1.准备hadoop环境
1.1 官网下载hadoop-2.7.3.tar.gz解压http://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/
目录为D:\software\hadoop-2.7.4
1.2 配置hadoop环境变量
先添加HADOOP_HOME
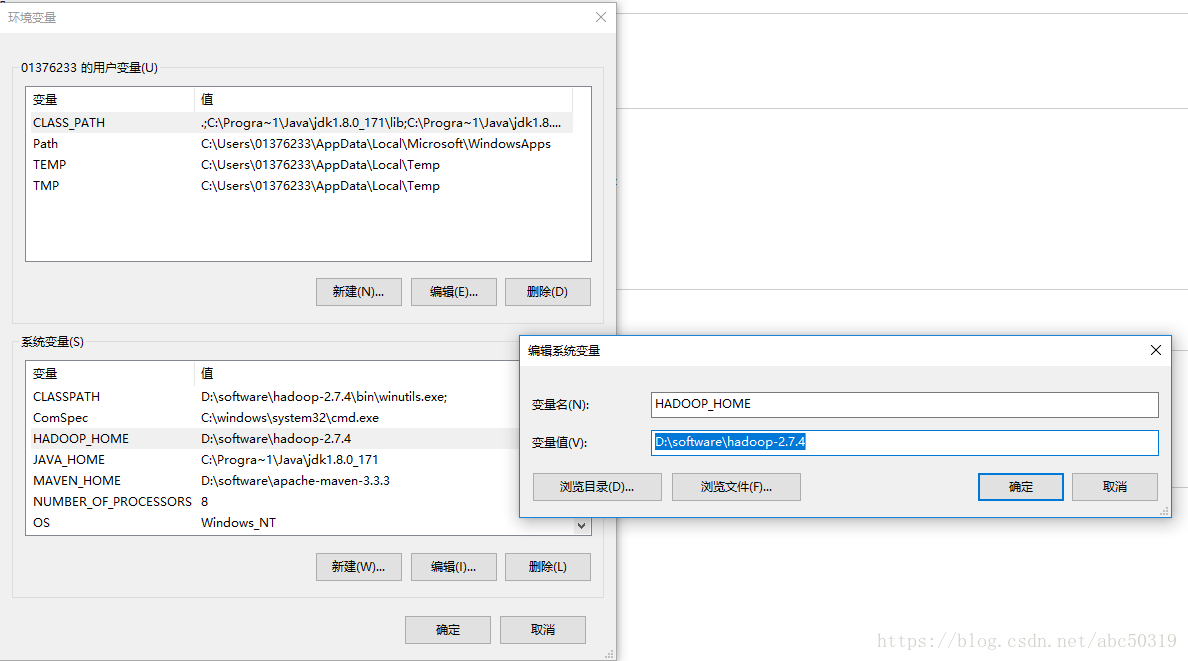
再添加path
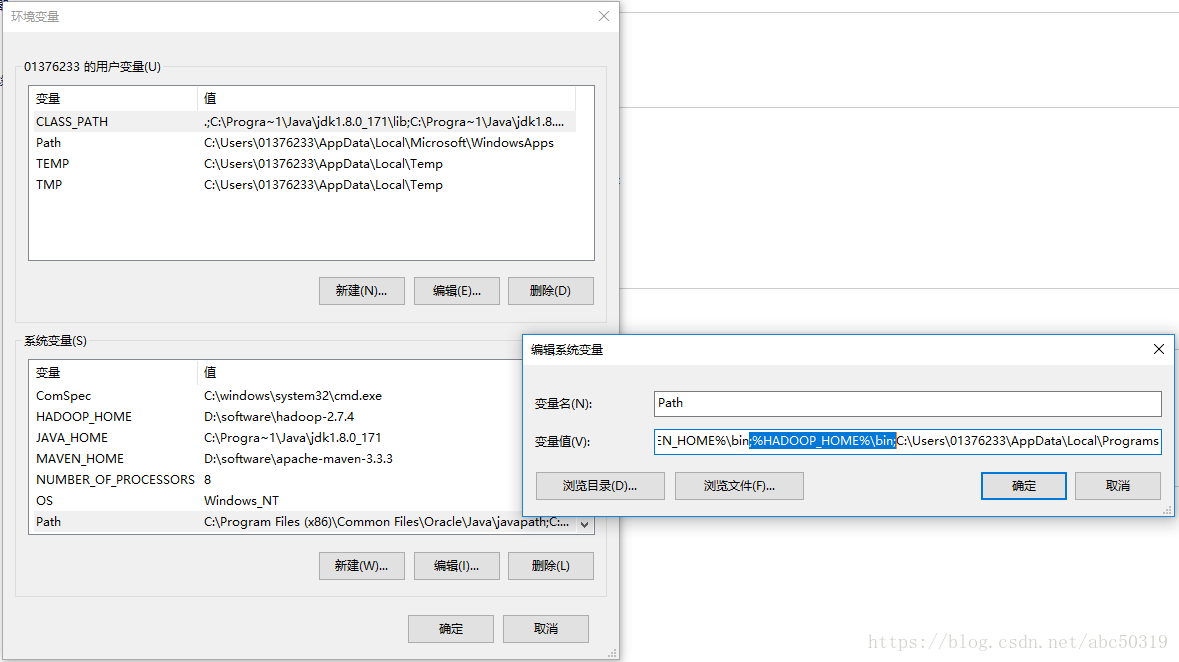
1.3 下载hadoop.dll-and-winutils.exe-for-hadoop2.7.3-on-windows_X64-master,
将D:\software\hadoop.dll-and-winutils.exe-for-hadoop2.7.3-on-windows_X64-master\bin目录下的全部文件copy到
D:\software\hadoop-2.7.3\bin下。
下载https://codeload.github.com/rucyang/hadoop.dll-and-winutils.exe-for-hadoop2.7.3-on-windows_X64/zip/master
1.4 本地调试hadoop代码还要找到winutills.exe的CLASSPATH
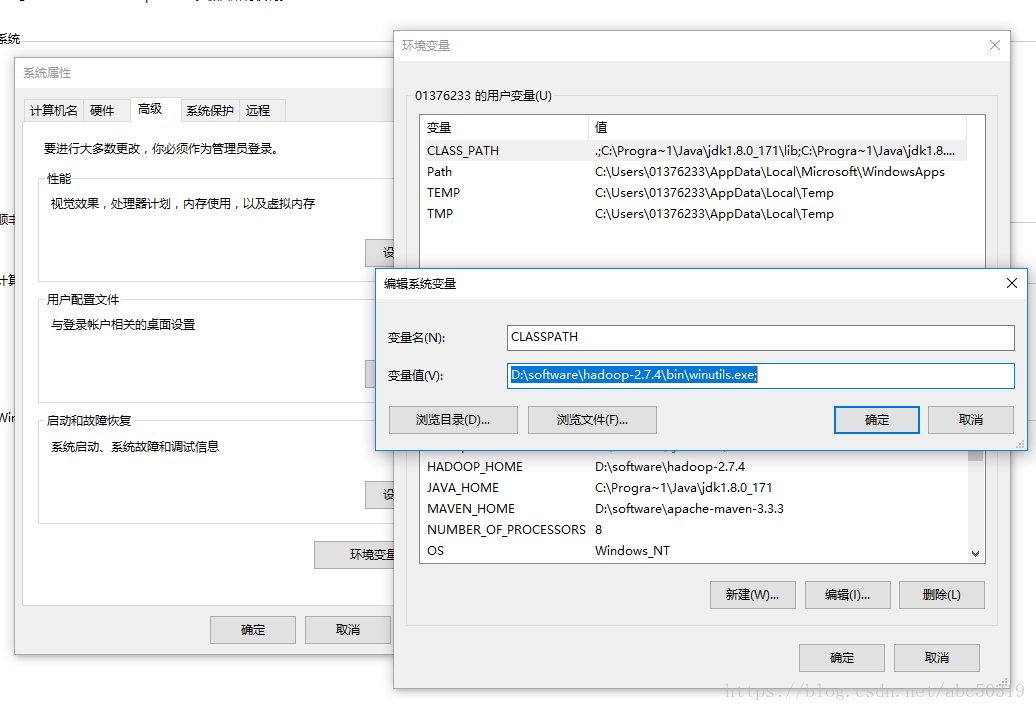
1.5 还要把D:\software\hadoop.dll-and-winutils.exe-for-hadoop2.7.3-on-windows_X64-master\bin的hadoop.dll
copy 到C:\Windows\System32,解决这个报错的问题。
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode
2.将/app/spark-2.1.1-bin-hadoop2.6/conf目录下的hdfs-site.xml和hive-site.xml配置文件放到工程的resources目录下
hive-site.xml 是要获取hive.metastore.uris 这个配置,得到hive元数据的信息;
hdfs-site.xml 是要获取数据在具体的哪个位置。XXXXXXXXXXXXXXXX
3.spark sql的一个小demo
package com.wilson.mysfspark; import org.apache.spark.SparkConf; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.SparkSession; public class myJavaSparkHive { public static void main(String[] args) { System.setProperty("hadoop.home.dir", "D:\\software\\hadoop-2.7.4"); SparkConf sparkConf = new SparkConf(); sparkConf.setAppName("Spark SQL to Hive") .set("hive.metastore.uris", "thrift://10.202.77.200:9083") .setMaster("local[*]"); SparkSession spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate(); Dataset ds=spark.sql("select * from dw_inc_ubas.test_lsm"); ds.show(); spark.stop(); } }
大功告成,可以拿到hive表的数据。如下所示:
