文章转自https://blog.csdn.net/u012702547/article/details/52259529
线程池算是Android开发中非常常用的一个东西了,只要涉及到线程的地方,大多数情况下都会涉及到线程池。Android开发中线程池的使用和Java中线程池的使用基本一致。那么今天我想来总结一下Android开发中线程池的使用。
OK,假如说我想做一个新闻应用,ListView上有一个item,每个item上都有一张图片需要从网络上加载,如果不使 线程池,你可能通过下面的方式来开启一个新线程:
-
new Thread(
new Runnable() {
-
@Override
-
public void run() {
-
//网络访问
-
}
-
}).start();
这种用法主要存在以下3点问题:
1.使用new Thread()创建线程存在的问题
1.针对每一个item都创建一个新线程,这样会导致频繁的创建线程,线程执行完之后又被回收,又会导致频繁的GC
2.这么多线程缺乏统一管理,各线程之间互相竞争,降低程序的运行效率,手机页面卡顿,甚至会导致程序崩溃
3.如果一个item滑出页面,则要停止该item上图片的加载,但是如果使用这种方式来创建线程,则无法实现线程停止执行
如果使用线程池,我们就可以很好的解决以上三个问题。
2.使用线程池的好处
1.重用已经创建的好的线程,避免频繁创建进而导致的频繁GC
2.控制线程并发数,合理使用系统资源,提高应用性能
3.可以有效的控制线程的执行,比如定时执行,取消执行等
OK,我们知道Android中的线程池其实源于Java,Java中和线程有关的东东叫做Executor,Executor本身是一个接口,这个接口有一个非常有用的实现类叫做ThreadPoolExecutor,如下:
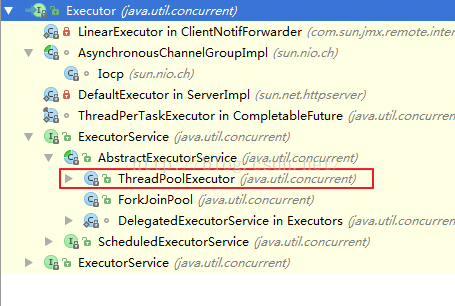
Android中常用的线程池都是通过对ThreadPoolExecutor进行不同配置来实现的,那么我们今天就从这这个ThreadPoolExecutor来开始吧!
3.ThreadPoolExecutor
ThreadPoolExecutor有四个重载的构造方法,我们这里来说说参数最多的那一个重载的构造方法,这样大家就知道其他方法参数的含义了,如下:
-
public ThreadPoolExecutor(int corePoolSize,
-
int maximumPoolSize,
-
long keepAliveTime,
-
TimeUnit unit,
-
BlockingQueue<Runnable> workQueue,
-
ThreadFactory threadFactory,
-
RejectedExecutionHandler handler)
这里是7个参数(我们在开发中用的更多的是5个参数的构造方法),OK,那我们来看看这里七个参数的含义:
corePoolSize 线程池中核心线程的数量
maximumPoolSize 线程池中最大线程数量
keepAliveTime 非核心线程的超时时长,当系统中非核心线程闲置时间超过keepAliveTime之后,则会被回收。如果ThreadPoolExecutor的allowCoreThreadTimeOut属性设置为true,则该参数也表示核心线程的超时时长
unit 第三个参数的单位,有纳秒、微秒、毫秒、秒、分、时、天等
workQueue 线程池中的任务队列,该队列主要用来存储已经被提交但是尚未执行的任务。存储在这里的任务是由ThreadPoolExecutor的execute方法提交来的。
threadFactory 为线程池提供创建新线程的功能,这个我们一般使用默认即可
handler 拒绝策略,当线程无法执行新任务时(一般是由于线程池中的线程数量已经达到最大数或者线程池关闭导致的),默认情况下,当线程池无法处理新线程时,会抛出一个RejectedExecutionException。
针对于workQueue参数我多说几点:workQueue是一个BlockingQueue类型,那么这个BlockingQueue又是什么呢?它是一个特殊的队列,当我们从BlockingQueue中取数据时,如果BlockingQueue是空的,则取数据的操作会进入到阻塞状态,当BlockingQueue中有了新数据时,这个取数据的操作又会被重新唤醒。同理,如果BlockingQueue中的数据已经满了,往BlockingQueue中存数据的操作又会进入阻塞状态,直到BlockingQueue中又有新的空间,存数据的操作又会被冲洗唤醒。BlockingQueue有多种不同的实现类,下面我举几个例子来说一下:
