0x0 Livy安装与运行
登录官网:http://livy.incubator.apache.org/
下载最新版 livy。
1. 解压
2. 配置:在conf/livy-env.sh中添加:
export SPARK_HOME=path/to/spark
export HADOOP_CONF_DIR=/etc/hadoop/conf- 进入bin文件执行
#前台模式,可观察程序运行日志
./livy-server
#后台模式
./livy-server start启动服务。
注意:如果报错说无法创建日志文件,则创建相应的日志文件的路径,然后重启livy。
0x1 使用
当成功启动livy服务后,打开浏览器,输入:
localhost:8998
登录livy页面,可见如下页面:
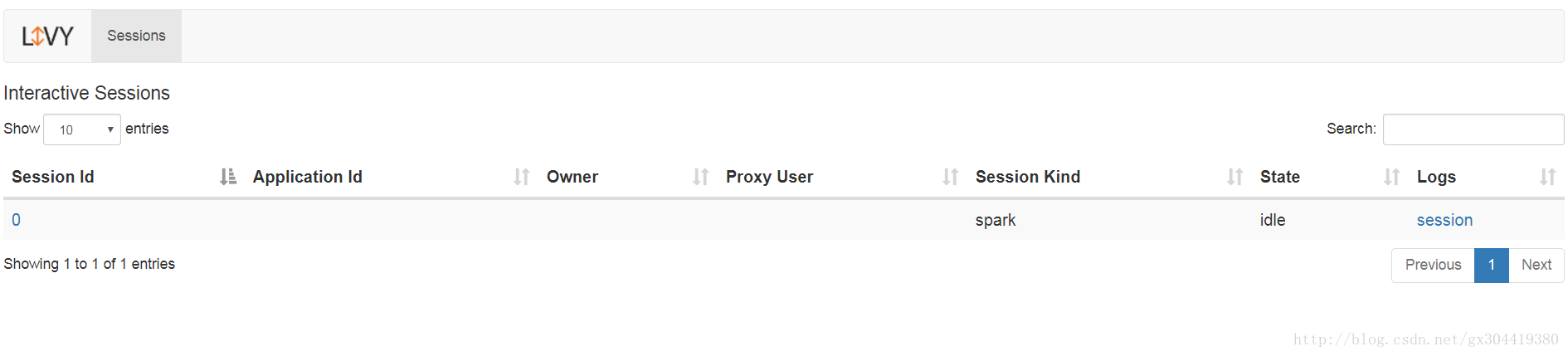
livy支持两种两种任务提交方案:
1、交互式:说白了,就是把原本在spark-shell里面执行的语句,通过http请求发送到livy服务端,然后livy在服务端开启spark-shell执行你传过来的语句;
2、批处理式:说白了,帮你做spark-submit的工作,同样通过http请求吧参数发到livy服务端。
1.1 交互式使用方法
工具采用postman,首先新建一个session(其实就是开启一个spark application):请求方式post,请求URL为 livy-ip:8998/sessions
请求体类似如下格式:
{
"kind": "spark",
"conf" : {
"spark.cores.max" : 4,
"spark.executor.memory" : "512m"
}
}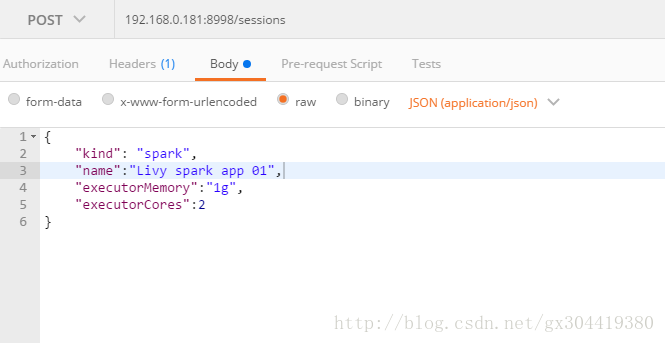
就是利用postman发送一个post请求,请求体是json格式,json中可以指定appName,申请多少内存,申请多少cpu等信息。
然后会受到响应:
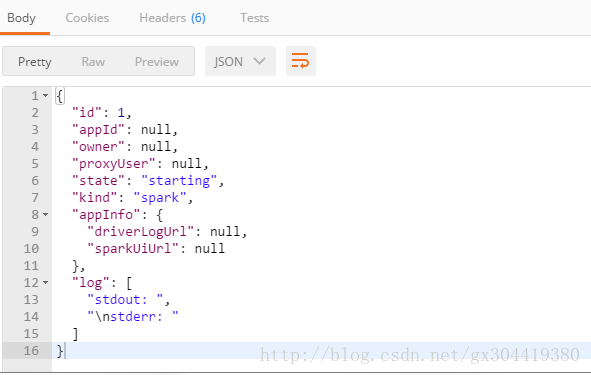
可以看到,开启了一个session,他的id=1。
接下来,我们可以向该session发送scala语句进行执行,请求方式post,请求URL为 livy-ip:8998/sessions/{id}/statements:
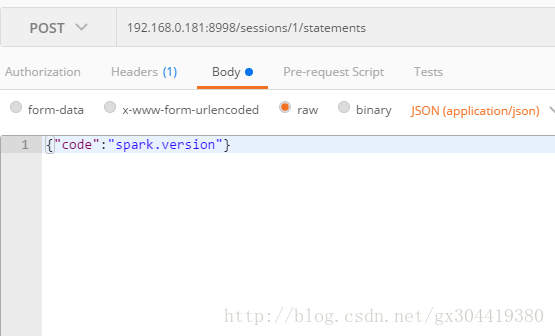
可以得到一个响应:
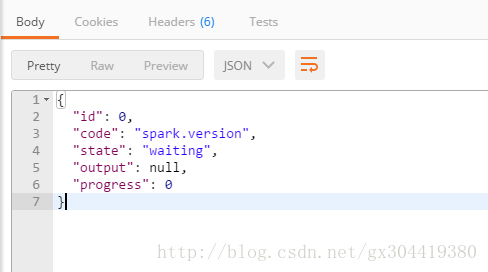
可以看到,这里的id=0,是指该statments的id
然后在发送另一个请求来查看输出,请求方式get,请求url为livy-ip:8998/sessions/1/statements/0:

可以得到响应:
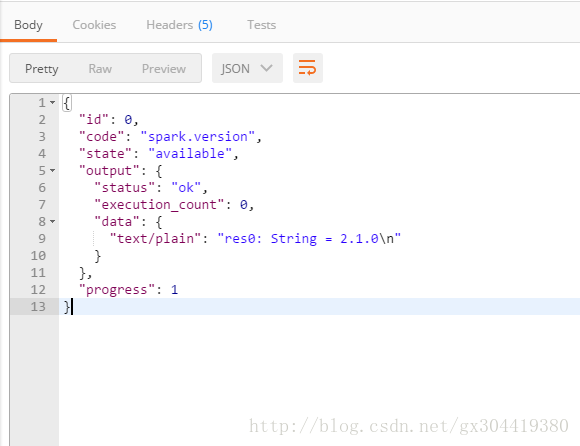
其中,output中的data就是输出的具体数据,progress是指进度,有时候查出来progress小于1,说明任务还没执行完。