正则表达式----(re库)
下面是Python中正则表达式的一些匹配规则,图片资料来自CSDN
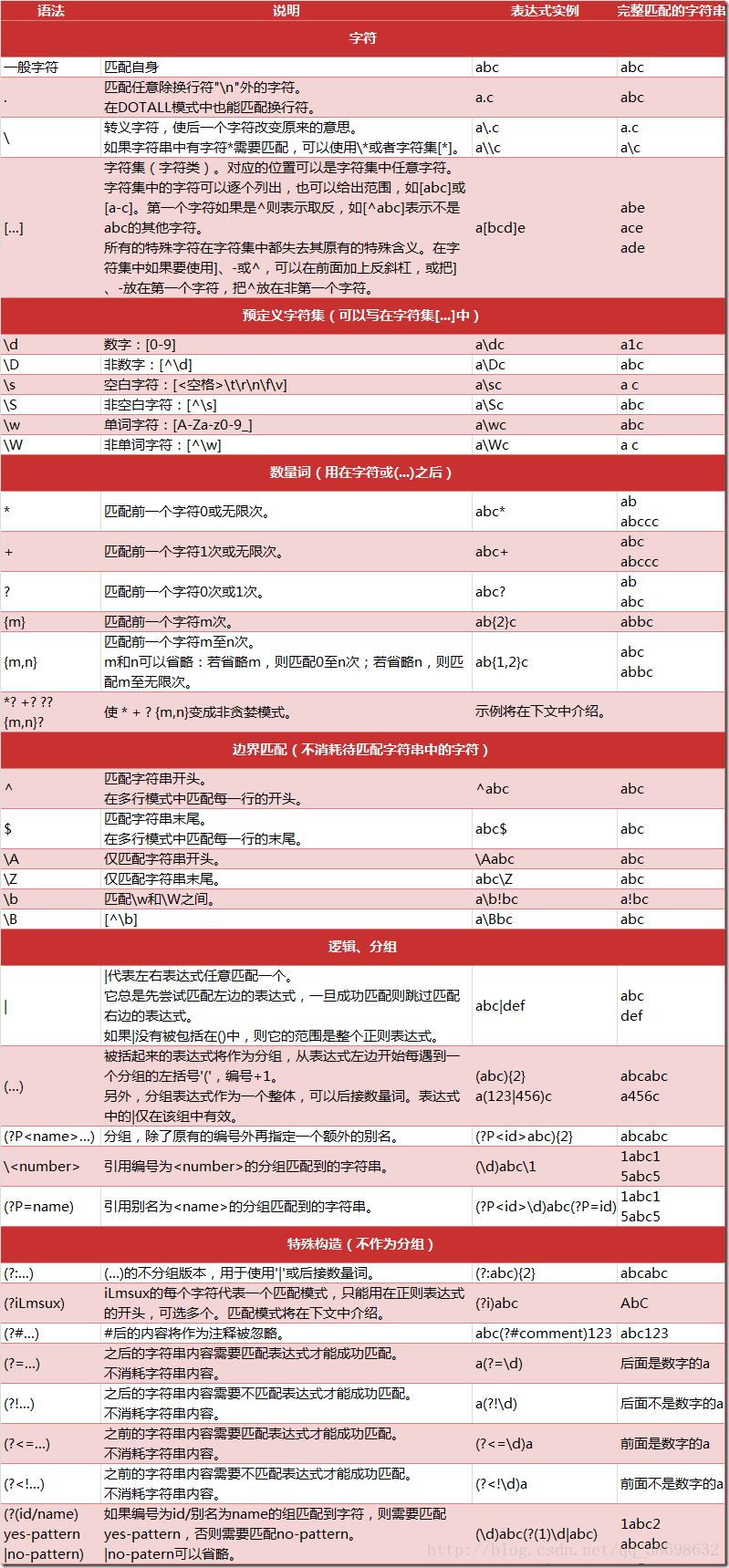
{kind=link}
# -*- coding: utf-8 -*-
import re#1.match()
# 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”
pattern = re.compile(r'hello')
# 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
result1 = re.match(pattern,'hello')
result2 = re.match(pattern,'helloo')
result3 = re.match(pattern,'helo')
result4 = re.match(pattern,'hello')
#如果1匹配成功
if result1:
# 使用Match获得分组信息
print result1.group()
else:
print '1匹配失败!'
#如果2匹配成功
if result2:
# 使用Match获得分组信息
print result2.group()
else:
print '2匹配失败!'
#如果3匹配成功
if result3:
# 使用Match获得分组信息
print result3.group()
else:
print '3匹配失败!'
#如果4匹配成功
if result4:
# 使用Match获得分组信息
print result4.group()
else:
print '4匹配失败!'