1.ArrayBlockingQueue:这个表示一个规定了大小的BlockingQueue,ArrayBlockingQueue的构造函数接受一个int类型的数据,该数据表示BlockingQueue的大小,存储在ArrayBlockingQueue中的元素按照FIFO(先进先出)的方式来进行存取。
2.LinkedBlockingQueue:这个表示一个大小不确定的BlockingQueue,在LinkedBlockingQueue的构造方法中可以传一个int类型的数据,这样创建出来的LinkedBlockingQueue是有大小的,也可以不传,不传的话,LinkedBlockingQueue的大小就为Integer.MAX_VALUE,源码如下:
-
/
-
* Creates a {@code LinkedBlockingQueue} with a capacity of
-
* {@link Integer#MAX_VALUE}.
-
/
-
public LinkedBlockingQueue() {
-
this(Integer.MAX_VALUE);
-
}
-
-
/
-
Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
-
-
@param capacity the capacity of this queue
-
* @throws IllegalArgumentException if {@code capacity} is not greater
-
* than zero
-
/
-
public LinkedBlockingQueue(int capacity) {
-
if (capacity <=
0)
throw
new IllegalArgumentException();
-
this.capacity = capacity;
-
last = head =
new Node<E>(
null);
-
}
3.PriorityBlockingQueue:这个队列和LinkedBlockingQueue类似,不同的是PriorityBlockingQueue中的元素不是按照FIFO来排序的,而是按照元素的Comparator来决定存取顺序的(这个功能也反映了存入PriorityBlockingQueue中的数据必须实现了Comparator接口)。
4.SynchronousQueue:这个是同步Queue,属于线程安全的BlockingQueue的一种,在SynchronousQueue中,生产者线程的插入操作必须要等待消费者线程的移除操作,Synchronous内部没有数据缓存空间,因此我们无法对SynchronousQueue进行读取或者遍历其中的数据,元素只有在你试图取走的时候才有可能存在。我们可以理解为生产者和消费者互相等待,等到对方之后然后再一起离开。
OK,这是ThreadPoolExecutor的构造方法参数的解释,我们的线程提交到线程池之后又是按照什么样的规则去运行呢?OK,它们遵循如下规则:
1.execute一个线程之后,如果线程池中的线程数未达到核心线程数,则会立马启用一个核心线程去执行
2.execute一个线程之后,如果线程池中的线程数已经达到核心线程数,且workQueue未满,则将新线程放入workQueue中等待执行
3.execute一个线程之后,如果线程池中的线程数已经达到核心线程数但未超过非核心线程数,且workQueue已满,则开启一个非核心线程来执行任务
4.execute一个线程之后,如果线程池中的线程数已经超过非核心线程数,则拒绝执行该任务
OK,基于以上讲解,我们来看一个Demo:
-
@Override
-
protected void onCreate(Bundle savedInstanceState) {
-
super.onCreate(savedInstanceState);
-
setContentView(R.layout.activity_main);
-
poolExecutor =
new ThreadPoolExecutor(
3,
5,
-
1, TimeUnit.SECONDS,
new LinkedBlockingDeque<Runnable>(
128));
-
}
-
-
public void btnClick(View view) {
-
for (
int i =
0; i <
30; i++) {
-
final
int finalI = i;
-
Runnable runnable =
new Runnable() {
-
@Override
-
public void run() {
-
SystemClock.sleep(
2000);
-
Log.d(
"google_lenve_fb",
