本篇博文将详细总结贪心和动态规划部分,贪心和动态规划是非常难以理解和掌握的,但是在笔试面试中经常遇到,关键还是要理解和掌握其思想,然后就是多刷刷相关一些算法题就不难了。本篇将会大篇幅总结其算法思想。
贪心和动态规划思想
马尔科夫模型
对于
相应的,对于

高阶马尔科夫模型的推理,叫做“动态规划”,而马尔科夫模型的推理,对应“贪心法”。
无后效性
- 计算
A[i] 时只读取A[0…i−1] ,不修改——历史 - 计算
A[i] 时不需要A[i+1…n−1] 的值——未来
理解贪心,动态规划:
动态规划:
可以如下理解动态规划:计算
贪心:
根据实际问题,选取一种度量标准。然后按照这种标准对
这一处理过程一直持续到
字符串回文划分问题
问题描述
给定一个字符串
单个字符构成的字符串,显然是回文串;所以,这个的划分一定是存在的。
如:
方法一:深度优先搜索
思考:若当前计算得到了
剪枝:在每一步都可以判断中间结果是否为合法结果。
- 回溯+剪枝——如果某一次发现划分不合法,立刻对该分支限界。
- 一个长度为
n 的字符串,最多有n−1 个位置可以截断,每个位置有两种选择,因此时间复杂度为O(2n−1)=O(2n) 。
在利用
线性探索:
j 从i 到n−1 遍历即可,从字符串str[i,i+1,...,j] 两端开始比较,然后得出是否对称回文。事先缓存所有
str[i,i+1,..,j] 是回文串的那些记录,用二维布尔数组p[n][n] 的true/false 表示str[i,i+1,...,j] 是否是回文串。它本身是个小的动态规划:如果已知
str[i+1,...,j−1] 是回文串,那么判断str[i,i+1,...,j] 是否是回文串,只需要判断str[i]==str[j] 就可以了。
// 判断str[i,j]回文与否
void CalcSubstringPalindrome(const char* str, int size, vector<vector<bool>>& p)
{
int i, j;
for (i = 0; i < size; i++)
p[i][i] = true;//单个字符肯定是回文串
for (i = size - 2; i >= 0; i--)
{
p[i][i + 1] == (str[i] == str[i + 1]);//得出字符串内每两个相邻字符回文与否,也就是得出初始状态
for (j = i + 2; j < size; j++)//以i子串左端并且在内循环i固定,j为子串右端,并且j不断向外扩展,
//递进的判断str[i,j]回文与否
{
if ((str[i] == str[j]) && p[i + 1][j - 1])
p[i][j] = true;
}
}
}
//以str[nStart]为起点,不断的判断str[nSart,i]回文与否,若是回文加入solution
void FindSolution(const char* str, int size, int nStart, vector<vector<string>>& all, vector<string>& solution, const vector<vector<bool>>& p)
{
if (nStart >= size)//表示当前方向递归深入到头
{
all.push_back(solution);//将当前方向的所有回文压入到all
return;
}
for (int i = nStart; i < size; i++)
{
if (p[nStart][i])
{
solution.push_back(string(str + nStart, str + i + 1));
FindSolution(str, size, i + 1, all, solution, p);//沿着这个方向深入递归
solution.pop_back();//回溯到当前初始状态,选择其他方向
}
}
}
void MinPalindrome3(const char* str, vector<vector<string>>& all)
{
int size = (int)strlen(str);
vector<vector<bool>> p(size, vector<bool>(size));
