1.词汇表征
深度学习已经给自然语言处理(Natural Language Process, NLP)带来革命性的变革。其中一个很关键的概念是词嵌入(word embedding),这是语言表示的一种方式,可以让算法自动的了解一些类似的词,例如男人对女人(man to woman),国王对王后(king to queen)等。
在此前的表示中,我们用的一直都是词典的编号来表达一个词,例如Man为词典中的第5391个词,那么我们用one-hot向量表示为
, 表示为
。Woman为词典中的第9853个词,那么我们用one-hot向量表示为
,表示为
。这种表达方式最大的缺点就是将每个词都孤立起来了,这样使得算法对相关词的泛化能力不强。

除了one-hot之外,我们可以用特征化的表示,来表示每个词,Man、Woman、King、Queen、Apple、Orange或者词典中的任何一个单词,通过Man在每个特征的得分来得到描述于Man的向量,例如:特征依次为:gender、royal、age、food … … ,那么Man在各个特征的得分可能为[-1,0.01,0.03,0.09, … ],可以得到另外一个描述于Man的向量。

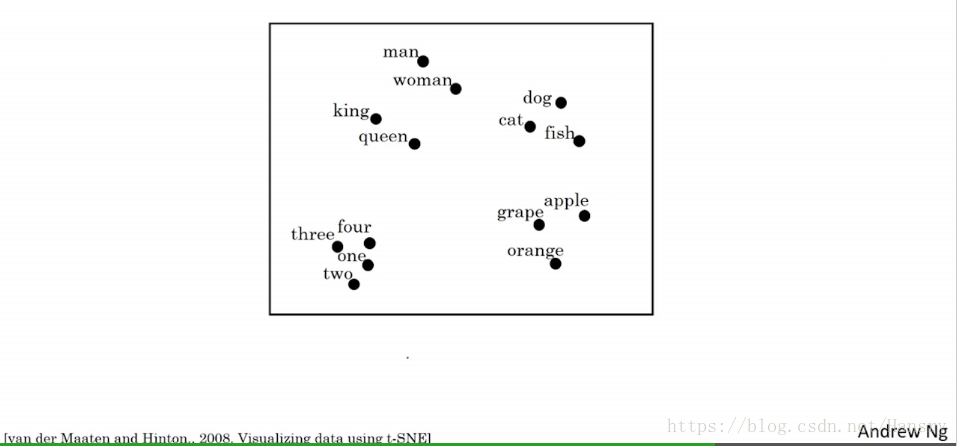
当我们有很多词的表示向量的时候,为了对他们进行可视化,常用的算法有
算法,来自于Laurens van der Maaten 和 Geoff Hinton的论文,将这些向量投影到低维空间。通过这个投影,会发现相似的词总是聚在一起。
为什么称为嵌入?
假如用一个300维度的特征空间来表示物体,每一个物体(用300维度的向量表示)在这个特征空中的每个维度都占有一定的位置,因此可以看作是嵌入(embedding)。
2.使用词嵌入
用词嵌入(word embedding)做迁移学习的步骤:
1.先从大量的文本集中,学习词嵌入,一个非常大的文本集。或者可以下载网上预训练好的词嵌入模型。
2.然后可以用这些词嵌入模型,把它迁移到你的新的只有少量标注训练集的任务中,比如说用这个300维的词嵌入来表示你的单词,这样做的唯一好处就是可以用较低维的向量来代替原来one-hot 的10000维度的向量。