"run: " + finalI);
-
}
-
};
-
poolExecutor.execute(runnable);
-
}
-
}
执行结果如下:

OK,由于核心线程数为3,workQueue的大小为128,所以我们的线程的执行应该是先启动三个核心线程来执行任务,剩余的27个任务全部存在workQueue中,等待核心线程空余出来之后执行。OK,那我把构造ThreadPoolExecutor的参数修改一下,来验证一下我们上面的结论正确与否:
-
poolExecutor =
new ThreadPoolExecutor(
3,
30,
-
1, TimeUnit.SECONDS,
new LinkedBlockingDeque<Runnable>(
6));
如上,我把最大线程数改为30,而把线程队列大小改为6(实际开发中 不会这样来设置,这里只是为了验证结论),我们来看看执行结果:

OK,首先打印出来0,1,2说明往核心线程添加了三个任务,然后将3,4,5,6,7,8六个任务添加到了任务队列中,接下来要添加的任务因为核心线程已满,队列已满所以就直接开一个非核心线程来执行,因此后添加的任务反而会先执行(3,4,5,6,7,8都在队列中等着),所以我们看到的打印结果是先是0~2,然后9~29,然后3~8,当然,我们在实际开发中不会这样来配置最大线程数和线程队列。那如果我们需要自己来配置这些参数,该如何配置呢?参考一下AsyncTask,AsyncTask部分源码如下:
-
public
abstract
class AsyncTask<Params, Progress, Result> {
-
private
static
final String LOG_TAG =
"AsyncTask";
-
-
private
static
final
int CPU_COUNT = Runtime.getRuntime().availableProcessors();
-
private
static
final
int CORE_POOL_SIZE = CPU_COUNT +
1;
-
private
static
final
int MAXIMUM_POOL_SIZE = CPU_COUNT
2 +
1;
-
private
static
final
int KEEP_ALIVE =
1;
-
-
private
static
final ThreadFactory sThreadFactory =
new ThreadFactory() {
-
private
final AtomicInteger mCount =
new AtomicInteger(
1);
-
-
public Thread newThread(Runnable r) {
-
return
new Thread(r,
"AsyncTask #" + mCount.getAndIncrement());
-
}
-
};
-
-
private
static
final BlockingQueue<Runnable> sPoolWorkQueue =
-
new LinkedBlockingQueue<Runnable>(
128);
-
-
/*
-
An {@link Executor} that can be used to execute tasks in parallel.
-
*/
-
public
static
final Executor THREAD_POOL_EXECUTOR
-
=
new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE,
-
TimeUnit.SECONDS, sPoolWorkQueue, sThreadFactory);
-
....
-
....
-
}
我们看到,核心线程数为手机CPU数量+1(cpu数量获取方式Runtime.getRuntime().availableProcessors()),最大线程数为手机CPU数量×2+1,线程队列的大小为128,OK,那么小伙伴们在以后使用线程池的过程中可以参考这个再结合自己的实际情况来配置参数。
OK,那么和线程池有关的最基本的ThreadPoolExecutor我们就说完了,接下来我们就来看看系统配置好的提供给我们的线程池。
4.FixedThreadPool
FixedThreadPool是一个核心线程数量固定的线程池,创建方式如下:
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
源码如下:
-
public static ExecutorService newFixedThreadPool(int nThreads) {
-
return