CalcSubstringPalindrome(str, size, p);
vector<string> solution;
FindSolution(str, size, 0, all, solution, p);
}方法二:动态规划
如果已知:
算法:
- 将集合
φ(i+1) 置空; - 遍历
j(0≤j<i) ,若str[j,j+1…i] 是回文串,则将str[j…i] 添加到φ(j−1) ,然后再把φ(j−1) 添加到φ(i+1) 中; -
i 从0 到n ,依次调用上面两步,最终返回φ(n) 即为所求。
//to 表示prefix[i],长度为i的回文集合;from表示prefix[j]长度为j的回文集合;sub表示要添加的回文str[j,i]
void Add(vector<vector<string>>& to, const vector<vector<string>>& from, const string& sub)
{
if (from.empty())//from 为空时,直接将sub压入to
{
to.push_back(vector<string>(1, sub));//vector<string>(1, sub):初始化vector,长度为1,一个字符串sub
return;
}
to.reserve(from.size());
for (vector<vector<string>>::const_iterator it = from.begin(); it != from.end(); it++)//遍历from里面每个回文
{
to.push_back(vector<string>());
vector<string>& now = to.back();
now.reserve(it->size() + 1);
//将from某个个回文里面的每个字符依次压入now,然后在末尾加上要添加的回文子串sub
for (vector<string>::const_iterator s = it->begin(); s != it->end(); s++)
now.push_back(*s);
now.push_back(sub);
}
}
void MinPalindrome4(const char* str, vector<vector<string>>& all)
{
int size = (int)strlen(str);
vector<vector<bool>> p(size, vector<bool>(size));
CalcSubstringPalindrome(str, size, p);
vector<vector<string>>* prefix = new vector<vector<string>>[size];//注意这里是vector<vector>* 相当于一个三维数组
prefix[0].clear();
int i, j;
for (i = 1; i <= size; i++)
{
for (j = 0; j < i; j++)
{
if (p[j][i - 1])//prefix[i]表示长度为i的回文集合,这里是指长度,那么索引应该到i-1
{
Add((i == size) ? all : prefix[i], prefix[j], string(str + j, str + i));
}
}
}
delete[] prefix;
}DFS和DP的深刻认识
- 显然
DFS 比DP 好理解,而代码上DP 更加简洁。 -
DFS 的过程,是计算完成了str[0…i] 的切分,然后递归调用,继续计算str[i+1,i+2…n−1] 的过程; - 而
DP 中,假定得到了str[0…i−1] 的所有可能切分方案,如何扩展得到str[0…i] 的切分; - 上述两种方法都可以从后向前计算得到对偶的分析。
从本质上说,二者是等价的:最终都搜索了一颗隐式树。
-
DFS 显然是深度优先搜索的过程,而DP 更像层序遍历 的过程。 - 如果只计算回文划分的最少数目,动态规划更有优势;如果计算所有回文划分,
DFS 的空间复杂度比DP 略优。
利用贪心思想的几个重要算法
