前言:我的第一篇博客,本人大一菜鸟一枚,第一次写python的项目,需要大量的数据,第一次接触爬虫这个东西,感觉十分有趣,想以后往这方面发展,特写下自己的爬虫学习经历,希望把自己的学习经历分享给初学者们,也希望各位大佬帮助指正。声明:没有使用多线程,没有使用代理IP,没有使用框架,最简单的一个爬虫爬到死
python版本:python3.6
使用requests库爬取,使用beautifulsoup库解析(使用了一点点正则表达式)
爬取的网页:http://word.iciba.com/
爬取目标:网站上所有的单词,单词的发音,单词的中文意思
首先分析网页找到我们要爬取的超链接:
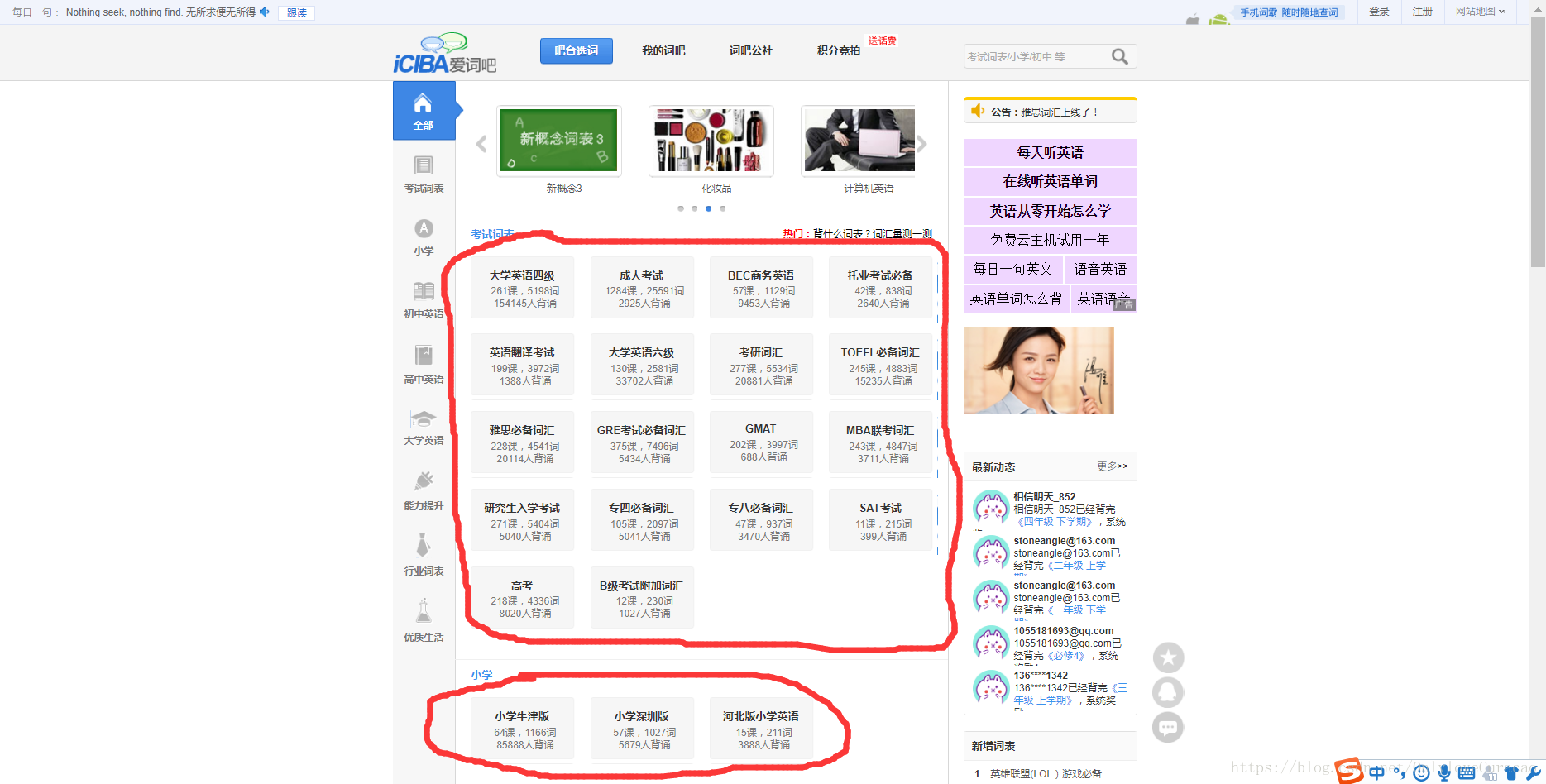
经过我们分析后发现:
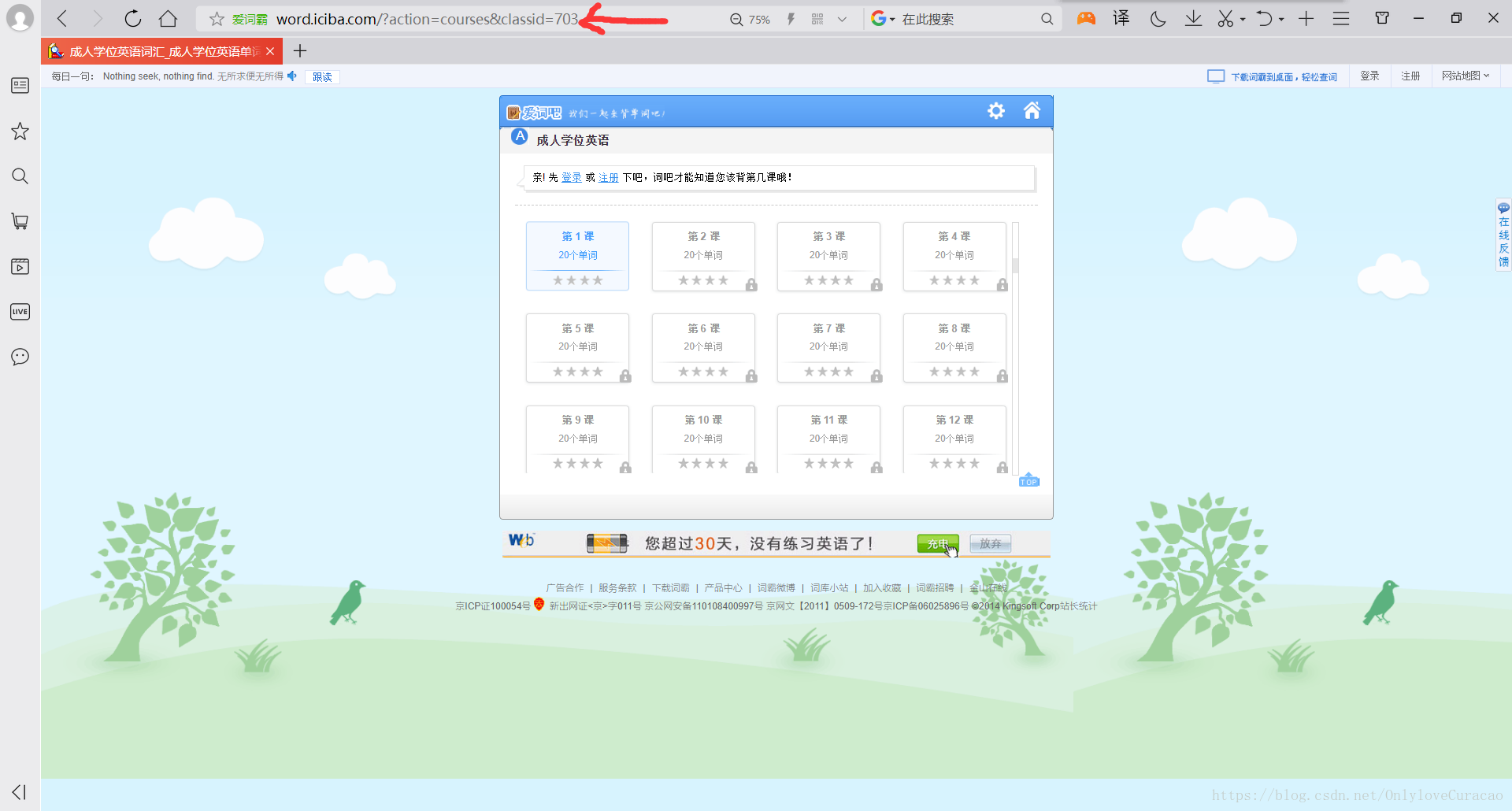
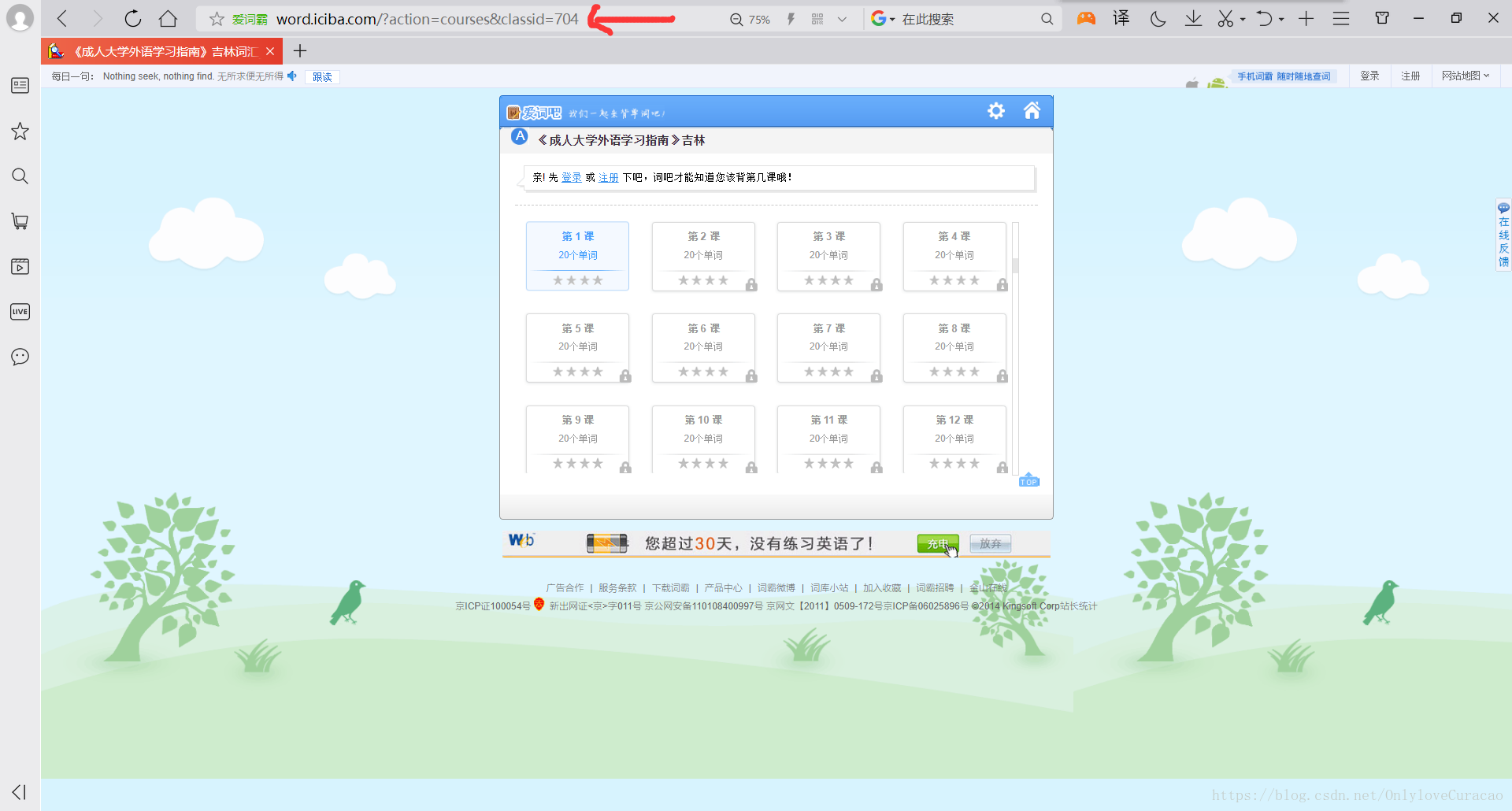
所有超链接只是后面的“classid=”这个东西在变,所以第一步找出所有的“classid”的数值:
def get_url(html):#解析首页得到所有的网址
word_all = []#所有classid可能取值的列表
mess = BeautifulSoup(html,'lxml')
word_num = mess.select('.main_l li')
for word in word_num:
word_all.append(word.get('class_id'))
return word_all但我们发现单词并不在这一层,而在更里面一层
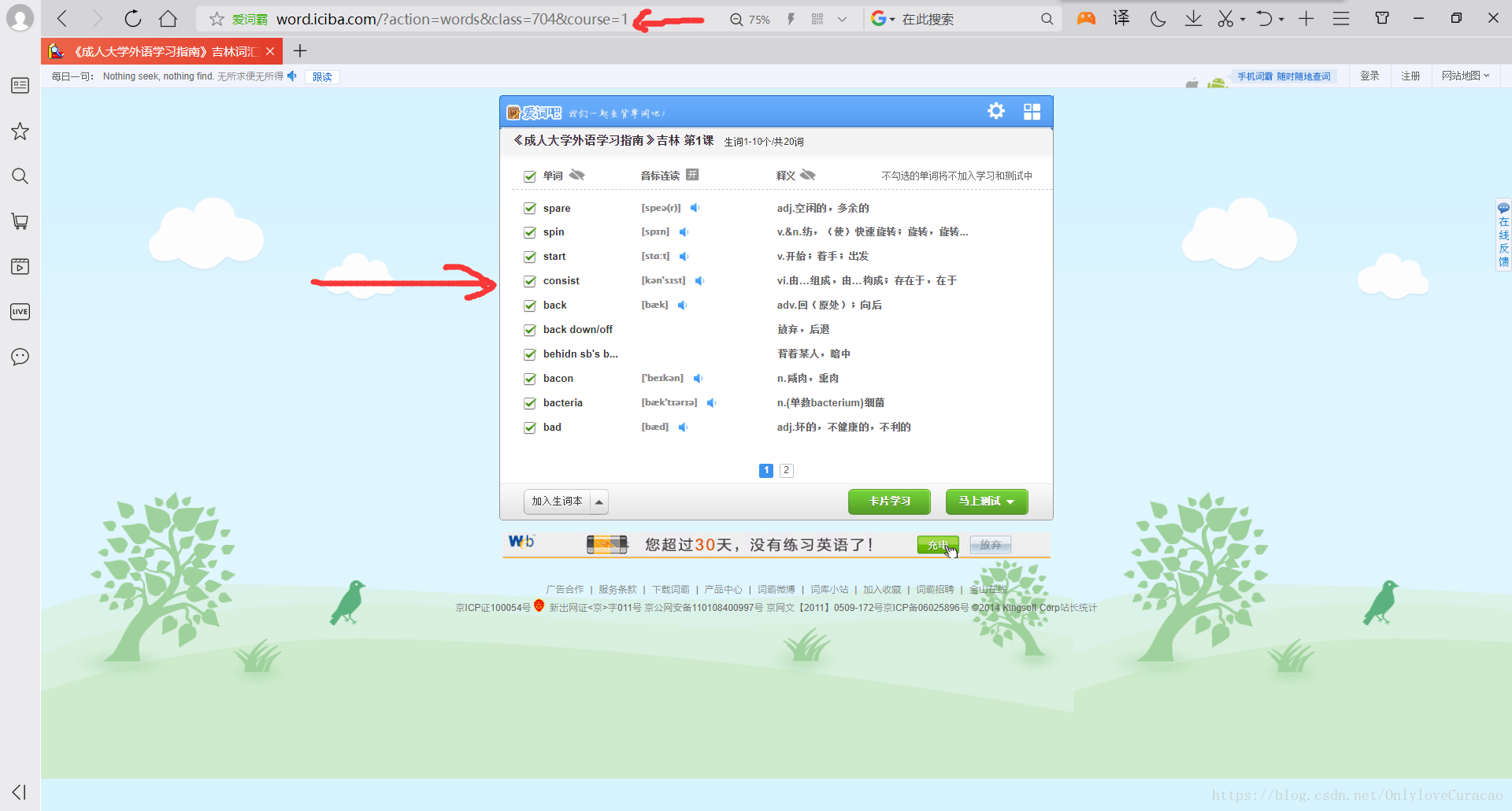
通过观察我们发现他只不过是在网址后面里加入了“course=”,进一步分析发现有多少课时course的数值就是1到~,所以我们按照上述方法得到course的所有取值
for num in word_all:#word_all为classid所有可能的取值
url_home = 'http://word.iciba.com/?action=courses&classid=' + str(num)#利用字符串拼接起来,得到URL网址
html = get_urlhtml(url_home)
mess = BeautifulSoup(html, 'lxml')
li = mess.select('ul li')#解析得到所有的课时,其中li的长度就是课时的数量通过一个双重循环得到每一个存在单词的网页:
for num in word_all:#word_all为classid所有可能的取值