new ThreadPoolExecutor(nThreads, nThreads,
-
0L, TimeUnit.MILLISECONDS,
-
new LinkedBlockingQueue<Runnable>());
-
}
我们看到核心线程数和最大线程数一样,说明在FixedThreadPool中没有非核心线程,所有的线程都是核心线程,且线程的超时时间为0,说明核心线程即使在没有任务可执行的时候也不会被销毁(这样可让FixedThreadPool更快速的响应请求),最后的线程队列是一个LinkedBlockingQueue,但是LinkedBlockingQueue却没有参数,这说明线程队列的大小为Integer.MAX_VALUE(2的31次方减1),OK,看完参数,我们大概也就知道了FixedThreadPool的工作特点了,当所有的核心线程都在执行任务的时候,新的任务只能进入线程队列中进行等待,直到有线程被空闲出来。OK,我们来看一个Demo:
-
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(
3);
-
for (
int i =
0; i <
30; i++) {
-
final
int finalI = i;
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
SystemClock.sleep(
3000);
-
Log.d(
"google_lenve_fb",
"run: "+ finalI);
-
}
-
};
-
fixedThreadPool.execute(runnable);
-
}
执行结果如下:
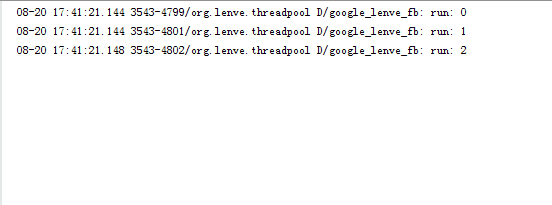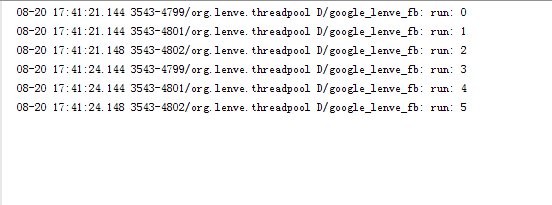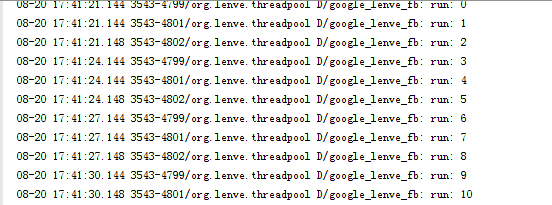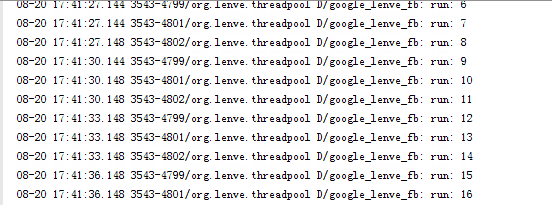
这执行结果也和我们想的一致,先往核心线程中添加三个任务,剩余任务进入到workQueue中等待,当有空闲的核心线程时就执行任务队列中的任务。
5.SingleThreadExecutor
singleThreadExecutor和FixedThreadPool很像,不同的就是SingleThreadExecutor的核心线程数只有1,如下:
-
public static ExecutorService newSingleThreadExecutor() {
-
return
new FinalizableDelegatedExecutorService
-
(
new ThreadPoolExecutor(
1,
1,
-
0L, TimeUnit.MILLISECONDS,
-
new LinkedBlockingQueue<Runnable>()));
-
}
使用SingleThreadExecutor的一个最大好处就是可以避免我们去处理线程同步问题,其实如果我们把FixedThreadPool的参数传个1,效果不就和SingleThreadExecutor一致了,来看个Demo:
-
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
-
for (
int i =
0; i <
30; i++) {
-
final
int finalI = i;
-
Runnable runnable =
new Runnable() {
-
@Override
-
public void run() {
-
Log.d(
"google_lenve_fb",
"run: " + Thread.currentThread().getName() +
"-----" + finalI);
-
SystemClock.sleep(
1000);
-
}
-
};
-
singleThreadExecutor.execute(runnable);
-
}
执行效果如下:
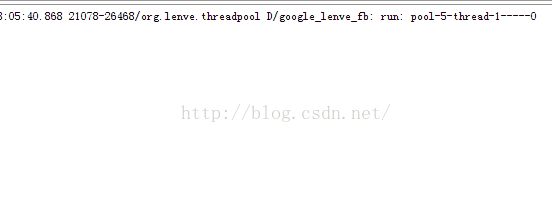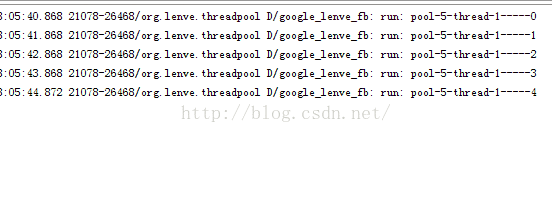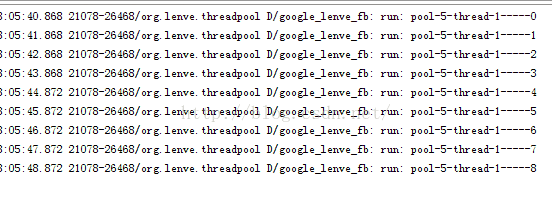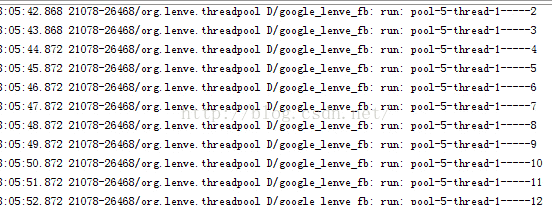
6.CachedThreadPool
CachedTreadPool一个最大的优势是它可以根据程序的运行情况自动来调整线程池中的线程数量,CachedThreadPool源码如下:
-