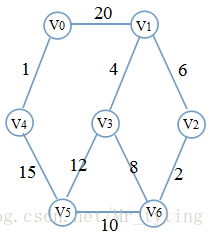
最小生成树MST
最小生成树要求从一个带权无向连通图中选择
Prim算法
实例:
实现代码:
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#define MAXINT 6
using namespace std;
//声明一个二维数组,C[i][j]存储的是点i到点j的边的权值,如果不可达,则用1000表示
//借此二维数组来表示一个连通带权图
int c[MAXINT][MAXINT] = { { 1000, 6, 1, 5, 1000, 1000 }, { 6, 1000, 5, 1000, 3, 1000 }, { 1, 5, 1000, 5, 6, 4 }, { 5, 1000, 5, 1000, 1000, 2 }, { 1000, 3, 6, 1000, 1000, 6 }, { 1000, 1000, 4, 2, 6, 1000 } };
void Prim(int n)
{
int lowcost[MAXINT];//lowcost[i]表示V-S中的点i到达S的最小权值
int closest[MAXINT];//closest[i]表示V-S中的点i到达S的最小权值S中对应的点
bool s[MAXINT];//bool型变量的S数组表示i是否已经包括在S中
int i, k;
s[0] = true;//从第一个结点开始寻找,扩展
for (i = 1; i <= n; i++)//简单初始化,这个时候S为{0},V-S为{1,2,3,4,5}
{
lowcost[i] = c[0][i];//这个时候S中只有0
closest[i] = 0;//现在所有的点对应的已经在S中的最近的点是1
s[i] = false;
}
cout << "0->";
for (i = 0; i<n; i++)//执行n次,也即是向S中添加所有的n个结点
{
int min = 1000;//最小值,设大一点的值,后面用来记录lowcost数组中的最小值
int j = 1;
for (k = 1; k <= n; k++)//寻找lowcost中的最小值,并且找出此时V-S中对应的点j
{
if ((lowcost[k]<min) && (!s[k]))
{
min = lowcost[k]; j = k;
}
}
cout << j << " " << "->";
s[j] = true;//添加点j到集合S中
for (k = 1; k <= n; k++)//因为新加入了j点,需要更新V-S到S的最小权值,只需要与刚加进来的c[j][k]比较即可
{
if ((c[j][k]<lowcost[k]) && (!s[k])){ lowcost[k] = c[j][k]; closest[k] = j; }
}
}
}
int main()
{
Prim(MAXINT - 1);
return 0;
}
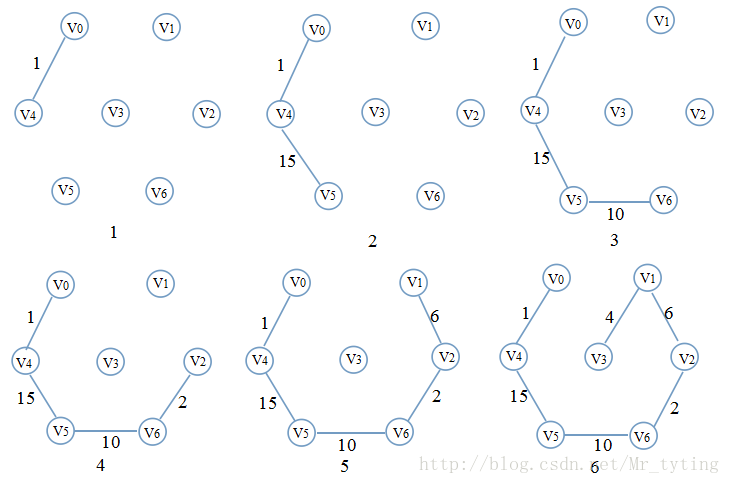
Kruskal算法
实例:
在实现
基于
实现代码:
#include <iostream>
#include <vector>
#include <algorithm>
#include <fstream>
using namespace std;
struct Edge
{
int u; //边连接的一个顶点编号
int v; //边连接另一个顶点编号
int w; //边的权值
friend bool operator<(const Edge& E1, const Edge& E2)
{
return E1.w < E2.w;
}
};
//创建并查集,uset[i]存放结点i的根结点,初始时结点i的根结点即为自身
void MakeSet(vector<int>& uset, int n)
{
uset.assign(n, 0);
for (int i = 0; i < n; i++)
uset[i] = i;
}
//查找当前元素所在集合的代表元
int FindSet(vector<int>& uset, int u)
{
int i = u;