url_home = 'http://word.iciba.com/?action=courses&classid=' + str(num)#利用字符串拼接起来,得到URL网址
html = get_urlhtml(url_home)
mess = BeautifulSoup(html, 'lxml')
li = mess.select('ul li')#解析得到所有的课时,其中li的长度就是课时的数量
for j in range(1, len(li) + 1):#利用课时的数量就是course的取值的特性,得到course的取值
url = 'http://word.iciba.com/?action=words&class=' + str(num) + '&course=' + str(j)#得到单词所在的URL网站通过我们的解析函数得到我们想要的内容:
def paqu_wangye(reponse,name):#爬取所有的单词、发音、翻译
word_mause={}
mess = BeautifulSoup(reponse,'lxml')
word = mess.find_all('div',class_="word_main_list_w")
mause = mess.find_all(class_="word_main_list_y")
fanyi = mess.find_all(class_='word_main_list_s')
for i in range(1,len(word)):
key = word[i].span.get('title')
f = mause[i].strong.string.split()
y = fanyi[i].span.get('title')
if len(f) == 0:#因为某些发音不存在,我们直接放弃,不存入
continue
word_mause[key]=[f[0],y,name]
print('创建数据成功')
return word_mause接下来最重要的就是存入数据库了:
首先我们先创建一个表用来存放所有的数据
def creat_table():#创建一个表
db = pymysql.connect(host='localhost', user='root', password='zcj123.abc', db='123', port=3306)#打开数据库,尤其是密码和数据库一定不能打错
print('打开数据库成功')
cursor = db.cursor()#创建一个游标
