转载请标明出处:
https://blog.csdn.net/xmxkf/article/details/81019110
本文出自:【openXu的博客】
1、什么是数据结构
数据结构主要学习用计算机实现数据组织和数据处理的方法;随着计算机应用领域的不断扩大,无论设计系统软件还是应用软件都会用到各种复杂的数据结构。
一个好的程序无非是选择一个合理的数据结构和好的算法,而好的算法的选择很大程度上取决于描述实际问题所采用的数据结构,所以想编写出好的程序必须扎实的掌握数据结构。
1.1 数据结构的定义
数据:人们利用文字符号、数据符号以及其他规定的符号对现实世界的事物及活动所做的抽象描述。从计算机的角度看,数据是所有能被输入到计算机中,并能被计算机处理的符号的集合。
数据元素: 数据集合中的一个“个体”,是数据的基本单位
数据结构: 是指数据以及相互之间的联系,可以看做是相互之间存在某种特定关系的数据元素的集合,因此可以把数据结构看成是带结构的数据元素的集合。
数据结构包括以下几个方面:
- 数据的逻辑结构
是指数据元素之间的逻辑关系。比如一个表中的记录顺序反映了数据元素之间的逻辑关系,一个数组中元素的排列顺序也是数据元素之间的逻辑关系。
- 数据的存储结构(物理结构)
数据元素及其逻辑关系在计算机存储器中的存储方式,一般只在高级语言的层次上来讨论存储结构。不同的逻辑结构有不同的存储结构
- 数据的运算
施加在该数据上的操作,是定义在数据的逻辑结构之上的,每种逻辑结构都有一组相应的运算。例如最常用的增删改查、更新、排序等。数据的运算最终需在对应的存储结构中用算法实现。
一组数据,数据元素及其录顺序是一定的,但是可以用不同的逻辑结构表示,这样就有着不同的存储结构,对应着不同的运算算法。以上都属于数据结构的范畴
为了更确切的描述一种数据结构,通常采用二元组表示:
B = (D, R)
其中,B是一种数据结构,它由数据元素的集合D,和D上二元关系的集合R所组成:
D = {di|1≤i≤n,n≥0} n为D中结点个数
R = {rj|1≤j≤m,m≥0} m为R中关系的个数
示例:一个城市表,给出其逻辑结构的二元组表示
| 城市 | 区号 | 说明 |
|---|---|---|
| Beijing | 010 | 首都 |
| Shanghai | 021 | 直辖市 |
| Changsha | 0731 | 湖南省会 |
| Wuhan | 027 | 湖北省会 |
City = (D, R)
D={Beijing, Shanghai, Changesha, Wuhan}
R={r}
r={<Beijign,Shanghai>, <Shanghai,Changsha>,<Changsha,Wuhan>}1.2 逻辑结构类型
在不会产生混淆的前提下,常常将数据的逻辑结构简称为数据结构。数据的逻辑结构主要有一下几类:
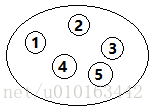
①. 集合
指数据元素之间除了“同属于一个集合”的关系外,别无其他关系
②. 线性结构
指该结构中的节点之间存在一对一的关系。特点是除了开始结点和终端结点,其余结点都有且仅有一个直接前驱,有且仅有一个直接后继。典型的例子就是“顺序表”
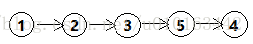
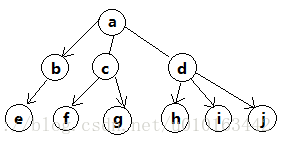
③. 树形结构
指该结构中的结点之间存在一对多的关系,其特点是每个结点最多只有一个直接前驱,但可以有多个直接后继,可以有多个终端结点。典型的树形结构“二叉树”
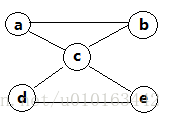
④. 图形结构
该结构中的结点之间存在多对多的关系。特点是每个结点的直接前驱和直接后继的个数都可以是任意的。因此,可能没有开始节点和终端结点,也可能有多个开始节点和终端结点。
树形结构和图形结构统称为非线性结构,该结构中的结点之间存在一对多或者多对多的关系
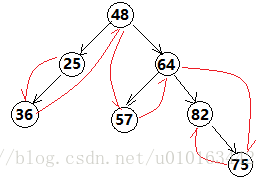
示例:
有一种数据结构B=(D, R),其中:
D = {48,25,64,57,82,36,75}