3.最后,当你在新的任务上训练模型的时候,可以选择使用新的数据来微调词嵌入。
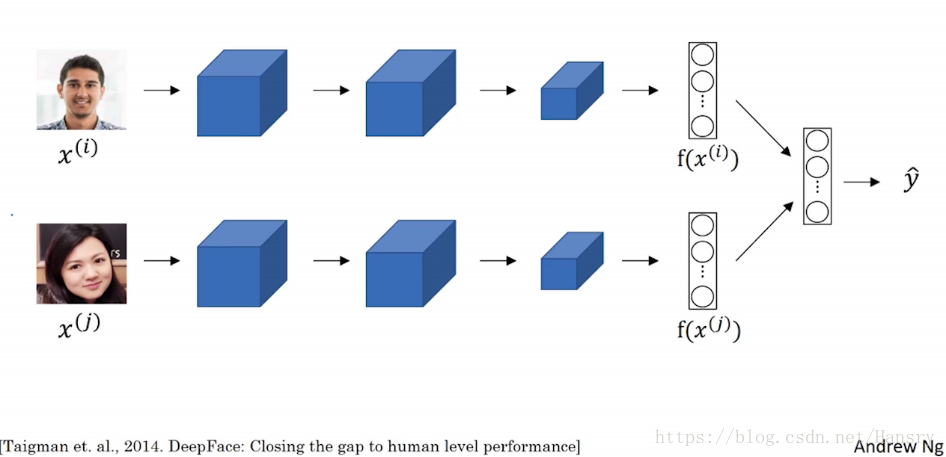
在前面我们学习了人脸识别,用一张人脸作为输入,得到128维度的向量,如下图所示。通过训练Siamese network来生成人脸图片的编码,及时对于之前没有见过的图片,同样可以生成其编码。而对于词嵌入而言,我们的原始数据规模是固定的,就是说我们有10000个词,通过词嵌入来生成
等特征向量,这就是俩者之间的差别。
3.词嵌入的特性
当我们有Man、Woman、King、Queen、Apple、Orange这些词的时候,我们有 Man -> Woman的关系,那么King对应于哪一个词呢,很明显为King -> Queen, 那么我们怎么写一个算法使其知道 Man->Woman 时,King-> Queen?
我们可以用
来分别代表Man、Woman、King和Queen,那么我们可以有以下等式,该思想来源于”Mikolov et. al., 2013, Linguistic regularities in continuous space word representations”。
则可以等价为: ,其中 为公式(1) 表达的 。
前面讲的,对于3000维的向量,可以使用 通过一种非线性方式从高维投影到二维平面进行可视化。
在上面的 函数中,最常用的是余弦相似度,公式为:
4.嵌入矩阵
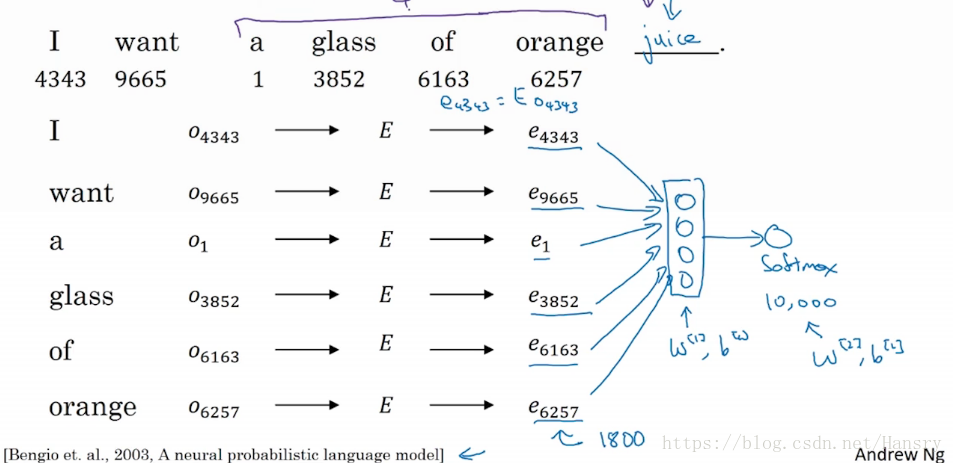
这一节中我们将学习词嵌入这一问题具体化,当应用算法来学习词嵌入的时候,实际上是学习一个嵌入矩阵(embedding matrix)。和之前一样,假设一个词典中含有10000个单词,词典中有 a 、aaron… … orange… … zulu 。这时候我们就拥有了一个300x10000的矩阵,称为 (每个词为一个300维度的向量,共有10000个)。
