CRF是一种典型的判别式模型,它是根据模板,得到相应的特征函数,再通过这些特征函数进行参数的优化计算,那么在介绍CRF模型前,就有必要先介绍判别式模型和生成式模型。
判别式模型和生成式模型的区别:
从流程上看:
生成模型:无穷样本-->概率密度模型 = 产生模型-->预测
判别模型:有限样本-->判别函数 = 预测模型-->预测
也就是说,如果我根据训练集,统计出一个概率密度模型,然后通过这个模型进行预测,那么就是一个生成模型;如果我写出一个判别函数,通过训练集,寻求出模型的各个参数的最优解,从而得到一个模型,再通过这个模型的各个参数预测,那么就是一个判别模型。
举个栗子:
生成模型:朴素贝叶斯、马尔科夫随机场
判别模型:支持向量机、逻辑回归、条件随机场
线性CRF模型:
在这里介绍一种CRF模型,即线性CRF模型。
我们现在有一群这样的训练集:D={x1,y1},{x2,y2},...,{xn,yn},需要预测的结果:O={y1',y2',...,yn'},然后我们有一堆特征模板。我们需要求的是P(y|x),如果说词性标注问题上,我们一句话中有8个位置,有5个标签(名词,动词,介词,形容词,代词),那么我们需要求8的5次方个概率。
其中:
下标介绍:
函数f:在给定观察序列X时,某个特定的序列Y的概率函数,包括转移函数和状态函数
K:f函数总共的个数
T:序列中总共的位置个数
t:在序列中的位置
最大对数似然表达式:
下标介绍:
N:训练集中训练数据的个数
我们的目标就是最大化对数似然函数时,求解各个参数的最优解。
为了避免过拟合,我们增加了L2正则式:
求解时,通过梯度下降法就可以求解出来。
在参数求解出来之后,要进行解码操作:选择出多种情况中概率最大的情况
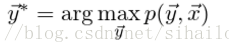
常用的特征工程技巧:
- 使用标签类特征,比如命名实体标注中的各个命名种类,会产生大规模的参数,因为有一些是不可能出现的,也就是说有的前面的系数为0。(比如说:北京和上海)这里边“和”是永远不会是城市的,这种特征叫做“unsupport feature”。虽然这种特征可以略微提高性能,但是,它会带来更多的参数,大大增加训练时间。
提出的办法就是:
先筛选出“unsupport feature”,对没有“unsupport feature”进行CRF训练;在迭代有限次之后,把那些“unsupport feature”加入到模型中训练。 - 为了减少特征的数量,我们把标签类特征对某些模板有效,而不是对所有模板有效。
- 边界的标签往往不同于普通位置的标签,比如说:句子中段英语单词大写,一般就是名词,而句子开始则不一定。
- 训练以一些基础的特征开始,然后期间增加一些这些特征之间的联系。
- 对于实值特性,它可以帮助应用标准的技巧,比如使特性归一化,表示均值0和标准偏差1或将其转换为本特性分类的值,表示为二进制特征。
- 在使用冗余特性时,使用正则化是很重要的。