R = {r1 , r2}
r1 = {<25,36>,<36,48>,<48,57>,<57,64>,<64,75>,<75,82>}
r2 = {<48,25>,<48,64>,<64,57>,<64,82>,<25,36>,<82,75>}
请画出其逻辑结构表示。
解:对应图形如下,它是一种图形结构,其中r1(红线)为线性结构,r2(黑线)为树形结构
1.3 存储结构类型
①. 顺序存储结构
把逻辑上相邻的结点存储在物理位置上相邻的存储单元里,结点之间的逻辑关系由存储单元的邻接关系体现。
优点:节省存储空间(只存储结点的数据,结点之间逻辑关系没有占用存储空间)
缺点:不便于修改,对结点的插入、删除运算时,可能要移动一系列的结点
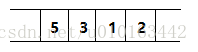
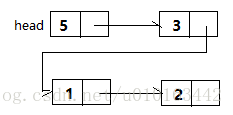
②. 链式存储结构
该结构不要求逻辑上相邻的结点在物理位置上也相邻,结点间的逻辑关系由附加的指针字段表示。
优点:便于修改,在进行插入、删除运算时,只需要修改相应结点的指针域,不需要移动结点
缺点:与顺序存储方法相比存储空间的利用率较低(存储结点的逻辑关系需要占用空间)
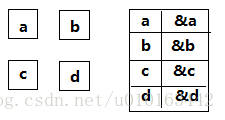
③. 索引存储结构
在存储结点信息的同事还建立附加的索引表,索引表中的索引项一般形式为(唯一标识,地址),地址为指向结点的指针。这样大大提高数据查找的速度。
优点:可以对结点随机访问。在插入、删除时只需要操作索引表中对应结点的存储地址,不必移动结点表中的结点数据,仍保持较高的数据修改运算效率。
缺点:增加了索引表,降低了存储空间的利用率
④. 哈希(散列)存储结构
根据结点的关键字通过哈希函数直接计算出一个值,并将这个值作为该节点的存储地址。
优点:查找速度快(可直接计算出要查询结点的地址)
缺点:只存储结点的数据,不存储结点之间的逻辑关系。一般只合适要求对数据能快速查找和插入的场合
这四种基本的存储方法即可单独使用,也可组合使用,同一种逻辑结构采用不同的存储方法可以得到不同的储存结构。应考虑运算方便及算法的时空要求 决定采用何种存储结构
1.4 数据结构和数据类型
数据类型:
某种程序设计语言中已实现的数据结构。高级程序语言对程序中出现的变量、常量或表达式明确的说明他们所属的数据类型,不同数据类型取值范围不同,能进行的操作也不同。数据类型是一个值得集合和定义在此集合上的一组操作的总称。
数据类型可分为简单类型(无法分割:整数、实数、字符、指针、枚举等)和结构类型(可分割:数组、字符串、自定义类型等)
数据结构:
是指计算机处理的数据元素的组织形式和相互关系,可以理解为是一个“抽象的”概念性的东西,而数据类型是对数据结构的实现。
2、算法及其描述
2.1 什么是算法
数据元素之间的关系有逻辑关系和物理关系,对应的运算有逻辑结构上的运算功能和具体存储结构上的运算实现。把具体存储结构上的运算实现过程称为算法。
算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示计算机的一个或多个操作。
算法的五个重要特性:
- 有穷性(能结束)
- 确定性(只有一条执行路径)
- 可行性(执行有限次能实现)
- 有输入
- 有输出
2.2 算法描述
算法可有多种描述方式,比如文字方式、语言方式、图形方式、表格方式等。
3、算法分析
在一个算法设计好后,还需要对其进行分析,确定一个算法的优劣。
3.1 算法设计的目标
算法设计应满足一下几条目标:正确性、可使用性(用户友好性)、可读性、健壮性(容错性)、高效率与低存储量需求
3.2 算法效率分析
通常有两种衡量算法效率的方法:事后统计法、事前分析估算法
事后统计法
缺点是必须执行程序,而且存在其他因素掩盖算法本质
事前分析估算法:
通常采用这种方法。撇开与计算机硬件、软件相关因素(计算机运行速度、编程语言、编译后机器语言代码质量),仅考虑算法本身的效率高低,可以认为一个特定的算法的运行工作量只依赖于问题的规模(用整数量n表示)。