sql = 'CREATE TABLE IF NOT EXISTS word (id VARCHAR(255) NOT NULL,fayin VARCHAR(255) NOT NULL,fanyi VARCHAR(255) NOT NULL,music VARCHAR(255) NOT NULL,word_tream VARCHAR(255) NOT NULL, PRIMARY KEY (id))'#sql语句
cursor.execute(sql)#创建
print('创建表成功')
db.close()接下来就是将数据存入了:
def cucun(word_mause):#将数据存到数据库
db = pymysql.connect(host='localhost', user='root', password='zcj123.abc', db='123', port=3306)#打开数据库
print('打开数据库成功')
cursor = db.cursor()#创建一个游标
for key in word_mause:#word_mause是一个字典,模型:{'comment': ['[ˈkɔment]', 'n. 评论,意见;体现,写照', '四级必备词汇']}
sql = 'INSERT INTO word(id, fayin, fanyi, music, word_tream) values(%s, %s, %s, %s, %s)'#构造sql语句
try:
cursor.execute(sql, (key,word_mause[key][0],word_mause[key][1],'music/'+key+'.mp3',word_mause[key][2]))
db.commit()#插入数据
except:
db.rollback()#如果发生异常,则回滚(什么事情都没有发生)
print('数据插入成功')
db.close()#关闭数据库,记得一定要记得关闭数据库
print('数据库成功关闭')下面是整体的代码(内置爬取单词音频的代码,不过爬取效率不高):
import requests
from bs4 import BeautifulSoup
import pymysql
import re
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
def get_urlhtml(url):#爬取主页
try:
html = requests.get(url,headers = header)#使用requests库爬取
if html.status_code == 200:#如果状态码是200,则表示爬取成功
