平面数据分类
吴恩达深度学习第一课第三周编程作业
目的:分类空间中的点
方案:二分分类法
神经网络结构:单隐藏网络,n_h=4(n_h是一个超参数)
隐藏层使用的是tanh作为激活函数,输出层是sigmoid函数
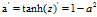
X是一个(2,400),Y是一个(1,400)的矩阵,X[0]表示x的坐标值,X[1]表示y的坐标值,从而确定平面上的一点
Y是一个很粗糙的行向量,前半部分都是0,后半部分都是1.
0表示一种颜色,1也表示一种颜色
通过学习,2特征(x的行数) 变 4特征(隐藏层数量) 然后输出
代码步骤:
-
设置神经网络结构
-
随机初始化参数
-
正反向传播
-
单步梯度下降
-
预测函数
-
整合函数
-
可视化分析
代码
-
import numpy as np
-
import sklearn
-
import matplotlib.pyplot as plt
-
import sklearn.datasets
-
import sklearn.linear_model
-
from planar_utils import plot_decision_boundary,sigmoid,load_planar_dataset,load_extra_datasets
-
np.random.seed(1)
-
-
'''''
-
seed( ) :用于指定随机数生成时所用算法开始的整数值
-
如果使用相同的seed( )值,则每次生成的随即数都相同
-
如果不设置这个值,则系统根据时间来自己选择这个值
-
此时每次生成的随机数因时间差异而不同。
-
-
planar_utils:自建py文档 本例中的一些小工具集合
-
'''
-
#载入数据
-
X,Y=load_planar_dataset()
-
-
-
#设置神经网络结构
-
def layer_size(X,Y):
-
n_x=X.shape[0]
-
-
n_y=Y.shape[0]
-
return(n_x,n_y)
-
-
#初始化参数
-
def initialize_parameters(n_x,n_h,n_y):
-
W2=np.random.randn(n_y,n_h)*0.01
-
b2=np.zeros(shape=(n_y,1))
-
W1=np.random.randn(n_h,n_x)*0.01
-
b1=np.zeros(shape=(n_h,1))
-
parameters={'W2':W2,
-
'b2':b2,
-
'W1':W1,
-
'b1':b1}
-
return parameters
-
-
#正反向传播函数
-
def propagate(X,Y,parameters):
-
m=X.shape[1]
-
W2=parameters['W2']
-
b2=parameters['b2']
-
W1=parameters['W1']
-
b1=parameters['b1']
-
Z1=np.dot(W1,X)+b1
-
A1=np.tanh(Z1)
-
Z2=np.dot(W2,A1)+b2
-
A2=sigmoid(Z2)
-
-
cost=(-1/m)*np.sum(Y*np.log(A2)+(1-Y)*np.log(1-A2)) #成本函数
-
cost=float(np.squeeze(cost))
-
#反向传播
-
dZ2=A2-Y
-
dW2=np.dot(dZ2,A1.T)/m
-
db2=np.sum(dZ2,axis=1,keepdims=True)/m
-
dZ1=np.dot(W2.T,dZ2)*(1-np.power(A1,2))
-
dW1=np.dot(dZ1,X.T)/m
-
db1=np.sum(dZ1,axis=1,keepdims=True)/m
-
-
grads={'dW2':dW2,
-
'db2':db2,
-
'dW1':dW1,
-
'db1':db1}
-
return (grads,cost)
-
-
#单步更新参数
-
def update_parameters(grads,parameters,learning_rate=1.2):
-
dW2=grads['dW2']
-
db2=grads['db2']
-
dW1=grads['dW1']
-
db1=grads['db1']
-
-
W2=parameters['W2']
-
b2=parameters['b2']
-
W1=parameters['W1']
-
b1=parameters['b1']
-
W2=W2-learning_rate*dW2
-
b2=b2-learning_rate*db2
-
W1=W1-learning_rate*dW1
-
b1=b1-learning_rate*db1
-
parameters={'W2':W2,
-
'b2':b2,
-
'W1':W1,
-
'b1':b1}
-
return parameters
-
-
#预测函数
-
def predict(parameters,X):
-
W2=parameters['W2']
-
b2=parameters['b2']
-
W1=parameters['W1']
-
b1=parameters['b1']
-
Z1=np.dot(W1,X)+b1
-
A1=np.tanh(Z1)
-
Z2=np.dot(W2,A1)+b2
-
A2=sigmoid(Z2)
-
predictions=np.round(A2)
-
return predictions
-
-
#整合
-
def model2(X,Y,n_h,num_iterations,print_cost=False):
-
n_x,n_y=layer_size(X,Y)
-
parameters=initialize_parameters(n_x,n_h,n_y)
-
for i in range(num_iterations):
-
grads,cost=propagate(X,Y,parameters)
-
parameters=update_parameters(grads,parameters)
-
if print_cost and i%1000==0:
-
print('after iterations cost%d:%f' %(i,cost))
-
predictions=predict(parameters,X)
-
#输出正确率
-
print('Accurent rate:%d' %float((np.dot(Y,predictions.T)+np.dot(1-Y,1-predictions.T))/float(Y.size)*100)+'%')
-
return parameters
-
-
#正式运行
-
parameters=model2(X,Y,n_h=4,num_iterations=10000,print_cost=True)
-
-
plot_decision_boundary(lambda x:predict(parameters,x.T),X,Y)
-
plt.title('h_y:4')
-
plt.show()
代码小结:
plt.scatter(x,y,s,c,cmap)
s表示圆点大小 c表示颜色,重点在于cmap,
cmap=plt.cm.Spectral表示颜色遵循光谱分色,根据c数组中的数字种类,进行分色,
如0代表了红色,1代表了蓝色(当只有2中分色时)
在dot是容易出事,可以停下来验证他们矩阵形状
正确率输出函数语句分析;
float((np.dot(Y,predictions.T)+np.dot(1-Y,1-predictions.T))/float(Y.size)*100)+'%')
首先是两个点积相加,然后除以Y的个数
第一个点积,表示累加预测值与实际值都等于1的情况
第二个点积,表示累加预测值与实际值都等于0的情况
两个相加,不就等于预测值与实际值相等的情况
plot_decision_boundary(lambda x:predict(parameters,x.T),X,Y)
第一个参数是把整个预测函数以及学习好的参数传过去了
利用pyplot画块这些就没有去深入了解了
再补上随机初始化权重随笔
如果权重W直接初始化为0 ,那么1层的节点结算会完全相同,即造成学习完的W是一个(1,n)的矩阵

W初始值一般取一个非常小的值所以乘上了0.01,当然也可以选择其它的值相乘