while (uset[i] != i) i = uset[i];
return i;
}
void Kruskal(const vector<Edge>& edges, int n)
{
vector<int> uset;
vector<Edge> SpanTree;
int Cost = 0, e1, e2;
MakeSet(uset, n);
for (int i = 0; i < edges.size(); i++) //按权值从小到大的顺序取边
{
e1 = FindSet(uset, edges[i].u);
e2 = FindSet(uset, edges[i].v);
if (e1 != e2) //若当前边连接的两个结点在不同集合中,选取该边并合并这两个集合,如果相等连接则成环
{
SpanTree.push_back(edges[i]);
Cost += edges[i].w;
uset[e1] = e2; //合并当前边连接的两个顶点所在集合
}
}
cout << "Result:\n";
cout << "Cost: " << Cost << endl;
cout << "Edges:\n";
for (int j = 0; j < SpanTree.size(); j++)
cout << SpanTree[j].u << " " << SpanTree[j].v << " " << SpanTree[j].w << endl;
cout << endl;
}
int main()
{
int n, m;
cin >> n >> m;
vector<Edge> edges;
edges.assign(m, Edge());
for (int i = 0; i < m; i++)
cin >> edges[i].u >> edges[i].v >> edges[i].w;
sort(edges.begin(), edges.end()); //排序之后,可以以边权值从小到大的顺序选取边
Kruskal(edges, n);
system("pause");
return 0;
} Dijkstra最短路径算法
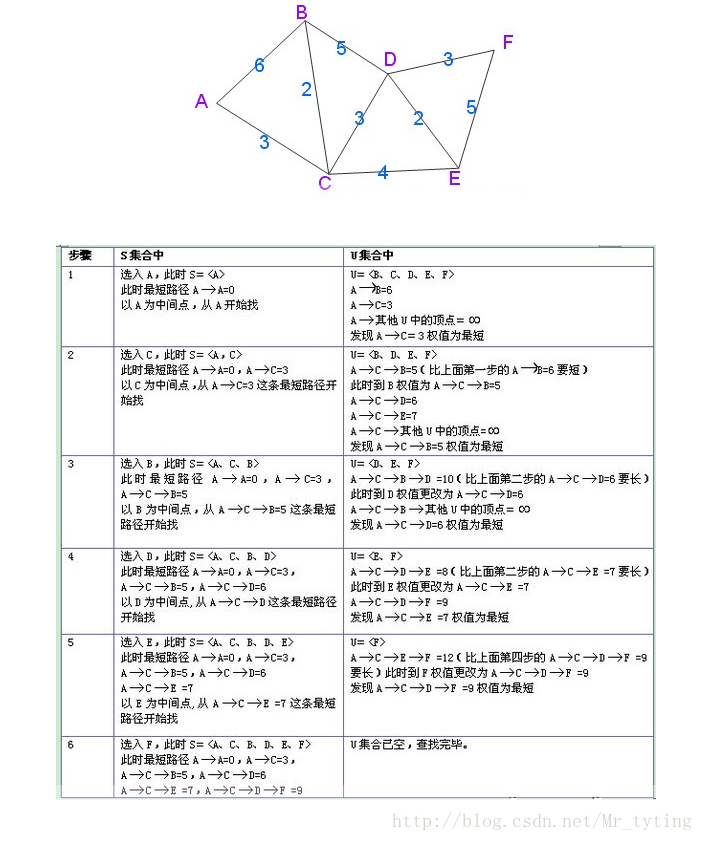
该算法为单源点最短路径算法,要求边的权值为正数。在图
S 为已经找到的从v0 出发的最短路径的终点集合,它的初始状态为空集,那么从v0 出发到图中其余各顶点(终点)vi(vi∈V−S) ,记arcs[i][j] 为结点vi 直接到达 结点vj 的距离。记d[j] 为源点v0 到达结点vj 的最短距离。初始时:d[j]=arcs[0][j] 选择
vj ,使得d[j]=minj(d[i],vi∈V−S),vj 就是当前求得的一条从v0 出发的最短路径的终点。令S=S∪j ;修改从
v0 出发到集合V−S 上任一顶点vk 可达的最短路径长度。如果d[j]+arcs[j][k]<d[k] , 则修改d[k] 为:d[k]=d[j]+arcs[j][k] ;以上
2,3 步骤重复n−1 次。
在网上找了个
实现代码:
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#include<set>
#include<queue>
using namespace std;
const int MAXINT = 32767;
const int MAXNUM = 10;//结点总数
int d[MAXNUM];//单源点到其他结点的最短路径
int prev[MAXNUM];//记录前驱结点
int arcs[MAXNUM][MAXNUM];//邻接矩阵,arcs[i][j]也即是两结点(vi,vj)之间的直接距离
void Dijkstra(int v0, int* prev)//源点 v0
{
bool S[MAXNUM];// 判断是否已存入该点到S集合中
int n = MAXNUM;
for (int i = 1; i <= n; ++i)
{
d[i] = arcs[v0][i];//初始时最短距离为直接距离
S[i] = false;// 初始都未用过该点
if (d[i] == MAXINT)
prev[i] = -1;