print(url+'解析成功')
return html.text#返回H5代码
else:#否则返回空
print('解析失败')
return None
except:#发生异常返回空
print('解析失败')
return None
def get_url(html):#解析首页得到所有的网址
word_all = []#所有classid可能取值的列表
mess = BeautifulSoup(html,'lxml')
word_num = mess.select('.main_l li')
for word in word_num:
word_all.append(word.get('class_id'))
return word_all
def paqu_wangye(reponse,name):#爬取所有的单词、发音、翻译
word_mause={}
mess = BeautifulSoup(reponse,'lxml')
word = mess.find_all('div',class_="word_main_list_w")
mause = mess.find_all(class_="word_main_list_y")
fanyi = mess.find_all(class_='word_main_list_s')
for i in range(1,len(word)):
key = word[i].span.get('title')
f = mause[i].strong.string.split()
y = fanyi[i].span.get('title')
if len(f) == 0:#因为某些发音不存在,我们直接放弃,不存入
continue
word_mause[key]=[f[0],y,name]
print('创建数据成功')
return word_mause
def paqumusci(reponse):#爬取音频
mause_list = []#音频URL列表
word_list = []#单词列表
mess = BeautifulSoup(reponse, 'lxml')
mause = mess.find_all(class_="word_main_list_y")
word = mess.find_all(class_='word_main_list_w')
for i in range(1, len(mause)):
word_list.append(word[i].span.get('title'))#加入列表
mause_list.append(mause[i].a.get('id'))#加入列表
for i in range(len(word_list)):#存入文件
try:
file = open('static//music//'+word_list[i] + '.mp3', 'wb')#打开文件,wb打开,以.mp3的格式打开
flag = requests.get(mause_list[i])#爬取音频URL
file.write(flag.content)#以二进制流写入
file.close()#关闭文件
print(word_list[i]+'存储成功')
except:
print(word_list[i] + '存储失败')
def cucun(word_mause):#爬取数据到数据库
db = pymysql.connect(host='localhost', user='root', password='zcj123.abc', db='123', port=3306)#打开数据库
print('打开数据库成功')
cursor = db.cursor()#创建一个游标
for key in word_mause:#word_mause是一个字典,模型:{'comment': ['[ˈkɔment]', 'n. 评论,意见;体现,写照', '四级必备词汇']}
sql = 'INSERT INTO word(id, fayin, fanyi, music, word_tream) values(%s, %s, %s, %s, %s)'#构造sql语句
try:
cursor.execute(sql, (key,word_mause[key][0],word_mause[key][1],'music/'+key+'.mp3',word_mause[key][2]))
db.commit()#插入数据
except:
db.rollback()#如果发生异常,则回滚(什么事情都没有发生)
print('数据插入成功')
db.close()#关闭数据库,记得一定要记得关闭数据库
print('数据库成功关闭')
def creat_table():#创建一个表
db = pymysql.connect(host='localhost', user='root', password='zcj123.abc', db='123', port=3306)
print('打开数据库成功')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS word (id VARCHAR(255) NOT NULL,fayin VARCHAR(255) NOT NULL,fanyi VARCHAR(255) NOT NULL,music VARCHAR(255) NOT NULL,word_tream VARCHAR(255) NOT NULL, PRIMARY KEY (id))'
