重点
- 命令/符号式编程的定义并不明确,CXXNet/Caffe因为依赖于配置文件,配置文件看作计算图的定义,也可以被当作符号式编程
源
什么是symblic/imperative style编程
使用过python或C++对imperative programs比较了解.imperative-stype programs在运行时计算.大部分python代码都是imperative.比如下面的例子
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1当程序执行到
时,代码开始做对应的数值计算.
symbolic programs于此不同.symbolic-stype program中,需要先给出一个函数的定义(可能十分复杂).当我们定义这个函数时,并不会做真正的数值计算.这类函数的定义中使用数值占位符.当给定真正的输入后,才会对这个函数进行编译计算.上面的例子用symbolic-stype program重新写
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)上述代码中,语句
并不会触发真正的数值计算,但会生成一个计算图(也称symbolic graph)描述这个计算.下图时计算
的计算图
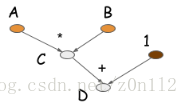
大部分symbolic-style program都显性或隐性的包含一个编译的步骤,把计算转换成可以调用的函数.上面的例子中,数值计算仅仅在代码最后一行进行.symbolic program一个重要特点是其明确有构建计算图和生成可执行代码两个步骤.对于神经网络,一般会用一个就算图描述整个模型.
其他流行深度学习框架中,Torch/Chainer/Minerva使用imperative style.symbolic-styple的框架包括Theano/CGT/TensorFlow. CXXNet/Caffe这一类依赖配置文件的框架也看作symbolic-style库.此时配置文件被当作计算图的定义.下面我们对比一下二者的优劣
命令式编程更加灵活
用python调用imperative-style库十分简单,编写方式和普通的python代码一样,在合适的位置调用库的代码实现加速.如果用python调用symbolic-style库,代码结构将出现一些变化,比如iteration可能无法使用.尝试把下面的例子转换成symbolic-style
a = 2
b = a + 1
d = np.zeros(10)
for i in range(d):
d += np.zeros(10)如果symblic-style API不支持for循环,转换就没那个直接.不能用python的编码思路调用symblic-style库.需要利用symblic API定义的domain-specific-language(DSL).深度学习框架会提供功能强大的DSL,把神经网络转化成可被调用的计算图.
感觉上imperative program更加符合习惯,使用更加简单.例如可以在任何位置打印出变量的值,轻松使用符合习惯的流程控制语句和循环语句.
符号式编程更加有效
既然imperative pragrams更加灵活,和计算机原生语言更加贴合,那么为什么很多深度学习框架使用symbolic风格? 最主要的原因式效率,内存效率和计算效率都很高.比如下面的例子
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
...如果数组每个元素内存中占据8字节,在python中需要多少内存?
对于imperative programs中,需要在每一行上都分配必要的内存.一共4个数组,每个数组10个元素,一共
字节. 如果事先知道只有
是需要的结果,构造计算图时可以重复利用一些中间变量的空间.比如利用原址计算,我们可以把
的内存借给
使用,同样
的内存可以给
用,如此可以节省一半内存,仅仅需要
字节
symbolic programs限制更多.因为只需要 ,构建计算图后,一些中间量,比如 ,的值将无法看到.
通过symbolic program,使用原址计算可以安全的重用内存.但牺牲了对 的访问可能. imperative program可以处理各种访问可能.如果在python执行上述例子,任何中间量都可以方便访问.
symbolic program还可以通过operation folding优化计算.在上述的例子中,乘法和加法可以展成一个操作,如下图所示.
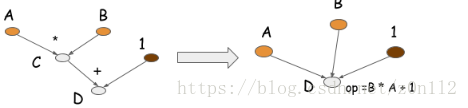
如果在GPU上运算,计算图只需要一个kernel,节省了一个kernel.在很多优化库,比如caffe/CXXNet,人工编码进行此类优化操作. operation folding可以提高计算效率.
imperative program中不能自动operation folding,因为不知道中间变量是否会被访问到. symbolic program中可以做operation folding,因为获得了完整的计算图,而且明确哪些量以后会被访问,哪些量以后都不会被访问.