else
prev[i] = v0;
}
d[v0] = 0;
S[v0] = true;//S集合中加入v0
for (int i = 2; i <= n; i++)
{
int mindist = MAXINT;
int u = v0; // 找出当前未使用的点j的dist[j]最小值
for (int j = 1; j <= n; ++j)
if ((!S[j]) && d[j] < mindist)
{
u = j; // u为在V-S中到源点v0的最短距离对应的结点
mindist = d[j];
}
S[u] = true;//将u加入到S中
//更新其他结点到单源点的最短距离,查看其他结点经过u到单源点的距离会不会比之前单元点的直接距离要短
for (int j = 1; j <= n; j++)
if ((!S[j]) && arcs[u][j]<MAXINT)
{
if (d[u] + arcs[u][j] < d[j])//在通过新加入的u点路径找到离v0点更短的路径
{
d[j] = d[u] + arcs[u][j]; //更新dist
prev[j] = u; //记录前驱顶点
}
}
}
}总结
Prim算法与贪心
Kruskal算法与贪心
对边的权值进行从小到大的排序,依次加入小的权值边,且不能形成环,我们把边的集合
Dijkstra算法与贪心
只需要对
以上几种算法的状态转移示意图如下,是一个马尔科夫过程:

可以看到,在从
最长递增子序列LIS
在字符串部分我们详解过这个问题,利用的是最长公共子序列解的,现在我们尝试利用动态规划解。
以序列
前缀分析
以
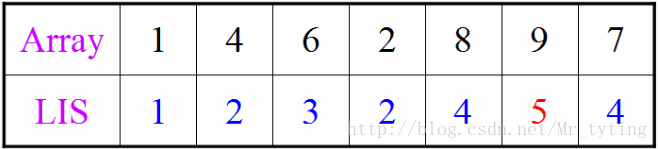
显然以
LIS记号
长度为
记
假定已经计算得到了
已知
求解LIS
根据定义,
从而:
- 计算
b[i] :遍历在i 之前的所有位置j ,找出满足条件aj≤ai 的最大的b[j]+1 ; - 计算得到
b[0…n−1] 后,遍历所有的b[i] ,找出最大值即为最大递增子序列的长度。
时间复杂度为
实现代码
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#include<set>
#include<queue>
#include<algorithm>
using namespace std;
int LIS(const int *p, int length, int *pre, int& nIndex)
{
int* longest = new int[length];//longest[i]表示以p[i]结尾的递增序列长度
int i, j;
for (i = 0; i < length; i++)
{
longest[i] = 1;//初始时以每个字符结尾的递增序列长度都为1
pre[i] = -1;
}
int nLst = 1;//最长的递增子序列长度
nIndex = 0;
for (i = 1; i < length; i++)
{
for (j = 0; j < i; j++)
{
if (p[j] <= p[i])
{
if (longest[i] < longest[j] + 1)
{
longest[i] = longest[j] + 1;
pre[i] = j;//记录前驱
}
}
}
if (nLst < longest[i])//记录所有的递增子序列里面最长的长度
{
nLst = longest[i];
nIndex = i;//nIndex记录最长递增子序列最后一个结点
}
}
delete[] longest;
return nLst;
}
void GetLIS(const int* array, const int* pre, int nIndex, vector<int>& lis)
{
while (nIndex>=0)//nIndex为最长递增子序列最后一个结点
{
lis.push_back(array[nIndex]);
nIndex = pre[nIndex];
}
reverse(lis.begin(), lis.end());//逆向输出
}
void Print(int *p, int size)
