最近研究了一下目标检测的fasterRCNN算法,虽然已经是几年前的算法了,但还是有点难理解,自己看了一周才大概理明白,如果有什么不对的地方还请大家指出,讨论学习。
进入正题,fasterRCNN目标检测这一系列代码,是从RCNN演变过来的,具体线路是RCNN——SPPNet——fastRCNN——fasterRCNN,现在好像还有maskRCNN和denseRCNN,越新的肯定效果越好,不过我只研究了fasterRCNN之前的算法,就说说我对fasterRCNN的理解。
fastRCNN
要懂FasterRCNN,首先要讲fastRCNN的知识,因为fasterRCNN相当于是在fastRCNN上加了一个RPN区域建议框网络。那我们先看fastRCNN。上一张自己画的fastRCNN的网络图

首先,对任意size的图片,通过经典的网络(VGG,ResNet)进行卷积激活池化等操作,将网络的最后某层选为feature map(不同网络有不同的feature map层,例如ResNet是conv4_x)。这时,由selective search算法生成大约2k个区域建议框作用于feature map,这个区域建议框就是用来预测目标位置的(这个区域建议框生成算法是fastRCNN和fasterRCNN不一样的地方)。把区域建议框作用于之前得到的feature map,通过ROI池化层,可以得到统一大小H×W的图片,方便后面全连接层的使用。这里的ROI的意思,比如,我第一个框大小是12×12的,第二个框大小是6×6的,但是我统一的H×W大小为3×3。那么,对第一个框,我对4×4的区域进行maxpooling,结果为3×3;对第二个框,我对2×2的区域进行maxpooling,这样结果也是3×3的,这样就可以统一为H×W大小的特征图了。后面通过几个全连接层,分为两路,一路预测目标类别,一路预测目标边界框的4个坐标。
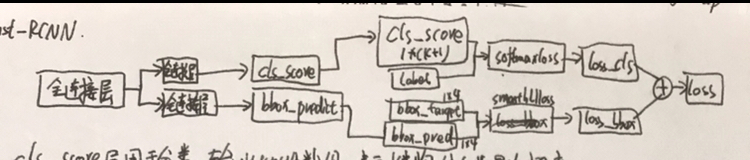
然后对两路预测分别建立损失函数,然后把两个损失函数相加,这就是fastRCNN最突出的贡献点,对最终的损失求梯度,一步优化整个网络。对类别的预测,我们用softmaxloss函数,假如有K+1个类,K个前景类和1个背景类,softmax函数可以得到K+1个类对应的概率值,训练的时候我们通过标注知道图片的具体类别,则对应类别的概率Pu的log损失即为Lcls,Lcls=-logPu。当类别预测不是背景时,我们就要对类别的边框计算回归损失,Lloc=∑g(ti-vi)。i为4,分别对应边框的4个位置信息(一说左上角x,y,右上角x,y;一说左上角xy和边框的高宽HW),ti是预测的4个坐标值,Vi为真实标注的坐标值(这个边框回归的损失函数Lloc我有点没太明白,如果有理解的朋友可以留言讨论),g()函数是smoothL1函数;当类别预测是背景时,我们就不需要计算边框的回归损失了。这样,总的损失Lloss=λLloc+Lcls;当类别是背景时,λ为0,不是背景时,λ为1。这样对Lloss求梯度进行迭代,即可优化整个fastRCNN网络结构了。