一个算法由控制语句(顺序、分支、循环)和原操作(固有数据类型的操作)构成,算法运行时间取决于两者的综合效果。算法执行时间大致为基本运算所需的时间和其运算次数的乘积。显然,一个算法执行基本运算的次数越少,其运行时间也就相对越少,所以算法的执行时间可以看成是其中基本运算执行的次数(T(n)),T(n)是问题规模n的某个函数f(n)。
示例:求两个n阶方阵相加C=A+B的算法如下,分析其时间复杂度:
void matrixAdd(int A[][], int B[][], int C[][]){
int n = A.length; //语句① 执行1次
int i, j;
for(i = 0; i< n; i++) //语句② 执行n+1
for(j = 0; j< n; j++) //语句③ 执行n(n+1)次
C[i][j] = A[i][j] + B[i][j]; //语句④ 执行n²次
}解:该算法包含四个可执行语句,语句①就是基本运算,语句②和语句③是循环语句,其控制变量要从0增加到n,当i=n才会终止,所以它们的频度都为n+1,但它们的循环体只执行n次,因此该算法所有语句频度之和为:
T(n)=f(n)=1+ n+1+n(n+1)+n²=2n²+2n+2
由于算法长度不一定,有的算法非常长,如果还按照这种方式计算就非常麻烦了。另一种方式是只分析影响算法执行时间的最主要部分即可,而不是每一步都详细的分析。
这时候引入一个记号O(读大O,Order简写,指数量级),T(n)=O(f(n))表示算法时间复杂度取决于f(n)函数中最高阶,忽略其他低阶项和常系数,这样既可以简化T(n)的计算,又能客观的反应出当n很大时算法的时间性能,注意是n很大时,这样计算时间复杂度才有意义。所以上面示例中的答案就直接简化为T(n)=O(n²)。算法的时间复杂度使用大O(数量级)表示后,只需要分析影响算法执行时间的主要部分即可,不必对每一步都进行详细的分析。上面的示例中只需要分析两重循环最深层的语句④的频度即可:T(n)=n²=O(n²)。以后总是采用这种方式分析算法的时间复杂度。
不同数量级对应的值存在的关系如下:
O(1) 常数阶 < O(log2n)对数阶< O(n) 一重循环线性阶 < O(nlog2n) <O(n²)平方阶<O(n³)立方阶<O(2n)指数阶<O(n!)无穷
3.3 算法存储空间分析
一个算法的存储量包括输入数据所占空间、程序本身所占空间和辅助变量所占空间。在对算法进行存储空间分析时,只考虑辅助变量所占空间,所以空间复杂度是对一个算法在运行过程中临时占用的存储空间大小的量度,一般也作为问题规模n的函数,以数量级形式给出,记做:
S(n) = O(g(n))
示例:有如下算法,调用语句为fun(a, n, 0),求其空间复杂度:
void fun(int a[], int n, int k){
int i; //辅助变量
if(k==n-1){
for(i=0;i<n;i++)
System.out.println(a[i]);
}else{
for(i=k;i<n;i++)
a[i]=a[i]+i*i;
fun(a,n,k+1); //递归调用
}
}解:设fun(a,n, k)的临时空间大小为S(k),其中定义了一个辅助变量i,并有:
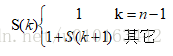
S(0) = 1+S(1)=1+1+S(2)
=...=1+1+...+1+S(n-1)
=1+1+...+1 (n个1)=O(n)
所以调用fun(a,n,0)的空间复杂度为O(n)
4、数据结构+算法=程序
计算机软件最终成果都是以程序的形式表现的,数据结构和算法分析的目的是设计好的程序。程序设计的本质是对要处理问题选择好的数据结构,同时再次结构上施加一种好的算法。
①. 数据结构与算法
选择数据结构时也要考虑其对算法的影响,数据结构对算法的影响主要有两方面:
数据结构的存储能力:存储能力与所使用的空间大小成正比,体现了时间与空间的矛盾
定义在数据结构上的运算:数据结构上定义了基本运算,有了好的运算,算法设计也就比较容易
②. 选择时的考虑
- 数据结构要适应问题的状态描述
- 数据结构应与所选择的算法相适应
- 数据结构的选择同时要兼顾程序设计的方便
- 灵活应用已有知识