{
for (int i = 0; i < size; i++)
cout << p[i]<<" ";
cout << endl;
}
int main()
{
int array[] = { 1, 4, 5, 6, 2, 3, 8, 9, 10, 11, 12, 12, 1 };
int size = sizeof(array) / sizeof(int);
int* pre = new int[size];
int nIndex;
int max = LIS(array, size, pre, nIndex);
vector<int> lis;
GetLIS(array, pre, nIndex, lis);
delete[] pre;
cout << max << endl;
Print(&lis.front(), (int)lis.size());
return 0;
}矩阵乘积
问题描述
根据矩阵相乘的定义来计算
三个矩阵A、B、C的阶分别是
问题分析
可以利用矩阵乘法的结合律 来降低乘法的计算量。
给定
将矩阵连乘积记为
A[i:j] ,这里i≤j ,显然,若i==j ,则A[i:j] 即A[i] 本身。考察计算
A[i:j] 的最优计算次序。设这个计算次序在矩阵Ak 和Ak+1 之间将矩阵链断开,i≤k<j ,则其相应的完全加括号方式为:(Ai,Ai+1...Ak)(Ak+1,Ak+2,...,Aj) 计算量:
A[i:k] 的计算量加上A[k+1:j] 的计算量,再加上A[i:k] 和A[k+1:j] 相乘的计算量。
最优子结构
特征:计算
矩阵连乘计算次序问题的最优解包含着其子问题的最优解。这种性质称为最优子结构性质。
最优子结构性质是可以使用动态规划算法求解的显著特征。
状态转移方程
设计算
A[i:j](1≤i≤j≤n) 所需要的最少数乘次数为m[i,j] ,则原问题的最优值为m[1,n] ;记
Ai 的维度为pi−1∗pi 当
i==j 时,A[i:j] 即Ai 本身,因此,m[i,i]=0;(i=1,2,…,n) 当
i<j 时有:
k 遍历(i,j) ,找到一个使得计算量最小的k,也即是:
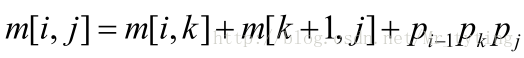
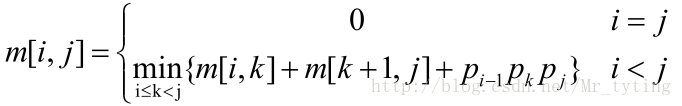
实现代码
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#include<set>
#include<queue>
#include<algorithm>
using namespace std;
//p[0,..,n]存储n+1个数,其中(p[i-1],p[i])是矩阵i的阶
//s[i][j]记录了矩阵i连乘到矩阵j应该在哪断开;m[i][j]记录了矩阵i连乘到矩阵j最小计算量
void MatrixMultiply(int* p, int n, int** m, int** s)
{
int r, i, j, k, t;
for (i = 1; i <= n; i++)
m[i][i] = 0;
//r个连续矩阵相乘,r不断扩展,不断计算任意两点之间最优断开点,最小计算量
for (r = 2; r <= n; r++)
{
for (i = 1; i <= n - r + 1; i++)
{
j = i + r - 1;
m[i][j] = m[i][i]+m[i + 1][j] + p[i - 1] * p[i] * p[j];//初始值,第一项m[i][i]=0
s[i][j] = i;//初始在i处断开
for (k = i + 1; k < j; k++)
{
t = m[i][k] + m[k + 1][j] + p[i - 1] * p[k]*p[j];
if (t < m[i][j])
{
m[i][j] = t;//(i,j)最小计算量
s[i][j] = k;//记录(i,j)中最优断开点
}
}
}
}
}找零钱问题
问题描述
给定某不超过
问题分析
此问题涉及两个类别:面额和总额。
- 如果面额都是
1 元的,则无论总额多少,可行的组合数显然都为1 。 - 如果面额多一种,则组合数有什么变化呢?
