1、大概形式:
- 数值计算:numpy
- 数据处理分析:pandas
- 可视化:matplotlib/seaborn
- 机器学习:Sklearn/keras
- 交互:pygame
- 网络:Selenium等
2、第三方库的安装
先pip install +模块(下载安装模块),然后import + 模块,导入到你的.py模块中就可以了
大致流程如下:
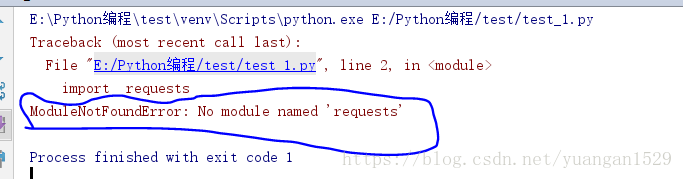
首先,你直接导入模块requests,会报错,因为你本地没有安装这个模块(有的import是可以的,因为Python自带的),然后你就要自己安装一下
注意:有的时候不是没有安装,而是Python版本不一样,因为Python2与Python3相差很大,所以网上档的代码运行时,报错很多家,其中就有模块错误,这不是安装没有安装的问题,而是版本错误
说一下解决方案,主要命令是:pip install requests
首先找到你的Python运行程序,具体位置就是:
也就是找到该文件夹下,如下:
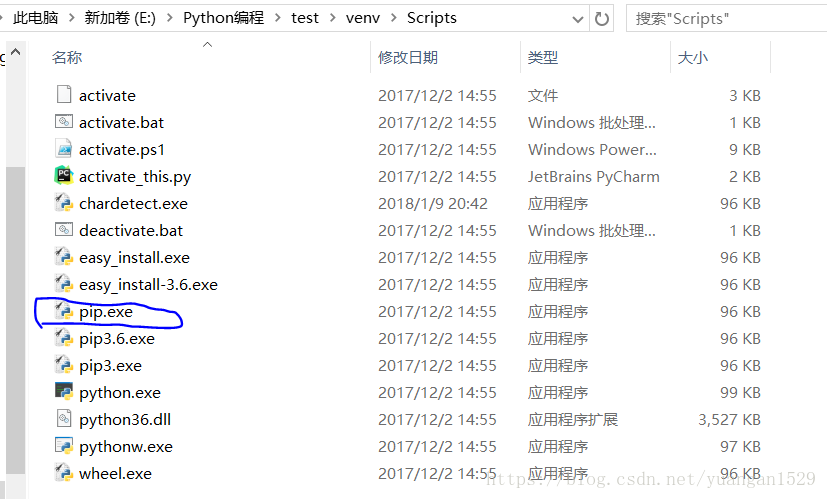
上图中,用蓝色圈勾中的区域就是你的命令要执行的软件,它是用来导入各种模块的。
具体命令如下(要在cmd命令窗口中):
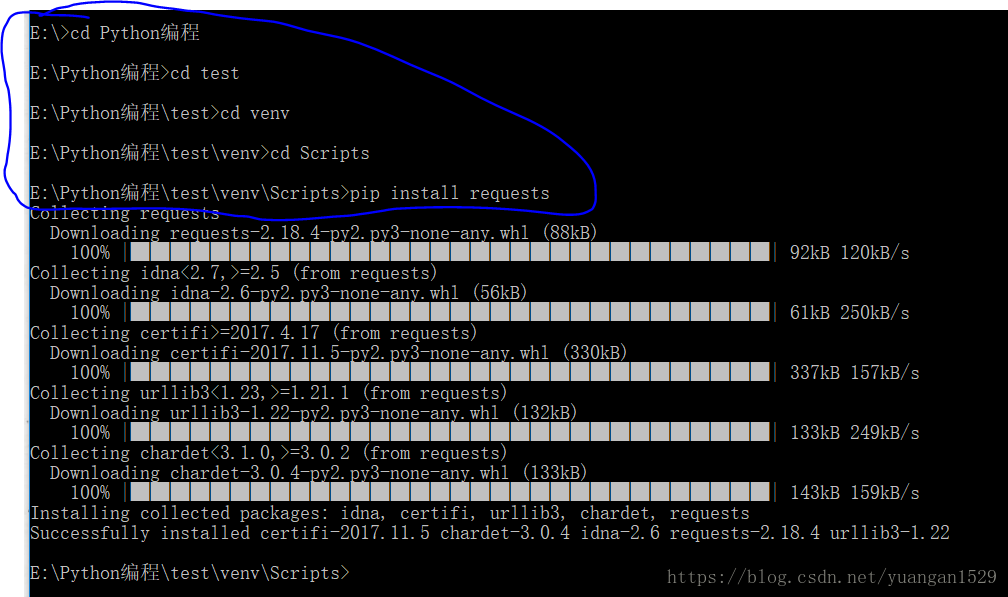
如上图所示,篮圈中就是所有命令了,先找到你的项目中的pip.exe文件,然后导入requests模块,接下来它就会自动下载你指定的模块了。
然后你再次运行就可以了!!!!!
注意:你要找的pip.exe文件是你运行项目中的文件,而不是PyCharm下的pip.exe文件,也不是Python中的pip.exe文件,这个问题一开始我没有找对,所以一直出错。
当然,除了上面这种方法,还可以自己下载相关模块文件,然后自己安装,不过这种方法就比较麻烦了,还消耗大量的时间(当然,有的时候这种pip方法安装不了,就需要这种笨方法),第二种方法这里就不再详细说了,网上一大堆,自己找吧
3、seaborn可视化
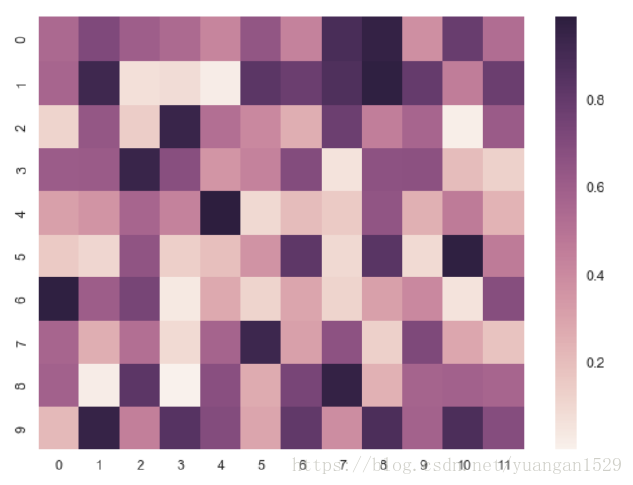
(1)热力图
import numpy as np #导入numpy模块,同时起个别名:np,这个别名业界也有名,大都默认了
import seaborn as sns #seaborn可视化第三方库
uniform_data = np.random.rand(10,12) #随机创建一个10行12列矩阵,每个元素是0-1的实数
ax = sns.heatmap(uniform_data) #热力图,三维图形用二维表示输出结果:
(2)散点图
import numpy as np #导入numpy模块,同时起个别名:np,这个别名业界也有名,大都默认了
import seaborn as sns #seaborn可视化第三方库
sns.set(color_codes = True)
tips = sns.load_dataset("tips") #这里tips是一个内置的数据集,两列:tip和total_bill数据
g = sns.lmplot(x = "total_bill",y = "tip",data = tips) #开始根据数据集画图,设置X/Y轴,然后设置数据集输出结果:

上面就是根据数据集画出来的,不仅给出了散点图,还给出了最佳拟合回归函数(那个直线),还有一个置信度区间(阴影区域部分,表示拟合回归函数的大致可能范围)——当然一个最大的问题是我不知道这个图片怎么显示出来啊,折腾了半天,也没有搞定
(3)其他语言的可视化库
- R语言:SSDcot
- JavaScript:D3.JS
- Python:seaborn、matplotlib
4、SKLearn(机器学习库)
(1)使用的三大步骤
#第一步:得到数据集,其中train开头的是训练集,而test开头的是测试集,x—输入,y—输出
train_x, train_y, test_x, test_y = getData()
#第二步:
model = somemodel() #这里的somemodel取决于你用什么模型,如果用SVM,这里就写出SVM()
model.fit(train_x,train_y) #通过训练集来进行训练,主要步骤就是这一步,耗费大部分时间
predictions = model.predict(test_x) #模型训练好了以后,要进行测试,给出test_x,会返回一个预测值
#第三步:进行评分
score = score_function(test_y,predictions)当然,上面给出的是伪代码,不是真正的详细的代码
(2)举一个例子

常用的一个数据集是兰花lris数据集,一共150行数据,每一行4个特征数据,输入是一个150*4的矩阵,输出是一个150*1的数据