#2.re.search(pattern,string[,flags])
与match类似,区别在于match函数只检测re是不是在string的开始位置匹配,search会扫描整个string查找匹配
match只有在0位置匹配成功才返回;
#如果用match就错了
pattern=re.compile(r'world')
match=re.search(pattern,'hello world')
if match:
print match.group()
#3.re.split(pattern,string[,maxsplit])
#按照能过匹配的字符串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割
pattern=re.compile(r'\d+')
print re.split(pattern,'one1two1free234four33')
#4.re.findall(pattern,string[,flags])
#搜索string,以列表形式返回全部能匹配的子串
pattern=re.compile(r'\d+')
print re.findall(pattern,'1one2two3three4four4')
#5.re.finditer(pattern,string[,flags])
#搜索string,返回一个顺序访问每一个匹配结果的迭代器
pattern=re.compile(r'\d+')
for i in re.finditer(pattern,'one2two3three4four4'):
print i.group()
#以上内容根据静觅博客的内容进行学习
python os.path模块(原文链接 http://www.cnblogs.com/dkblog/archive/2011/03/25/1995537.html )
os.path.abspath(path) #返回绝对路径
os.path.basename(path) #返回文件名
os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径。
os.path.dirname(path) #返回文件路径
os.path.exists(path) #路径存在则返回True,路径损坏返回False
os.path.lexists #路径存在则返回True,路径损坏也返回True
os.path.expanduser(path) #把path中包含的"~"和"~user"转换成用户目录
os.path.expandvars(path) #根据环境变量的值替换path中包含的”$name”和”${name}”
os.path.getatime(path) #返回最后一次进入此path的时间。
os.path.getmtime(path) #返回在此path下最后一次修改的时间。
os.path.getctime(path) #返回path的大小
os.path.getsize(path) #返回文件大小,如果文件不存在就返回错误
os.path.isabs(path) #判断是否为绝对路径
os.path.isfile(path) #判断路径是否为文件
os.path.isdir(path) #判断路径是否为目录
os.path.islink(path) #判断路径是否为链接
os.path.ismount(path) #判断路径是否为挂载点()
os.path.join(path1[, path2[, ...]]) #把目录和文件名合成一个路径
os.path.normcase(path) #转换path的大小写和斜杠
os.path.normpath(path) #规范path字符串形式
os.path.realpath(path) #返回path的真实路径
os.path.relpath(path[, start]) #从start开始计算相对路径
os.path.samefile(path1, path2) #判断目录或文件是否相同
os.path.sameopenfile(fp1, fp2) #判断fp1和fp2是否指向同一文件
os.path.samestat(stat1, stat2) #判断stat tuple stat1和stat2是否指向同一个文件
os.path.split(path) #把路径分割成dirname和basename,返回一个元组
os.path.splitdrive(path) #一般用在windows下,返回驱动器名和路径组成的元组
os.path.splitext(path) #分割路径,返回路径名和文件扩展名的元组
os.path.splitunc(path) #把路径分割为加载点与文件
os.path.walk(path, visit, arg) #遍历path,进入每个目录都调用visit函数,visit函数必须有
3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有
文件名,args则为walk的第三个参数
os.path.supports_unicode_filenames #设置是否支持unicode路径名
os库函数部分用法 原文链接:http://blog.chinaunix.net/uid-27838438-id-4087978.html
1、os.getcwd()函数
功能:获取当前目录,python 的工作目
- import os
-
- pwd = os.getcwd()
-
- print (pwd)
2、os.name 函数
功能:获取当前使用的操作系统(获取信息不够详细)
其中 'nt' 是 windows,'posix' 是 linux 或者 unix
- import os
-
- name = os.name
-
- if name == 'posix':
-
- print ("this is Linux or Unix")
-
- elif name == 'nt':
-
- print ("this is windows")
-
- else:
-
- print ("this is other system")
功能:删除指定文件
eg:删除 file.txt 文件
- import os
-
- os.remove(’file.txt‘)
4、os.removedirs()函数
功能:删除指定目录
eg:删除 file目录
- import os
-
- os.removedirs(‘file’)
5、os.system()函数
功能:运行shell命令
eg:执行ls -a > 1.txt命令
- import os
-
- os.system(‘ls -a > 1.txt’)
6、os.mkdir()函数
功能:创建一个新目录
eg:创建一个 file 目录
- import os
-
- os.mkdir(‘file’)
7、os.chdir()函数
功能:改变当前路径到指定路径
eg:我现在从当前路径到 filepath 所指定的路径下
- import os
-
- filepath = '/home'
-
- pwd = os.getcwd()
-
- print (pwd)
-
- os.chdir(filepath)
-
- pwd = os.getcwd()
-
- print (pwd)
8、os.listdir()函数
功能:返回指定目录下的所有目录和文件
eg:列出当前目录下的所有文件和目录
- import os
-
- pwd = os.getcwd()
-
- name = os.listdir(pwd)
-
- for filename in name:
-
- print (filename)