public static ExecutorService newCachedThreadPool() {
-
return
new ThreadPoolExecutor(
0, Integer.MAX_VALUE,
-
60L, TimeUnit.SECONDS,
-
new SynchronousQueue<Runnable>());
-
}
我们看到,CachedThreadPool中是没有核心线程的,但是它的最大线程数却为Integer.MAX_VALUE,另外,它是有线程超时机制的,超时时间为60秒,这里它使用了SynchronousQueue作为线程队列,SynchronousQueue的特点上文已经说过了,这里不再赘述。那么我们提交到CachedThreadPool消息队列中的任务在执行的过程中有什么特点呢?由于最大线程数为无限大,所以每当我们添加一个新任务进来的时候,如果线程池中有空闲的线程,则由该空闲的线程执行新任务,如果没有空闲线程,则创建新线程来执行任务。根据CachedThreadPool的特点,我们可以在有大量任务请求的时候使用CachedThreadPool,因为当CachedThreadPool中没有新任务的时候,它里边所有的线程都会因为超时而被终止。OK,我们来看一个Demo:
-
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
-
for (
int i =
0; i <
30; i++) {
-
final
int finalI = i;
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
Log.d(
"google_lenve_fb",
"run: " + Thread.currentThread().getName() +
"----" + finalI);
-
}
-
};
-
cachedThreadPool.execute(runnable);
-
SystemClock.sleep(
2000);
-
}
每次添加完任务之后我都停两秒在添加新任务,由于这里的任务执行不费时,我们可以猜测这里所有的任务都使用同一个线程来执行(因为每次添加新任务的时候都有空闲的线程),运行结果如下:

和我们的想法基本一致。OK,那如果我把代码稍微改一下:
-
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
-
for (
int i =
0; i <
30; i++) {
-
final
int finalI = i;
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
SystemClock.sleep(
2000);
-
Log.d(
"google_lenve_fb",
"run: " + Thread.currentThread().getName() +
"----" + finalI);
-
}
-
};
-
cachedThreadPool.execute(runnable);
-
SystemClock.sleep(
1000);
-
}
每个任务在执行的过程中都先休眠两秒,但是我向线程池添加任务则是每隔1s添加一个任务,这样的话,添加第一个任务时先开新线程,添加第二个任务时,由于第一个新线程尚未执行完,所以又开一个新线程,添加第三个任务时,第一个线程已经空闲下来了,直接第一个线程来执行第三个任务,依此类推。我们来看看运行结果:
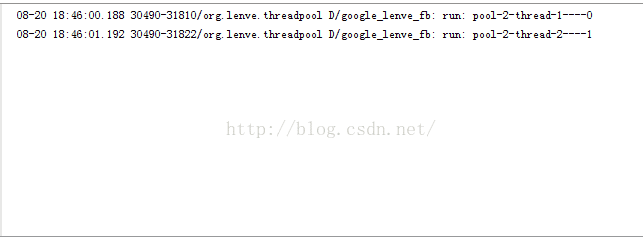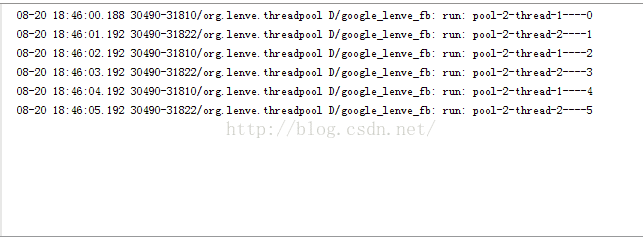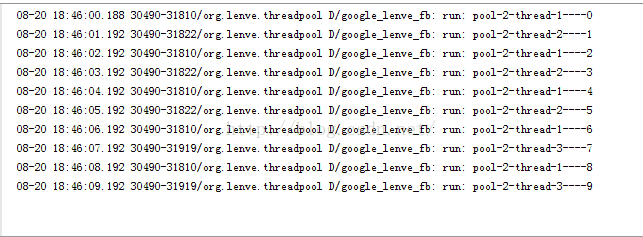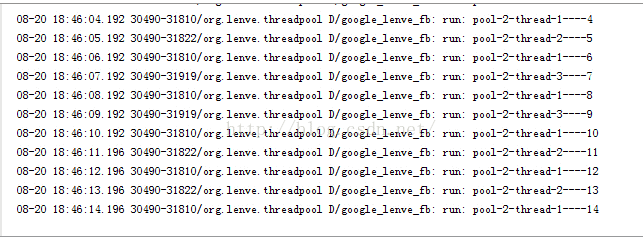
7.ScheduledThreadPool
ScheduledThreadPool是一个具有定时定期执行任务功能的线程池,源码如下:
-
public ScheduledThreadPoolExecutor(int corePoolSize) {
-
super(corePoolSize, Integer.MAX_VALUE,
-
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
-
new DelayedWorkQueue());
-
}
我们可以看到,它的核心线程数量是固定的(我们在构造的时候传入的),但是非核心线程是无穷大,当非核心线程闲置时,则会被立即回收。
使用ScheduledThreadPool时,我们可以通过如下几个方法来添加任务:
1.延迟启动任务:
-