fasterRCNN
把fastRCNN理解之后呢,我们再讲fasterRCNN。看上面fastRCNN的网络,什么地方都好,但是有一点美中不足,就是区域建议框的筛选算法ss。原始论文说2k个区域建议框的生成时间没有计算,ss用cpu计算,后面的网络又使用GPU计算等等,反正就是说ss算法会阻碍整个网络的训练速度。这个时候,大牛就又想出了一个办法,单独训练了一个RPN网络(region proposal network)。用这个RPN网络来进行区域建议框的筛选,统一为GPU操作,而且耗时更短,精度更高。

(盗图一张,会在后面给出引用)。整个fasterRCNN结构如图所示,前面后面和fastRCNN基本一致。前面是用经典网络提取特征,得到feature map层,后面在ROI池化后,进行目标类别预测和边界预测,计算损失函数。唯一不同的就是在中间RPN网络。其实我个人理解也可以这样表示:
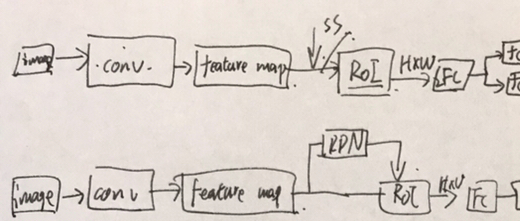
上面的网络表示的fastRCNN,下面的网络表示的fasterRCNN。RPN网络的输入也是feature map,只不过他通过feature map的输入,输出一系列的区域建议框作用于原始feature map,这样就可以在原始的feature map和输入的区域建议框上进行ROI池化,后面的就和fastRCNN一样了。
RPN网络
那我们现在来看RPN网络
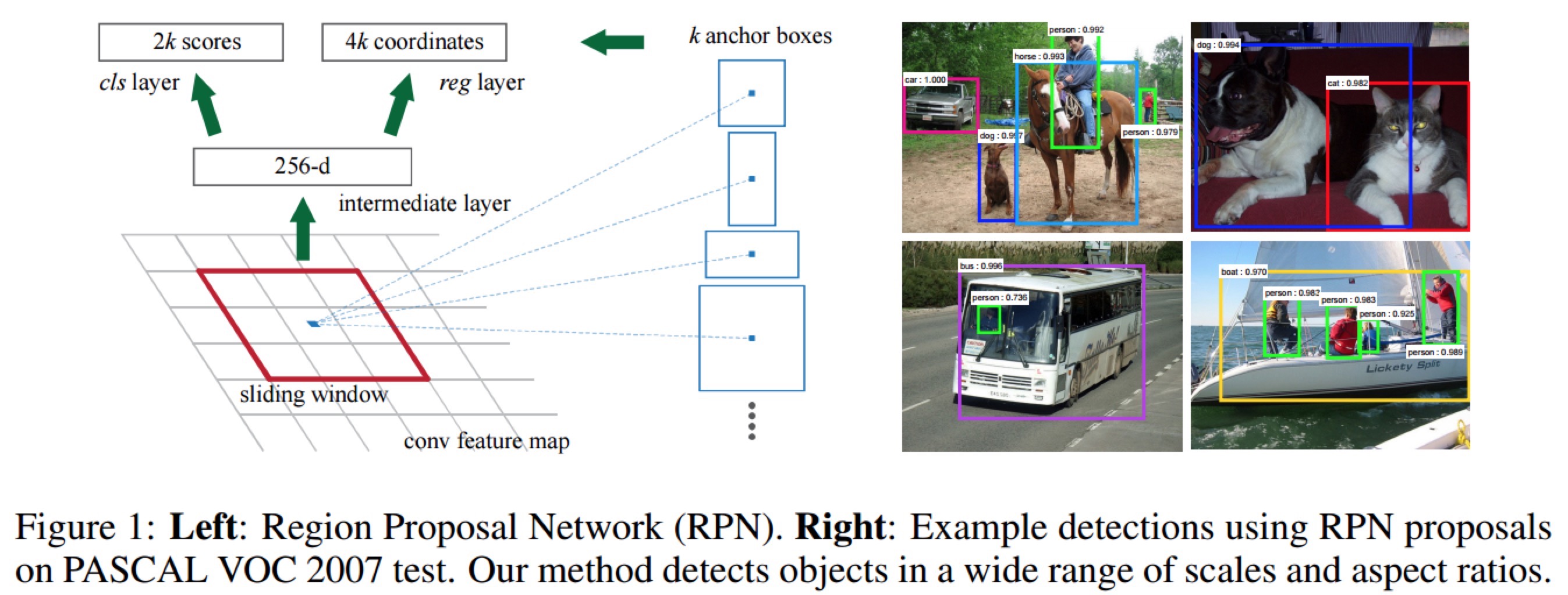
左边对应的就是RPN网络,他作用于feature map上。一系列卷积之后,通过一个sliding window进行建议框的筛选。假如原始图片是M×N大小的,sliding window是3×3的,我们设四周padding为1,这样滑窗是不是会滑过特征图的所有点,我们选滑窗的中心点做研究,将此中心点映射会最开始输入的image图片,并且对每个原始点做9个anchor,用来预测目标,如下图所示。
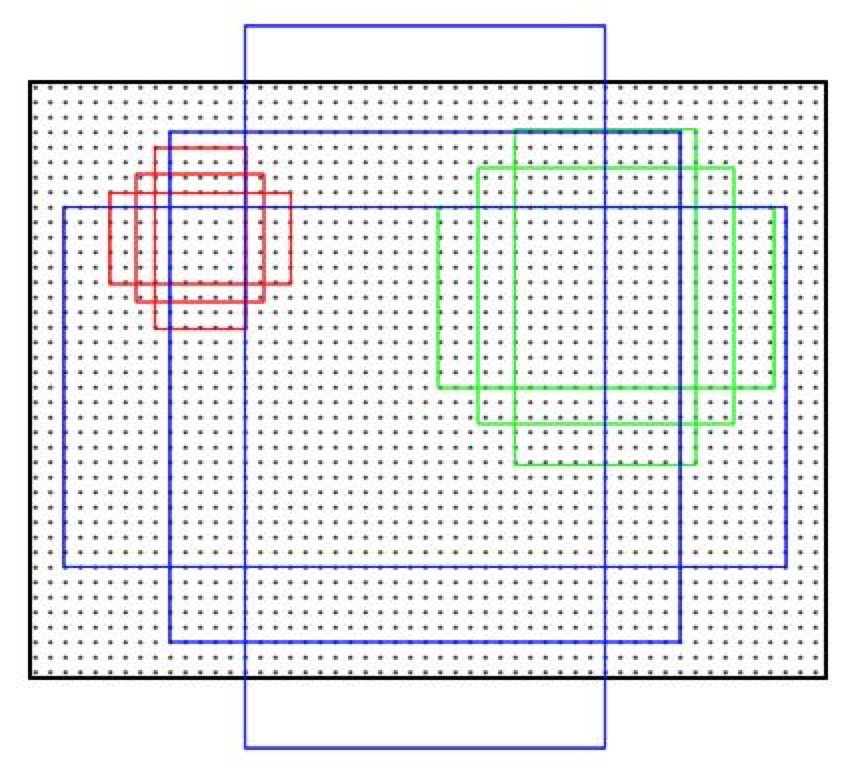
这9个框的位置大家可以不用管,我的理解只是原文作者想这样画,表示框的大小选取是128,256,512,1∶1,1∶2,2∶1这种特征。其实也可以画成这样:

对特征图上所有的点都做9个这样的anchor,假设特征图是60×40大小的,那么是不是总个数应该是60×40×9≈20k个anchor(可以做几步优化减少anchor数:1.把超出图片的anchor全部舍弃掉,之后大约有6k个;2.进行nms,把重复率高的舍弃掉,之后大约有2k个;最后选300个进入训练就ok了)。我们对这些anchor列两个list,第一个个K×4的list,分别对应每个anchor的4个坐标;第二个list为K×2,用于记录概率值,一个是表示此anchor属于前景的概率Pi,还有个是此anchor属于背景的概率。用此anchor框住的面积和标记中的面积做IoU,大于0.7的标记为正类,小于0.3的标记为负类,0.3至0.7的舍弃掉,不用于训练。并且对正负两类做nms非极大值抑制,把重叠度的高的框舍弃掉,只留概率最大的框。这样,我们就把RPN网络的训练参数选出来了。
我们单独训练这个RPN网络,选256个batch,正负类各一半。计算分类损失时,还是用Lcls表示,边框的回归损失用Lreg表示,两者相加如下:
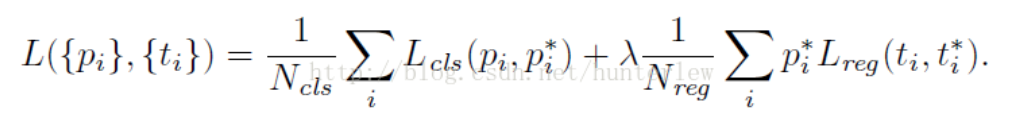
i表示batch中第几个框,Pi表示这个框属于前景的概率值,当Pi大于0.7时,Pi*为1,表示此框为目标框,要计算其回归损失,当Pi小于0.3时,Pi*为0,表示此框为背景框,不计算此边框回归损失。Ncls和λ,Nreg都是权重系数,保证这两个损失的权重相等。
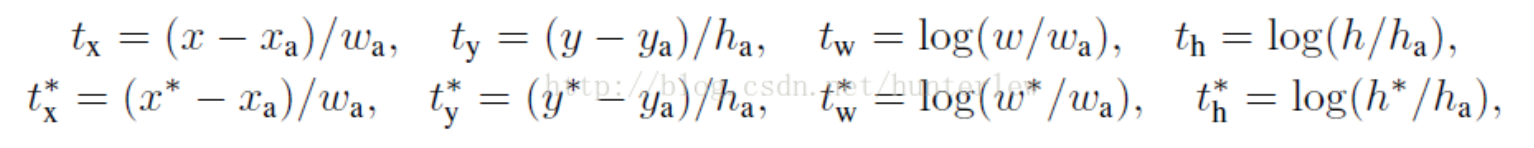
ti是预测框缩放之后对应值,ti*是标记框预测之后对应值。即xywh都是预测值,x*y*w*h*都是原始图中标记的值,而xayawaha都是此anchor对应的值。这样,通过对总体损失L进行迭代优化,便可以优化整个RPN网络。
交替训练
最后一步就是整个fasterRCNN网络的交替训练了。首先,使用ImageNet预训练的模型初始化RPN网络;第二步,我们用第一步RPN生成的区域建议框,作用于fastRCNN网络,替代其中的ss生成的建议框,这时,两个网络还没有共享卷积层;第三步,用第二步训练出的网络初始化RPN,并且固定卷积层,只是微调RPN中特有的层,现在两个网络共享了前面的卷积层;第四步,将RPN网络引入fastRCNN,固定前面的共享卷积层,微调fastrcnn的fc层,这样就将两个网络融合为一了。
参考
有几个我觉得写的很好的blog引用过来:
http://www.sohu.com/a/223608341_129720
https://blog.csdn.net/u011956147/article/details/53053381?locationNum=15&fps=1
http://www.360doc.com/content/17/0303/14/10408243_633634497.shtml
初次研究fasterRCNN,说的地方可能有问题,如果觉得我哪说的不对,可以讨论,我再进行修改~