,gregex.c,gkeyfile.c,gfileutils.c,gconvert.c,pango-language-sample-table.h,equationdetect.cpp。
找不到高级保存选项的可参考高级保存选项设置
2、错误为C1083,dirent.h文件找不到,可以直接从 Github: tronkko/dirent 获得这个文件。
dirent.h 是一个来自于 C POSIX library 的文件,通常被包含在 GCC (Cross-platform)、MinGW (Microsoft Windows)、Borland C++ 这些编译器中,但是 MSVC 并不包含此文件。
通过http://kinolien.github.io/gitzip/,输入上面github上dirent.h的url,直接下载该文件,然后复制到Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.11.25503\include目录中。
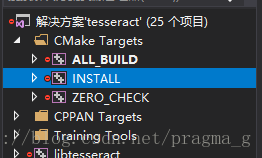
第四步,安装tesseract库
右键单击CMake中的INSTALL,选择仅用于项目菜单中的仅生成INSTALL,即可在系统盘中安装库,安装位置一般为C:\Program Files\tesseract
注:此步骤一定要确保VS是以管理员权限运行的,否则会报错,因为在系统盘中创建文件是需要管理员权限的。
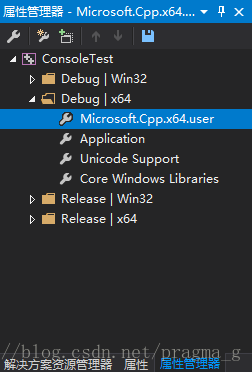
第五步,tesseract库的配置
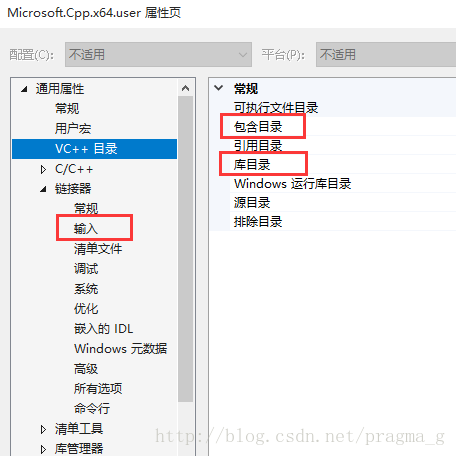
随便打开一个项目,如果没有,就新建一个。打开属性管理器,对编译器进行配置,如x64 debug模式,右击.user项,打开配置面板。
1、找到VC++目录项,将前面安装的tesseract相应目录进行包含,include目录和lib目录
注:由于tesseract库需要用到leptonica库,还需要在include目录中添加leptonica源码src中的所有头文件。(Ensure that the development headers for Leptonica are installed before compiling Tesseract.)
2、配置链接器的输入依赖项(如果不配置,程序就会报无法解析的外部命令错误),添加pvt.cppan.demo.danbloomberg.leptonica-1.75.1.lib(需要先从.cppan的storage中找到并复制到tesseract安装目录的lib目录中)和tesseract400d.lib。
3、.dll文件,将之前编译的tesseract的build文件夹中bin文件夹下的.dll文件全部复制到tesseract安装目录下的bin文件夹中,即C:\Program Files\tesseract\bin,然后设置环境变量,在Path中添加这个目录,如果不配置环境变量,程序能够编译成功,但在运行时会报相应的.dll文件丢失的错误。
附上测试代码:
如果能成功编译并运行,说明基本成功。
注:unichar.h文件中UTF32ToUTF8方法的返回值为string类型,由于string为std名称空间下的,该声明中没有加上名称空间作用域,会报错无法识别的标识符,根据错误定位到该文件,在string前加上std::即可,这个与前面tesseract库的编译无关。
另外,如果要想正确运行,还需要tesseract语言包的支持,并添加一个环境变量TESSDATA_PREFIX指向tessdata目录。
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
int main()
{
char *outText;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api->Init(NULL, "eng")) {
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
// Open input image with leptonica library
Pix *image = pixRead("/usr/src/tesseract/testing/phototest.tif");
api->SetImage(image);
// Get OCR result
outText = api->GetUTF8Text();
printf("OCR output:\n%s", outText);
// Destroy used object and release memory
api->End();
delete [] outText;
pixDestroy(&image);
return 0;
}