public ScheduledFuture<?> schedule(Runnable command,
-
long delay, TimeUnit unit);
-
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(
3);
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
Log.d(
"google_lenve_fb",
"run: ----");
-
}
-
};
-
scheduledExecutorService.schedule(runnable,
1, TimeUnit.SECONDS);
2.延迟定时执行任务:
-
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
-
long initialDelay,
-
long period,
-
TimeUnit unit);
延迟initialDelay秒后每个period秒执行一次任务。示例代码:
-
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(
3);
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
Log.d(
"google_lenve_fb",
"run: ----");
-
}
-
};
-
scheduledExecutorService.scheduleAtFixedRate(runnable,
1,
1, TimeUnit.SECONDS);
延迟1秒之后每隔1秒执行一次新任务。
3.延迟执行任务
-
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
-
long initialDelay,
-
long delay,
-
TimeUnit unit);
第一次延迟initialDelay秒,以后每次延迟delay秒执行一个任务。示例代码:
-
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(
3);
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
Log.d(
"google_lenve_fb",
"run: ----");
-
}
-
};
-
scheduledExecutorService.scheduleWithFixedDelay(runnable,
1,
1, TimeUnit.SECONDS);
第一次延迟1秒之后,以后每次也延迟1秒执行。
OK,至此,Android开发中常用的线程池就说完了。
8.线程池其他常用功能
1.shutDown() 关闭线程池,不影响已经提交的任务
2.shutDownNow() 关闭线程池,并尝试去终止正在执行的线程
3.allowCoreThreadTimeOut(boolean value) 允许核心线程闲置超时时被回收
4.submit 一般情况下我们使用execute来提交任务,但是有时候可能也会用到submit,使用submit的好处是submit有返回值,举个栗子:
-
public void submit(View view) {
-
List<Future<String>> futures =
new ArrayList<>();
-
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(
3,
5,
1,
-
TimeUnit.SECONDS,
new LinkedBlockingDeque<Runnable>());
-
for (
int i =
0; i <
10; i++) {
-
Future<String> taskFuture = threadPoolExecutor.submit(
new MyTask(i));
-
//将每一个任务的执行结果保存起来
-
futures.add(taskFuture);
-
}
-
try {
-
//遍历所有任务的执行结果
-
for (Future<String> future : futures) {
-
Log.d(
"google_lenve_fb",
"submit: " + future.get());
-
}
-
}
catch (InterruptedException e) {
-
e.printStackTrace();
-
}
catch (ExecutionException e) {
-
e.printStackTrace();
-
}
-
}
-
-
class MyTask implements Callable<String> {