cursor.execute(sql)
print('创建表成功')
db.close()
def main():
creat_table()#创建一个表
url = 'http://word.iciba.com/'
html = get_urlhtml(url)#得到首页的H5代码
word_all = get_url(html)#得到所有classid可能取值的列表
print('初始化成功开始爬取')
for num in word_all:#word_all为classid所有可能的取值
url_home = 'http://word.iciba.com/?action=courses&classid=' + str(num)#利用字符串拼接起来,得到URL网址
html = get_urlhtml(url_home)
mess = BeautifulSoup(html, 'lxml')
li = mess.select('ul li')#解析得到所有的课时,其中li的长度就是课时的数量
if len(li) <= 2:
continue
name = mess.select('.word_h2')#得到词书名称
name = name[0]
r = re.compile(".*?</div>(.*?)</div>")
name = re.findall(r,str(name))
name = name[0]#得到词书名称
print('开始爬取'+name)
for j in range(1,len(li)+1):#利用课时的数量就是course的取值的特性,得到course的取值
url = 'http://word.iciba.com/?action=words&class='+str(num)+'&course='+str(j)#得到单词所在的URL网站
reponse = get_urlhtml(url)
# print('开始爬取音频')
# paqumusci(reponse)
# print('音频文件爬取完成')
print('开始爬取数据')
word_mause = paqu_wangye(reponse,name)#得到数据字典
print('开始存储数据')
cucun(word_mause)#存储数据
if __name__ == '__main__':
main()