定义
dp[100][500]=dp[50][500]+dp[100][400]
dp[50][500] :50 以下的面额的组成500 是一种组合方式,这里面就包括了dp[20][500],dp[10][500]等
dp[100][400] :表示首先拿出100 的面额,剩余的400 用小于等于100 的面额组合。
上述两种组合方式没有包含关系,两种组合合在一起组成所有的组合方式。dp[i][j]=dp[ismall][j]+dp[i][j−i]
如果把i 看成数组下标,则有:dp[i][j]=dp[i−1][j]+dp[i][j−dom[i]]
递推公式
使用
dom[]=1,2,5,10,20,50,100 表示基本面额,i 的意义从面额变成面额下标,则:dp[i][j]=dp[i−1][j]+dp[i][j−dom[i]] 从而有:
初始条件( 注意都为1,而不是0):
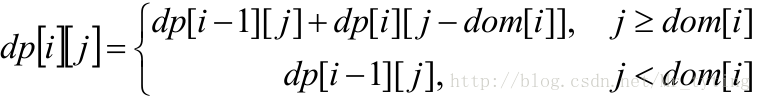
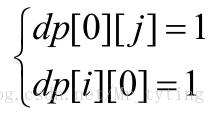
按照上面的状态转移方差我们可以从初始状态一直推导到终止状态
实现代码
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#include<set>
#include<queue>
#include<algorithm>
using namespace std;
int Charge(int value, const int* denomination, int size)
{
int i;//i是下标
int** dp = new int*[size];//dp[i][j]:用i面额以下的组合成j元
for (i = 0; i < size; i++)
dp[i] = new int[value + 1];
int j;
for (j = 0; j <= value; j++)//i=0表示用面额1元的
dp[0][j] = 1;//这个时候只有一种组合方式
for (i = 1; i < size; i++)//先用面额小的,再用面额大的
{
dp[i][0] = 1;//添加任何一种面额,都是一种组合
for (j = 1; j <= value; j++)//先组合小的,然后扩展,在小的基础上一直组合到dp[size-1][value]
{
if (j >= denomination[i])
dp[i][j] = dp[i-1][j]+dp[i][j-denomination[i]];
else
dp[i][j] = dp[i - 1][j];
}
}
int time = dp[size - 1][value];
//清理内存
for (i = 0; i < size; i++)
delete[] dp[i];
return time;
}
int main()
{
int denomination[] = { 1, 2, 5, 10, 20, 50, 100 };
int size = sizeof(denomination) / sizeof(int);
int value = 200;
int c = Charge(value, denomination, size);
cout << c << endl;
return 0;
}滚动数组
将状态转移方程去掉第一维,很容易使用滚动数组,降低空间使用量。
原状态转移方程:
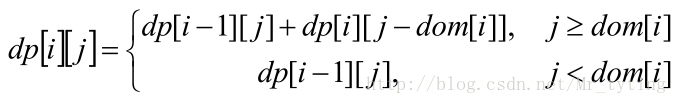
滚动数组版本的状态转移方程:

这个
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<algorithm>
using namespace std;
int Charge2(int value, const int* denomination, int size)
{
int i;//i是下标
int* dp = new int[value+1];//dp[i][j]:用i面额以下的组合成j元
int* last = new int[value + 1];
int j;
for (j = 0; j <= value; j++)//只用面额1元的
{
dp[j] = 1;
last[j] = 1;
}
for (i = 1; i < size; i++)
{
for (j = 1; j <= value; j++)
{
if (j >= denomination[i])
dp[j] = last[j] + dp[j - denomination[i]];
}
memcpy(last, dp, sizeof(int)*(value + 1));//相当于dp[i-1][j] 赋值给last
}
int times = dp[value];
delete[] last;
delete[] dp;
return times;
}
int main()
{
int denomination[] = { 1, 2, 5, 10, 20, 50, 100 };
int size = sizeof(denomination) / sizeof(int);
int value = 200;
int c = Charge2(value, denomination, size);