-
-
private
int taskId;
-
-
public MyTask(int taskId) {
-
this.taskId = taskId;
-
}
-
-
@Override
-
public String call() throws Exception {
-
SystemClock.sleep(
1000);
-
//返回每一个任务的执行结果
-
return
"call()方法被调用----" + Thread.currentThread().getName() +
"-------" + taskId;
-
}
-
}
使用submit时我们可以通过实现Callable接口来实现异步任务。在call方法中执行异步任务,返回值即为该任务的返回值。Future是返回结果,返回它的isDone属性表示异步任务执行成功!
5. 自定义线程池
除了使用submit来定义线程池获取线程执行结果之外,我们也可以通过自定义ThreadPoolExecutor来实现这个功能,如下:
-
public void customThreadPool(View view) {
-
final MyThreadPool myThreadPool =
new MyThreadPool(
3,
5,
1, TimeUnit.MINUTES,
new LinkedBlockingDeque<Runnable>());
-
for (
int i =
0; i <
10; i++) {
-
final
int finalI = i;
-
Runnable runnable =
new Runnable(){
-
@Override
-
public void run() {
-
SystemClock.sleep(
100);
-
Log.d(
"google_lenve_fb",
"run: " + finalI);
-
}
-
};
-
myThreadPool.execute(runnable);
-
}
-
}
-
class MyThreadPool extends ThreadPoolExecutor{
-
-
public MyThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
-
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
-
}
-
-
@Override
-
protected void beforeExecute(Thread t, Runnable r) {
-
super.beforeExecute(t, r);
-
Log.d(
"google_lenve_fb",
"beforeExecute: 开始执行任务!");
-
}
-
-
@Override
-
protected void afterExecute(Runnable r, Throwable t) {
-
super.afterExecute(r, t);
-
Log.d(
"google_lenve_fb",
"beforeExecute: 任务执行结束!");
-
}
-
-
@Override
-
protected void terminated() {
-
super.terminated();
-
//当调用shutDown()或者shutDownNow()时会触发该方法
-
Log.d(
"google_lenve_fb",
"terminated: 线程池关闭!");
-
}
-
}
执行结果如下:
-
D/google_lenve_fb: beforeExecute: 开始执行任务!
-
D/google_lenve_fb: run:
0
-
D/google_lenve_fb: beforeExecute: 任务执行结束!
-
D/google_lenve_fb: beforeExecute: 开始执行任务!
-
D/google_lenve_fb: run:
1
-
D/google_lenve_fb: beforeExecute: 任务执行结束!
-
D/google_lenve_fb: beforeExecute: 开始执行任务!
-
D/google_lenve_fb: run:
2
-
D/google_lenve_fb: beforeExecute: 任务执行结束!
OK,以上就是关于线程池的使用总结。。
参考资料
1.http://blog.csdn.net/u010687392/article/details/49850803
2.《Android开发艺术探索》
以上。
本文涉及到的Demo下载http://download.csdn.net/detail/u012702547/9608586