1 求1000之内的所有水仙花数
/**
* 输入描述:求1000之内的所有水仙花数
*
* 水仙花数,是指一个三位整数,它的各位数字的立方和等于这个数本身.
例如:371就是一个水仙花数,因为371=3*3*3+7*7*7+1*1*1.
*/
public static void NumberOfDaffodils() {
int hundred, ten, bits;
for (int i = 100; i <= 999; i++) {
hundred = i / 100;
ten = i % 100 / 10;
bits = i % 10;
if (i == Math.pow(hundred,3) + Math.pow(ten,3) + Math.pow(bits,3)) {
Log.d(TAG, "NumberOfDaffodils " + i);
}
}
}NumberOfDaffodils 153
NumberOfDaffodils 370
NumberOfDaffodils 371
NumberOfDaffodils 4072 蒙特卡洛算法
2.1 背景
蒙特卡洛算法概是以率统计理论为指导,使用随机数模拟来解决问题的一种方法。
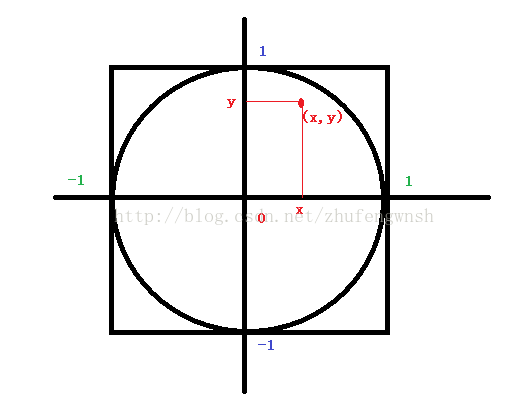
求圆周率π , 如果半径为1,,根据勾股定理,x² + y² <= 1的落点都在圆内。正方形面积:2*2=4,圆面积πr² = π。
随机生成一个坐标,次数为a,假设有b次在圆内,那么 b/a(落在圆内部次数/落在正方形内部次数) = π/4(圆面积/正方形面积),计算可得π=4*b/a。
2.2 源码
/**
* 蒙特卡洛算法
*
* 判断落点是否在圆内部 勾股定理 x² + y² = r² ,那么 x² + y² <= r² 都视作在圆内
* count = 1000000 +
*/
public double getPi(int count) {
double in = 0;
for (int i = 0; i < count; i++) {
double x = Math.random();
double y = Math.random();
if (Math.pow(x, 2) + Math.pow(y, 2) <= 1) {
in ++;
}
}
return 4 * in / count;
}3 蚁群算法
3.1 概念
蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法。它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质,并且现在已用于我们生活的方方面面。
3.2 参考链接
4 KMP经典算法
4.1 KMP算法求解什么类型问题
字符串匹配。给你两个字符串,寻找其中一个字符串是否包含另一个字符串,如果包含,返回包含的起始位置。
4.2 算法说明
一般匹配字符串时,我们从目标字符串str(假设长度为n)的第一个下标选取和ptr长度(长度为m)一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取str下一个下标,同样选取长度为n的字符串进行比较,直到str的末尾(实际比较时,下标移动到n-m)。这样的时间复杂度是O(n*m)。
KMP算法:可以实现复杂度为O(m+n)。为何简化了时间复杂度:
充分利用了目标字符串ptr的性质(比如里面部分字符串的重复性,即使不存在重复字段,在比较时,实现最大的移动量)。
4.3 next数组
4.3.1 next数组就是求前面串中前后缀相等的最大长度

4.3.2 next数组的作用
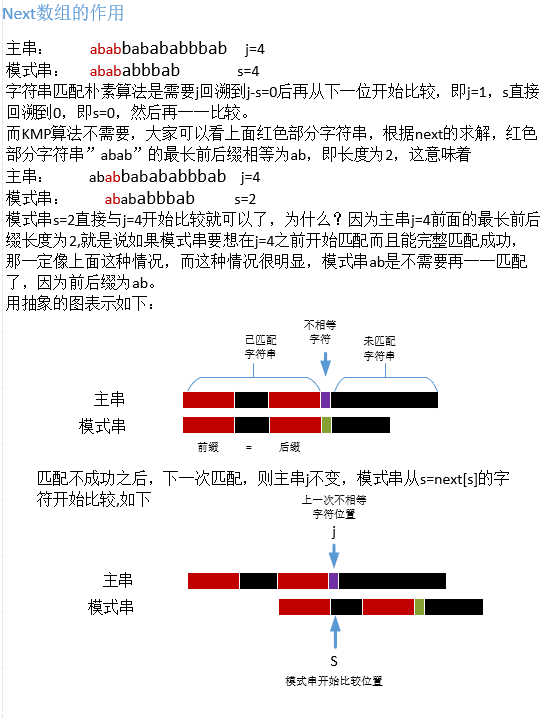
next数组就是保存着当主串和模式串不匹配时,接下来与主串j比较的模式串中s的位置,即s=next[s]。
4.3.3 next数组的求法
//next数组的求解
private static void getNext(int[] next, String str) {
next[0] = -1;//初始化
int k = -1;//记录当前位的next
int j = 0;//当前位下标
while (j < str.length() - 1) {//求解完所有字符的next
if (k == -1 || str.charAt(j) == str.charAt(k)) {//比较当前位与当前位next字符是否相等
j++;
k++;//当前位的next值+1作为下一位的next值
next[j] = k;//这个是把算的k的值(就是相同的最大前缀和最大后缀长)赋给next[j]
