慢启动和拥塞避免算法是在 1988 年提出的,而快重传和快恢复是 1990 年提出的;
既然这两个新算法是时隔两年后才提出的,那么它一定是对慢启动和拥塞避免算法的不足之处进行了改良;
在此之前,先来回忆一下,发送方如何判定网络产生拥塞?已知的一种情况是对方回复 ack 超时;
其实还有一种情况,如果发送方连续收到接收方多个重复的 ack(接收方不会没事发送重复的 ack 的),则说明网络生产拥塞;
那么简单总结一下,发送方判定网络拥塞就有两种情况了:
- ack 超时
- 发送方连续收到重复的 ack
知道了上面的事情后,接下来看看,针对连续收到重复的 ack,发送方应该怎么做;
快重传
首先对于接收方来说,如果接收方收到一个失序的报文段,就立即回送一个 ACK 给发送方,而不是等待一会然后发送延时的ACK(请参考《迟到的 ACK》);
所谓失序的报文是指,用户没有按照顺序收到 TCP 报文段,比如接收方收到了报文 M1, M2, M4,那么 M4 就称为失序 报文。
这样做的目的是可以让发送方尽可能早的知道报文段 M3 未到达接收方;
快重传算法规定,如果发送方一连收到 3 个重复的确认,就应当立即传送对方未收到的报文 M3,而不必等待 M3 的重传计时器到期;
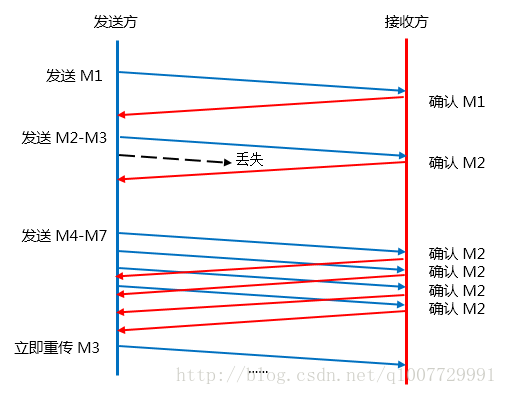
图1 快重传算法
快恢复
在学习了上一节的慢启动和拥塞避免算法后,我们知道,一旦出现超时重传,TCP 就会把慢启动门限 ssthresh 的值设置为 cwnd 值的一半,同时 cwnd 设置成 1;
但是快恢复算法不这样做;
一旦出现超时重传,或者收到第三个重复的 ack 时(快重传),TCP 会把慢启动门限 ssthresh 的值设置为 cwnd 值的一半,同时 cwnd = ssthresh (在有些版本中,会让 cwnd = ssthresh + 3)。
之前的旧版本的算法是在 TCP 的 Tahoe 版本中,而改进的版本算法是在 TCP Reno 版本中;
图 2 中演示了他们之间的区别:蓝色曲线是旧版本,而红色是新版本;
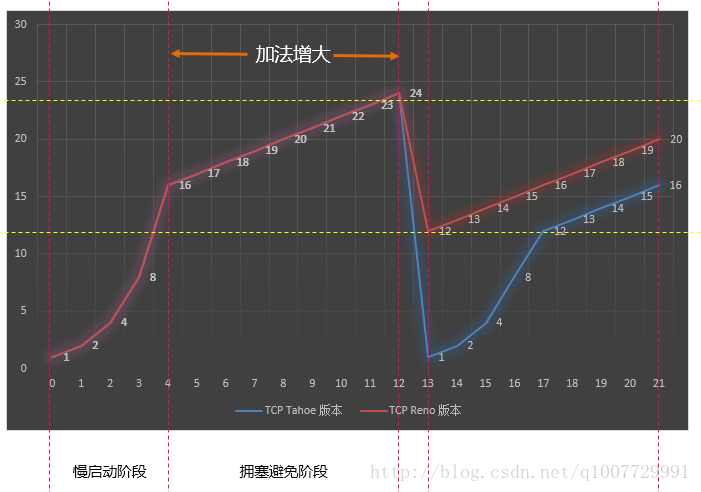
图 2 中,连续收到三个重复ACK后,TCP Reno(红色)版本转入了拥塞阶段,而 TCP Tahoe 版本(蓝色)转入了慢启动阶段;
实际上,现代的 Linux 内核版本早已都不采用上面这些 TCP 版本了,而是使用使用的 TCP Cubic 版本。那为什么还要学呢?这就好比你想学会走,你就得先学会爬,简单的先弄会,以后再自学复杂的
流量控制与拥塞控制
在学习流量控制的时候,我们假设网络无限好,不拥塞;
在学习拥塞控制的时候,我们又假设接收方缓冲区和接收窗口无限大,对数据来者不拒。现在,是时候综合考虑他们的时候了。
如何综合考虑这两者呢?实际上很简单,我们只要将接收方的窗口 rwnd 和拥塞窗口 cwnd 放在一起比较,取两者中的较小者,也就是:
上式指出:
- rwnd < cwnd : 是接收方的接收能力限制了发送方窗口的最大值;
- cwnd < rwnd : 是网络的拥塞限制了发送方窗口的最大值;
- 拥塞窗口cwnd是在发送方这边,因为它的值反映了网络的拥塞状况;