cout << c << endl;
return 0;
}在动态规划的问题中,如果不求具体解的内容,而只是求解的数目,往往可以使用滚动数组的方式降低空间使用量(甚至空间复杂度),由于滚动数组减少了维度,甚至代码会更简单,但是代码会更加难以理解。
走棋盘/格子取数
问题描述
给定
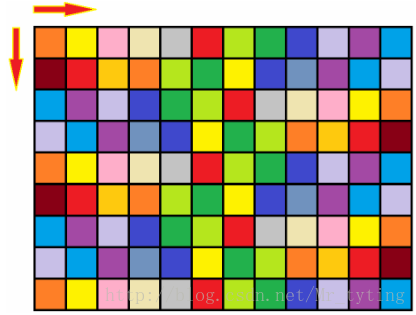
状态转移方程
走的方向决定了同一个格子不会经过两次。
- 若当前位于
(x,y) 处,它来自于哪些格子呢? -
dp[x,y] 表示从起点走到坐标为(x,y) 的方格的最小权值。 -
dp[0,0]=a[0,0] , 第一行(列)累积 -
dp[x,y]=min(dp[x−1,y]+a[x,y],dp[x,y−1]+a[x,y]) - 即:
dp[x,y]=min(dp[x−1,y],dp[x,y−1])+a[x,y]
状态转移方程:
在上边界时只能向右走,在左边界时只能向下走。
滚动数组去除第一维:
实现代码
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int MinPath(vector<vector<int>> &chess, int M, int N)
{
vector<int> pathLength(N);
int i, j;
//初始化
pathLength[0] = chess[0][0];
for (j = 1; j < N; j++)
pathLength[j] = pathLength[j - 1] + chess[0][j];
//依次计算每行
for (i = 1; i < M; i++)
{
pathLength[0] += chess[i][0];
for (j = 1; j < N; j++)
{
if (pathLength[j - 1] < pathLength[j])
pathLength[j] = pathLength[j - 1] + chess[i][j];
else
pathLength[j] += chess[i][j];
}
}
return pathLength[N - 1];
}
int main()
{
const int M = 10;
const int N = 8;
vector<vector<int>> chess(M, vector<int>(N));
//初始化棋盘(随机给定)
int i, j;
for (i = 0; i < M; i++)
{
for (j = 0; j < N; j++)
chess[i][j] = rand() % 100;
}
cout << MinPath(chess, M, N) << endl;
return 0;
}带陷阱的走棋盘问题
问题分析
在
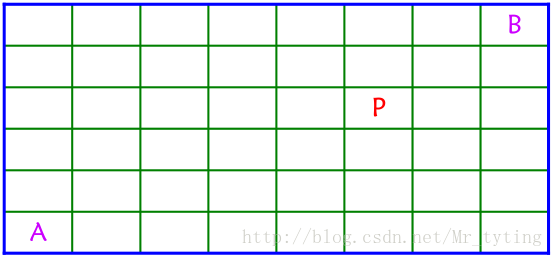
状态转移方程
-
dp[i][j] 表示从起点到(i,j) 的路径条数。 - 只能从左边或者上边进入一个格子。
- 如果
(i,j) 被占用,dp[i][j]=0 - 如果
(i,j) 不被占用,dp[i][j]=dp[i−1][j]+dp[i][j–1]
故状态转移方程:
一共要走
问题解决

我们把
实现代码
#include<stdio.h>
#include <stdlib.h>
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int MinPath(vector<vector<int>> dp,int M, int N)
{
int i, j;
//在左边界和下边界上的点路径都只有1
for (i = 0; i < M+1; i++)
dp[i][0] = 1;
for (j = 0; j < N+1; j++)
dp[0][j] = 1;
for (i = 1; i < M+1; i++)
{
for (j = 1; j < N+1; j++)
{
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[M][N];
}
int main()
{
const int M = 6;
const int N = 8;
vector<vector<int>> dp(M, vector<int>(N));
int x = 3;
int y = 5;
int allPath = MinPath(dp,M-1, N-1);//从起点到终点的所有路径
int path1 = MinPath(dp,x, y);//起点到占用点所有路径
int path2 = MinPath(dp, M-x-1, N-y-1);//从占用点到终点的所有路径
int path = allPath - path1*path2;//在所有路径中除去经过占用点路径数
cout << path << endl;
return 0;
}动态规划总结
动态规划是方法论,是解决一大类问题的通用思路。事实上,很多内容都可以归结为动态规划的思想。
何时可以考虑使用动态规划:
初始规模下能够方便的得出结论
空串、长度为0的数组、自身等’能够得到问题规模增大导致的变化
递推式——状态转移方程
在实践中往往忽略无后效性
哪些题目不适合用动态规划?
- 状态转移方程 的推导,往往陷入局部而忽略全局。在重视动态规划的同时,别忘了从总体把握问题。