} else {
k = next[k];////往前回溯,回到前一个前后缀相等位置:如果下一个不同,那么k就变成next[k],注意next[k]是小于k的,无论k取任何值。
}
}
}4.4 完整的KMP算法
简言之,将主串与模式串匹配,相等的话彼此都+1,如果不等,主串j不回溯,将模式串的s=next[s]与主串j比较,相等彼此+1,以此类推,直到模式串完全被匹配,或者主串匹配到最末,结束。算法如下:
public void main8() {
String str1 = "ababbabababbbab";//主串
String str2 = "abababbbab";//模式串
int next[] = new int[str2.length()];
getNext(next, str2);//求解next数组
System.out.println("next数组" + java.util.Arrays.toString(next));
List<Integer> pos = new ArrayList<>();//可能存在多个位置起始的字符串与模式串匹配,记录这些在主串中的位置
ifMatch(str1, str2, next, pos);//字符串匹配过程
System.out.println("匹配位置:" + pos);//输出所有匹配的位置
}
private static void ifMatch(String str1, String str2, int[] next, List<Integer> pos) {
int j = 0;//主串初始位置
int s = 0;//匹配串初始位置
while (j < str1.length()) {
if (s == -1 || str1.charAt(j) == str2.charAt(s)) {//比较字符是否相等
j++;
s++;
if (s >= str2.length()) {//模式串被完全匹配
pos.add(j - str2.length());
s = 0;
j--;
}
} else {
s = next[s];//不等,主串j不变,模式串s变
}
}
}
//next数组的求解
private static void getNext(int[] next, String str) {
next[0] = -1;//初始化
int k = -1;//记录当前位的next
int j = 0;//当前位下标
while (j < str.length() - 1) {//求解完所有字符的next
if (k == -1 || str.charAt(j) == str.charAt(k)) {//比较当前位与当前位next字符是否相等
j++;
k++;//当前位的next值+1作为下一位的next值
next[j] = k;//这个是把算的k的值(就是相同的最大前缀和最大后缀长)赋给next[j]
} else {
k = next[k];////往前回溯,回到前一个前后缀相等位置:如果下一个不同,那么k就变成next[k],注意next[k]是小于k的,无论k取任何值。
}
}
}4.5 参考链接
5 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
5.1 问题
假如每个url大小为10bytes,那么可以估计每个文件的大小为50G×64=320G,远远大于内存限制的4G,所以不可能将其完全加载到内存中处理,可以采用分治的思想来解决。
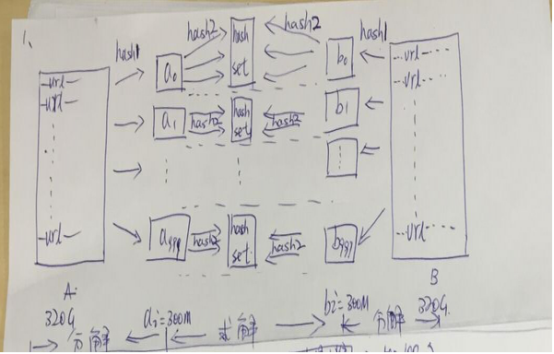
5.2 解决步骤
(1)遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,…,a999,每个小文件约300M);
(2)遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为b0,b1,…,b999)。
巧妙之处:这样处理后,所有可能相同的url都被保存在对应的小文件(a0 vs b0,a1 vs b1,…,a999 vs b999)中,不对应的小文件不可能有相同的url。然后我们只要求出这个1000对小文件中相同的url即可。
(3)求每对小文件ai和bi中相同的url时,可以把ai的url存储到hash_set/hash_map中。然后遍历bi的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
5.3 参考链接
面试- 阿里-. 大数据题目- 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?