假如orange的编号为6257(代表字典中第6257个单词),我们用符号 来代表one-hot向量,则我们有 , 故有 , j 代表词在字典的顺序。
5.学习词嵌入
在深度学习应用于学习词嵌入(learning word embeddings)的历史上,惊讶的会发现,常用到的算法其实都是很简单的,以下逐一介绍。
假如你在构建一个语言模型,并且用神经网络来实现这个模型,于是,在训练过程中,你可能需要你的神经网络能够做到,当我输入 ,能够预测下划线的词。示意图如下,通过各个词的特征向量作为输入,然后最后通过一个softmax作为一个输出从而预测下划线的词。
通过反向传播,得到矩阵 等参数。
6. Word2Vec
Word2Vec 算法,是一种简单而且计算时更加高效的方式来学习这种类型的嵌入(embeddings)
Skip-grams
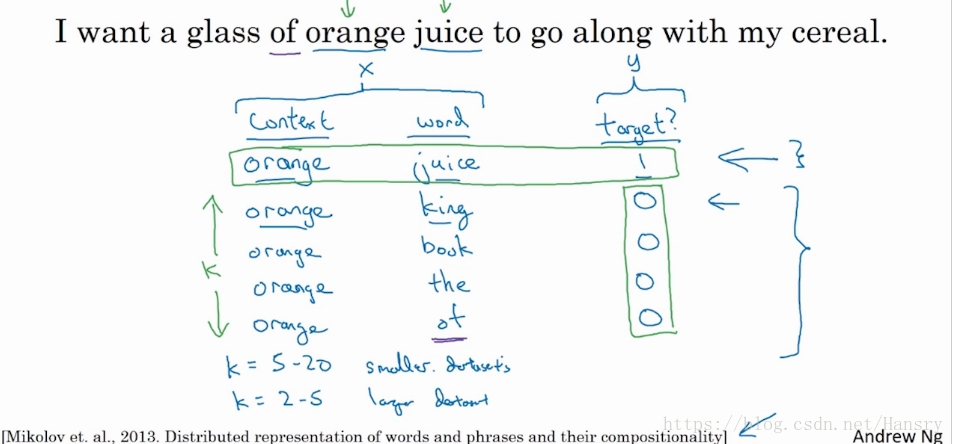
假设在训练集中给定了一个这样子的句子:I want a glass of orange juice to go along with my cereal.
在Skip-gram模型中,我们要做的是抽取上下文和目标词匹配来构建一个监督学习问题。上下文不一定总是在目标单词中离得最近的四个单词或者n个单词。我们要做的是随机选一个词作为上下文词,比如说我们选 orange 这个词,我们要做的就是随机在一定词距内选择另外一个词,比如在前后5个词或者前后10个词内,在这个范围内选择目标词。
因此,我们需要构建一个监督问题,给定一个上下文词(context word),来预测在这个词正负10个词距或者正负5个词距中,哪个是随机选到的词汇。这个目标有点问题,因为在单词orange的正负10个词汇中,可能会有很多不同的单词。
构建这个监督问题不是为了解决这个监督学习问题本身,而是为了学习更好的词嵌入模型(word embedding)。
以下是模型的细节部分:
假设我们仍然使用了一个10000词的词汇表,Vocab size=10000k。 但我们需要解决的基本的监督学习问题是学习一种映射关系,从上下文C(context c),这里我们假设为 orange(
