http://poj.org/problem?id=1611
并查集学习:
l 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
l 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图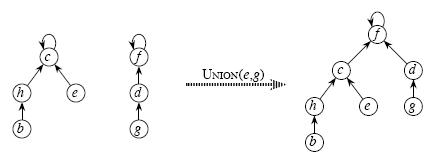
l 并查集的优化
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。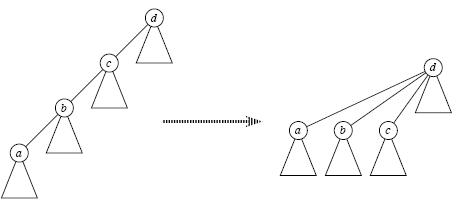
#include <iostream>
#include <cstdio>
using namespace std;
#define MAX 31000
int father[MAX],ran[MAX];
void initial(int n)
{
for(int i=0;i<n;i++)
{
father[i]=i;
ran[i]=1;
}
}
int fin(int x)
{
if(x!=father[x])
{
father[x]=fin(father[x]);
}
return father[x];
}
void unio(int x,int y)
{
x=fin(x);
y=fin(y);
if(x==y) return;
if(ran[x]>=ran[y])
{
father[y]=x;
ran[x]=ran[x]+ran[y];
}
else
{
father[x]=y;
ran[y]=ran[y]+ran[x];
}
}
int main()
{
int n,m,i,j;
int k,next,first;
while(cin>>n>>m&&(n||m))
{
initial(n);
for(i=0;i<m;i++)
{
cin>>k>>first;
for(j=1;j<k;j++)
{
cin>>next;
unio(first,next);
}//for j
}//for i
cout<<ran[father[0]]<<endl;
}//while
return 0;
}