第一次写博客,有写的不好的地方请多指教。
首先,在学习数据结构中,对链表在内存上的理解非常重要,上代码
public class LinkNode<M> {
public M data;
public LinkNode nextNode;
@Override
public String toString() {
return "LinkNode [data=" + data + ", nextNode=" + nextNode + "]"+"/n";
}
}
<M>这是泛型。先建立一个链表结构的类。很简单的一个链表结构,接下来建立一个Preson类
public class Person {
public String name;
public int age;
public String xueli;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", xueli=" + xueli + "]";
}
}
好了现在所需要的类都建立好了,接下来看主函数
public class MainTest {
public static void main(String [] ddd) {
LinkNode<Person> personLin = new LinkNode<Person>(); 这里呢首先将Person当做类型
Person zwx = new Person();
zwx.age = 22;
zwx.name ="周文先";
personLink0.data =zwx;
LinkNode<Person> personLink0 = new LinkNode<Person>();
Person person = new Person();
personLink0 .data = person;
personLink0 .data.age = personLin .data.age;
personLink0 .data.name = personLin .data.name;
personLin .data.age = 30;
LinkNode<Person> personLinkLast= personLink0 ; //这句话主要是记录最后一个链表块的位置,用他来记录,如果不是 LinkNode<Person> personLinkLast2 = personLinkLast而是 LinkNode<Person> personLinkLast=new LinkNode<Person>(); personLinkLast=personLink0 ;就会把第一个数据丢了,这个可以从堆栈上来分析
for(int i = 0; i < 100; i++) {
LinkNode<Person> personLinknext = new LinkNode<Person>();
Person personi = new Person();
personi.age = 30 + i;
personi.name ="zwx" + i;
personLinknext.data = personi;
personLinkLast.nextNode = personLinknext;
personLinkLast= personLinknext;
}
System.out.println(personLinkLast);
}
}
这个利用了JVM上的垃圾回收的原理,不懂的可以去百度,以后博客会慢慢出现的
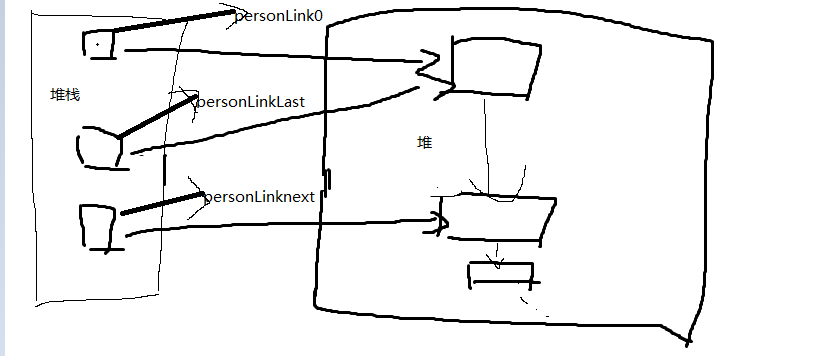 我想这样看图可能理解的快一点
我想这样看图可能理解的快一点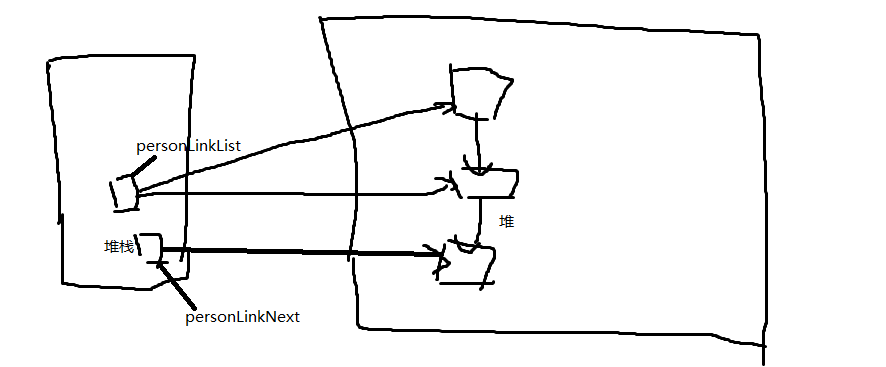 然后一级一级的循环下去,这个是从内存上去分析,饿感觉自己没讲出来,希望大家能看图理解,不好意思,第一次写博客,下次会继续去努力,
然后一级一级的循环下去,这个是从内存上去分析,饿感觉自己没讲出来,希望大家能看图理解,不好意思,第一次写博客,下次会继续去努力,