),到某个目标词(target word,记为t),可能为 juice (
),即 C -> target。所以,这就是要学习的,从输入x映射到输出y。
因此在前面我们所说的,给定
其中 预测不同目标词的概率。
损失函数为:
, 其中, y为真实值,为one-hot 向量,即
, 而
则为Softmax输出来的结果。当优化代价函数
, 我们可以优化
以及
中的参数,这就是
模型。
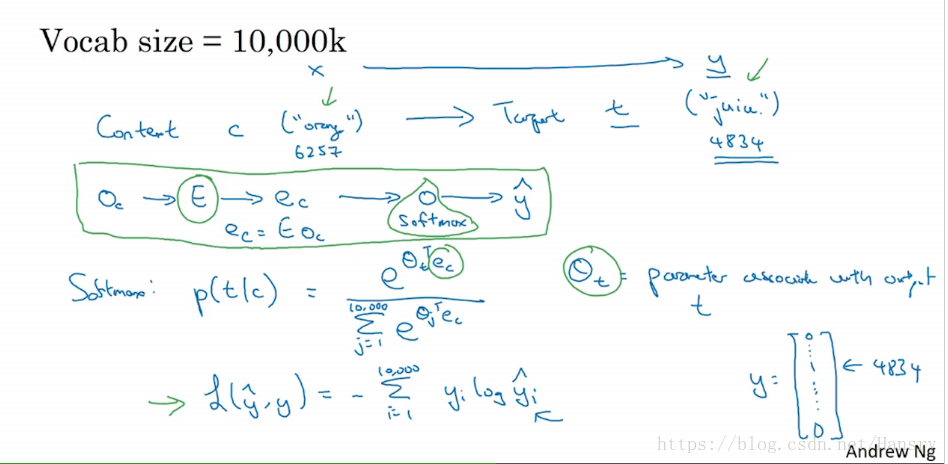
在这个模型中,首先最重要的是计算速度的问题(computational speed)
在 ,分母的求和是非常困难的,我们可以使用分级 , 类似于二叉树之类的。如下图左图所示,该 分类器告诉你预测的词在前5k个词还是后5k个词,依次类推。
但是在实际上,这个树不会是一个二叉树或者平衡树,经常使用的是将常用的词放在树的浅层部分,不常用的放在树的深处部分。
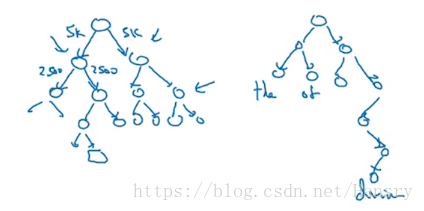
具体可见论文:“Mikolov et. al., 2013. Efficient estimation of word representations in vector space.”
7. 负采样(Negative sampling)
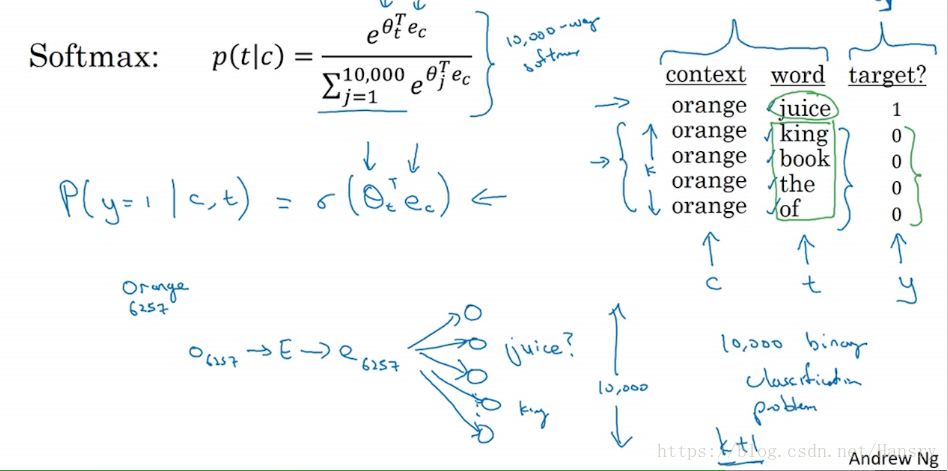
首先,跟上面所说的方式一样,我们可以给定一个上下文词(context word),例如orange,然后在一定词距内选择对应的词,例如 juice,然后标记 target 为 1。接着,在词典中随机选取 word, 例如king,然后将target标记为0。所以我们在训练过程中,输入的是context<->word (orange<->juice、orange<->king)等单词对,输出的是这俩个词之间的关系,即target的值,0或者1。
如下图所示,对于k的大小,文章作者推荐,数据集越大, k的值就越小,大概2-5左右。数据集越小,k的值就越大,大概5-20左右较好。
怎么学习从 x 映射到 y 呢?
在上一节的 Word2Vec 中,我们发现后面的分类器为Softmax分类器,其计算代价太高。而采样负采样(negative sample)后,假设k=4,我们只需要选取一个与context(这里是orange)对应的词(这里juice),然后其target 为1,再从字典中随机选取四个与orange不对应(一般情况下从字典随机选取是不对应的,当然刚好对应也是没有关系的)词(诸如king、book、the、of等),其target标记为0。 这样子就成了一个逻辑分类问题(Logistic classifier)。在每次迭代过程中从词典中虽然采样更新其负样本,从而训练其参数。
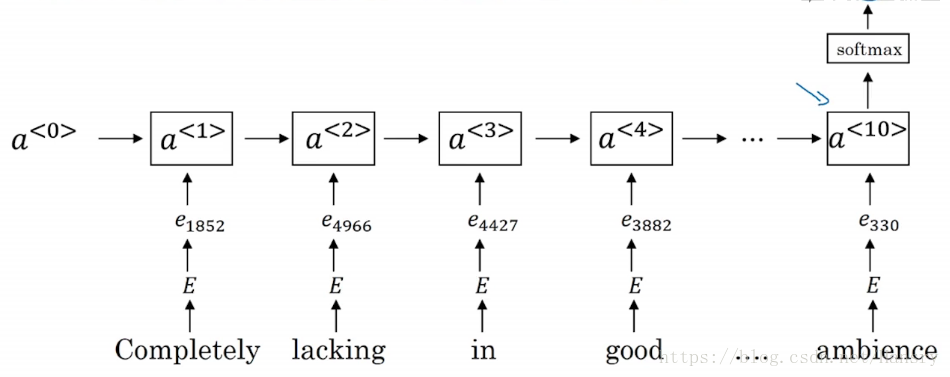
8.情绪分类(Sentiment classification)
情感分类任务就是看一段文本来分辨这个人是否喜欢他们在讨论的这个东西。

下面是一个简单的情感分类模型
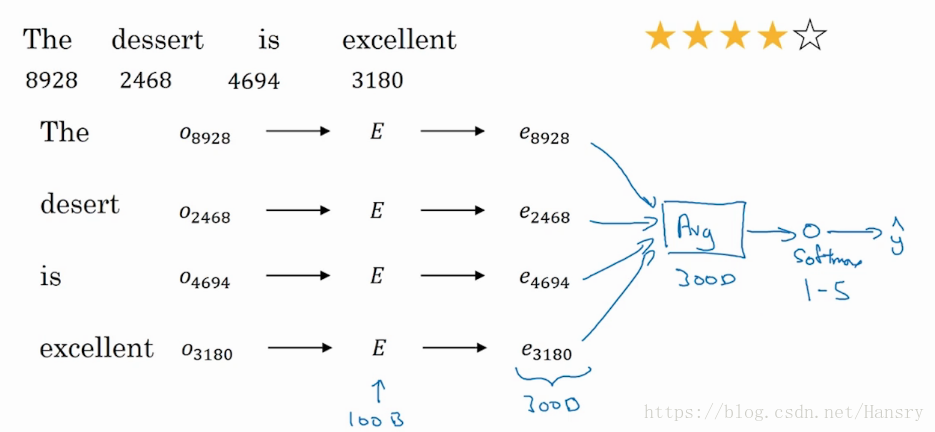
通过将句子中每个单词都写成o…o…one-hot 向量的形式,然后乘以一个词嵌入矩阵EE, 我们得到了词嵌入向量e…e…, 然后将所有的向量平均(average),输入到SoftmaxSoftmax最后得到y^y^。 但是有一个缺点就是忽略了词的顺序,这时候可以用RNN,如下图所示: